原理解读
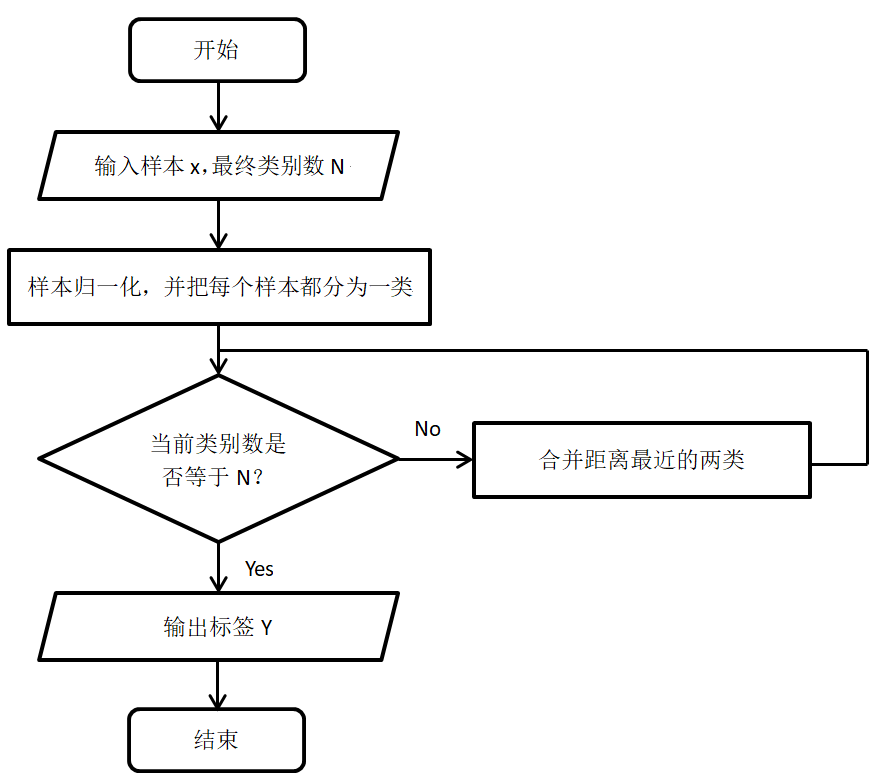
AGNES(Agglomerative Nesting):采用自底向上的策略,最初将每个对象作为一个类,然后根据某些准则将这些类别逐一合并。合并的过程反复进行直到类别达到预期的数目。
核心思想
1. 将每一个样本都单独作为一类
2. 合并两类(多种定义方法),直到满足某个终止条件
最小距离:将两个类别之间最近的两个样本之间的距离作为两个类别之间的距离
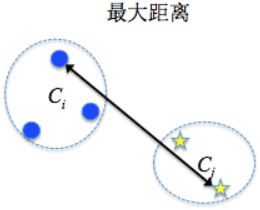
$$d_{min}=\underset{x_i \in C_i,x_j \in C_j}{min}d(x_i,x_j)$$最大距离:将两个类别之间最远的两个样本之间的距离作为两个类别之间的距离
$$d_{max}=\underset{x_i \in C_i,x_j \in C_j}{max}d(x_i-x_j)$$

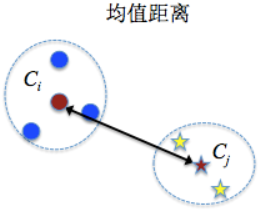
均值距离:将两个类别中样本的平均值之间的距离作为两个类别之间的距离
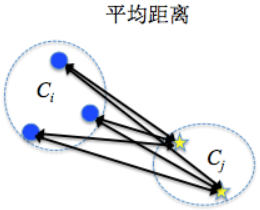
$$d_{mean}=d(\overline {C_i}- \overline {C_j}) \ , \ 其中\overline {C_i}=\frac {1}{\lvert C_i \rvert}\underset{x_i \in C_i}{\sum}{x_i}$$平均距离:将两个类别中样本间两两距离的平均值作为两个类别之间的距离
$$d_{avg}=\frac {1}{\lvert C_i \rvert \lvert C_j \rvert}\underset{x_i \in C_i}{\sum}\underset{x_j \in C_j}{\sum}d(x_i-x_j)$$
算法流程
代码实战
代码中所用数据集可以查看相关文档,数据集(Data Set)
AGNES_main.m
1 | clear;clc;close all; |
AGNES_classify.m
1 | function [y,class_center]=AGNES_classify(x_scale,sample_num,class_num) |
AGNES_display.m
1 | function AGNES_display(x,y,class_center,sample_num,class_num) |
实验结果
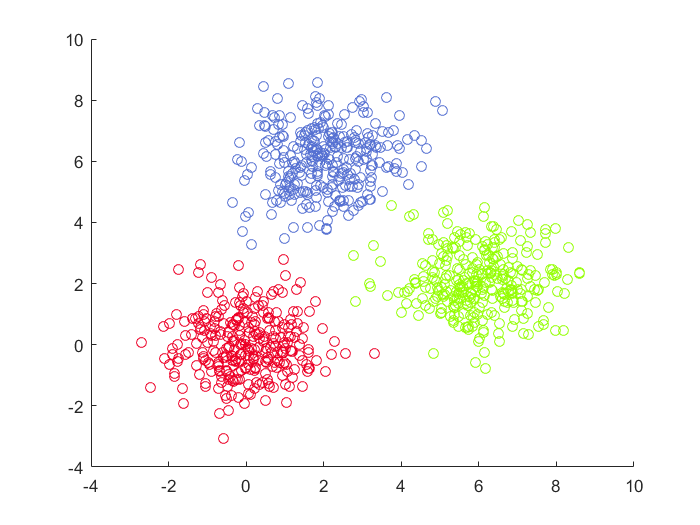
性能比较
- 优点:
- 对噪声数据不敏感
- 算法简单,容易理解
- 不依赖初始值的选择
- 对于类别较多的训练集分类较快
- 缺点:
- 合并操作不能撤销
- 需要在测试前知道类别的个数
- 对于类别较少的训练集分类较慢
- 只适合分布呈凸型或者球形的数据集
- 对于高维数据,距离的度量并不是很好