原理解读
CFDP(Clustering By Fast Search And Find Of Density Peaksd):经典的聚类算法K-means不能检测非球面类别的数据分布,DBSCAN必须指定一个密度阈值,CFDP通过对两种方法的改善,选择每个区域密度最大值,根据密度选择周围点的归属。
核心思想
1. 求出每个点的密度ρi(多种定义方法)
- k近邻均值倒数
$$\rho_i = \frac{k}{\displaystyle \sum_{j=1}^k d_{ij}} \ , \ d_{i1} \leq d_{i2} \leq \cdots \leq d_{in}$$ - 高斯核相似度
$$\rho_i = \underset{d_{ij} \leq d_c}{\sum}exp[-(\frac{d_{ij}}{d_c})^2]$$ - 周围点的个数
$$\rho_i = \sum_{j=1}^n {\chi(d_{ij}-d_c)} \ , \ \chi(x)= \begin{cases} 1, & x<0 \[2ex] 0, & otherwise \end{cases} \ , \ 其中d_c为截断距离$$
2. 密度从大到小排序,并求出最大密度ρmax
$$\rho_{x_1} \ge \rho_{x_2} \ge \cdots \ge \rho_{x_n} \ , \ \rho_{max} = \rho_{x_1} $$
- dij:原序列i,j样本的距离
- d(xi,xj):密度排序后,xi和xj样本的距离
3. 求出每个点的距离δi
δi:到密度大于i的最近点j的距离dist(ij)
$$\delta_{x_i} = \begin{cases} \underset{j<i}{min}\ d(x_i,x_j) & i \ge 2 \[2ex] \underset{j \ge 2}{\max}\ \delta_{x_j} & i=1 \end{cases} $$
4. 画出ρ-δ图,找到离群点(代表每一类的中心)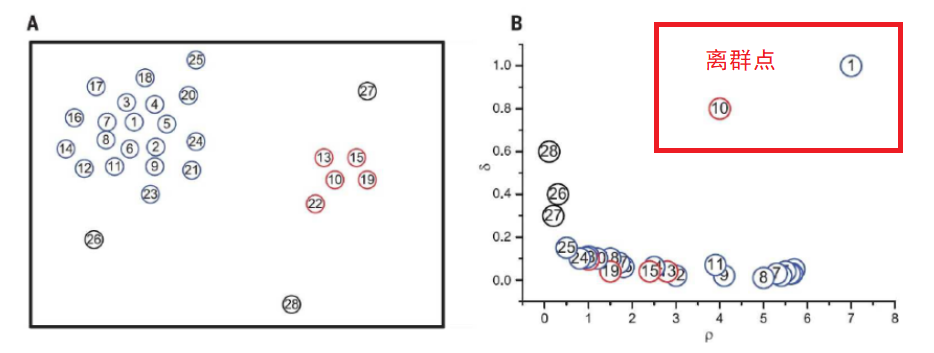
5. 按密度从大到小归属于距离最近点的类别
$$x_i \in C_k \ , \ 其中k=\underset{j<i \ , \ x_j \in C_k}{arg \ min}\ d(x_i,x_j)$$
6. 定义两类之间的最小距离d0
两类的最小距离:所有样本之间距离从小到大排序后第2%个称两类的最小距离。
7. 定义边缘点,求出边缘点最大密度ρb
边缘点:在k类数据到非k类数据的最小距离小于dist0的点,称为k类数据的边缘点。
$$E = {i | d_{ij}<dist_0 , \forall i \in C_k , j \in \overline{C_k} }$$
$$\rho_b = \underset{i \in E}{\max}\ \rho_i$$
8. 判断噪声点
噪声点:将k类中密度小于ρb的所有数据记为噪声。
$$N={i | \rho_i<\rho_b , \forall i \in C_k }$$
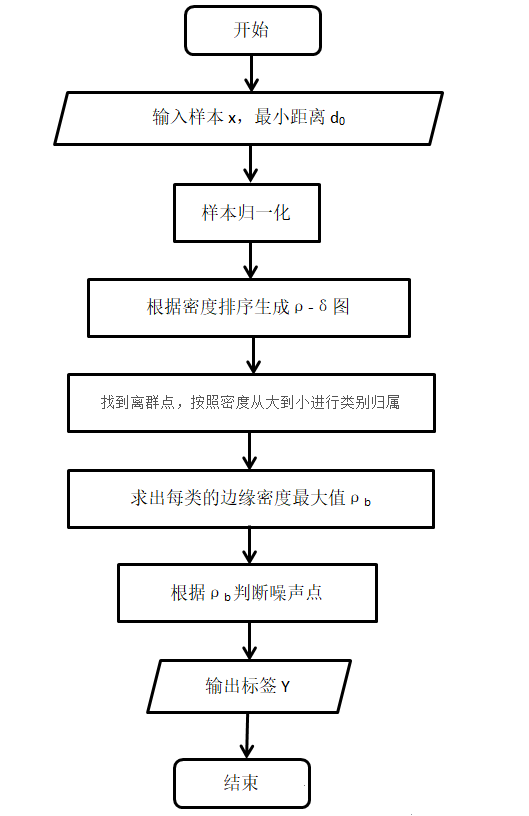
算法流程
代码实战
代码中所用数据集可以查看相关文档,数据集(Data Set)
CFDP_main.m
1 | clear;clc;close all; |
CFDP_classify.m
1 | function [y,density_max]=CFDP_classify(x_scale,sample_num,k) |
CFDP_display.m
1 | function CFDP_display(x,y,sample_num,density_max) |
实验结果
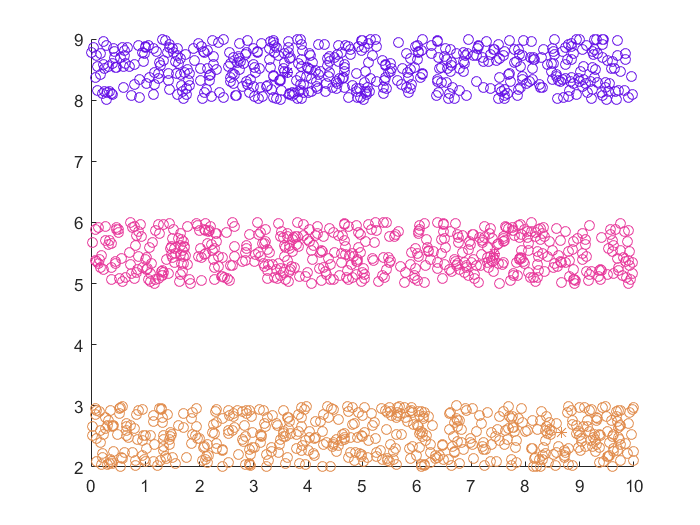
性能比较
- 优点:
- 对噪声数据不敏感
- 不依赖初始数据点的选择
- 可以完成任意形状的聚类
- 缺点:
- 离群点的确定非常复杂
- 算法复杂,分类速度较慢
- 对于高维数据,距离的度量并不是很好
- 不适合数据集整体密度基本相同的情况