原理介绍
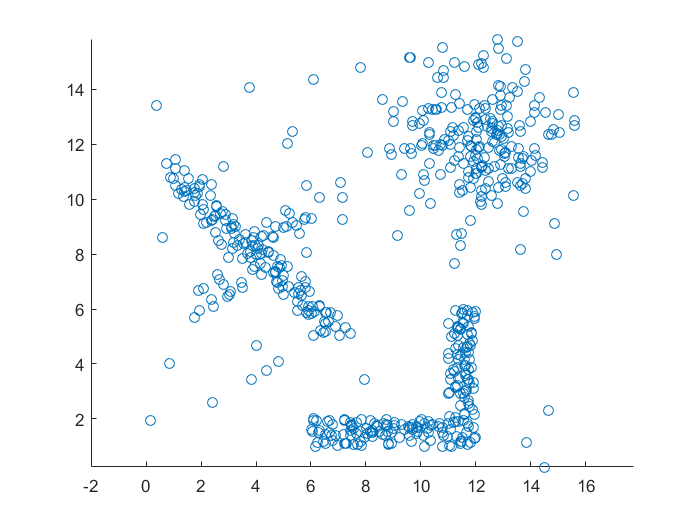
Data Set:对于机器学习领域来说,数据集的选择是至关重要的,一个数据集的好坏往往可以直接决定聚类结果,通常一个算法很难适用于所有的数据集。因此我们需要设计各种数据集,并且分析哪一种数据类型适合用哪一种算法,只有这样,在今后的使用中才能得心应手。考虑到数据集的适应性,设计了以下五种不同的数据集,包括水平竖直型数据,斜线型数据,圆形数据,高斯型数据和混合型数据。
代码实战
line_data.m
1 | clear;clc;close all; |
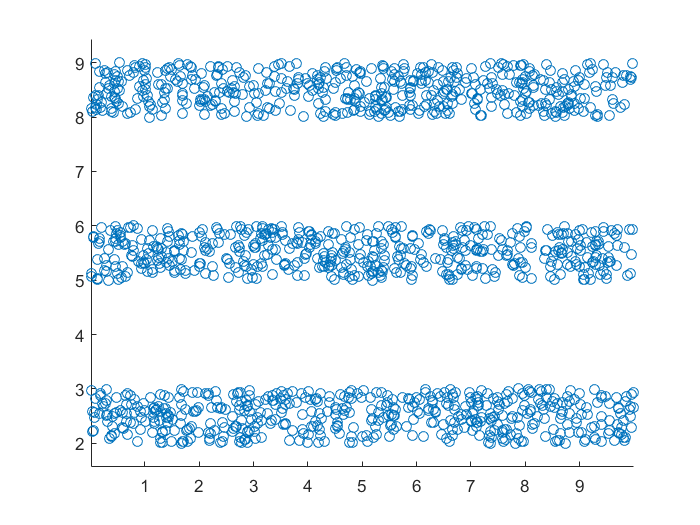
slash_data.m
1 | clear;clc;close all; |
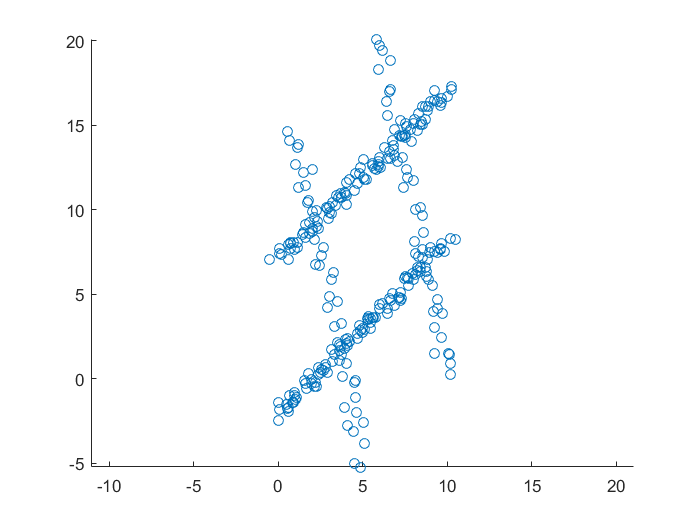
gauss_data.m
1 | clear;clc;close all; |
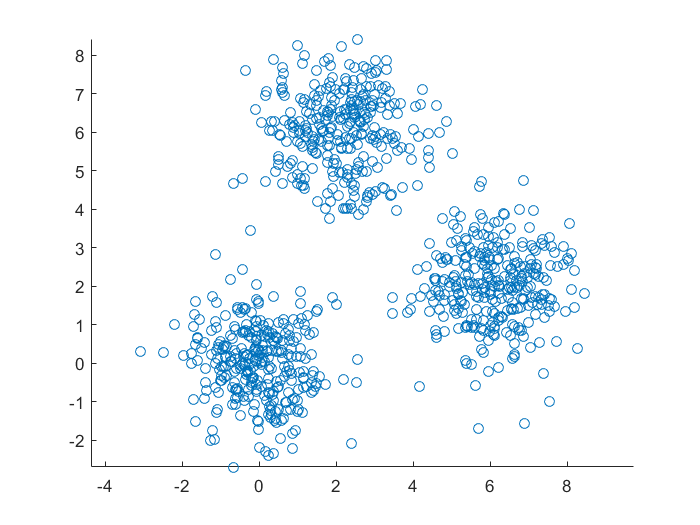
cicle_data.m
1 | clear;clc;close all; |
mixture_data.m
由上面的四种数据集组合之后可以形成混合数据集。
1 | clear;clc;close all; |