原理解读
GMM(Gaussian Mixture Model,):是一个将事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型,混合高斯分布( MoG )由多个混合成分组成,每一个混合成分对应一个高斯分布。当聚类问题中各个类别的尺寸不同、聚类间有相关关系的时候,往往使用 MoG 更合适。对一个样本来说, MoG 得到的是其属于各个类的概率(通过计算后验概率得到),而不是完全的属于某个类,这种聚类方法被成为软聚类。一般说来, 任意形状的概率分布都可以用多个高斯分布函数去近似,因而,MoG 的应用也比较广泛。
步骤分析
1. 选择高斯模型个数K,初始化参数
2. 根据贝叶斯定理,求出zj的后验分布概率
$$p(z_j=i | x_j) = \frac{\alpha_i \cdot p(x_j | \mu_i , \Sigma_i)}{\displaystyle \sum_{l=1}^k \alpha_l \cdot p(x_j | \mu_l , \Sigma_l)}$$
3. 使用EM算法进行迭代
计算均值向量:
$$\mu_i ‘=\frac{\displaystyle \sum_{j=1}^m p(z_j=i | x_j) \cdot x_j}{\displaystyle \sum_{j=1}^m p(z_j=i | x_j)}$$计算协方差矩阵:
$$\Sigma_i ‘=\frac{\displaystyle \sum_{j=1}^m p(z_j=i | x_j) \ (x_j - \mu_i ‘) \ (x_j - \mu_i ‘)^T}{\displaystyle \sum_{j=1}^m p(z_j=i | x_j)}$$计算混合系数:
$$\alpha_i ‘=\frac{\displaystyle \sum_{j=1}^m p(z_j=i | x_j)}{m}$$
4. 重复步骤1,2,直到满足某个终止条件
5. 定义高斯混合分布
根据所求得的均值向量,协方差矩阵和混合系数可以定义如下函数:
$$p(x)=\displaystyle \sum_{l=1}^k \alpha_i \cdot p(x | \mu_i , \Sigma_i) \ , \ s.t. \displaystyle \sum_{l=1}^k \alpha_i=1$$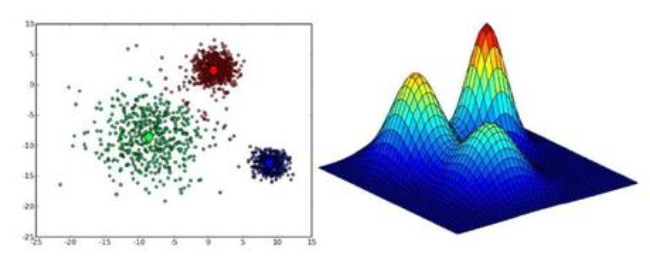
6. 对样本进行标记
$$\lambda_j=\underset{i \in { 1,2, \cdots ,k}}{arg\ max} \ p(z_j=i | x_j)$$
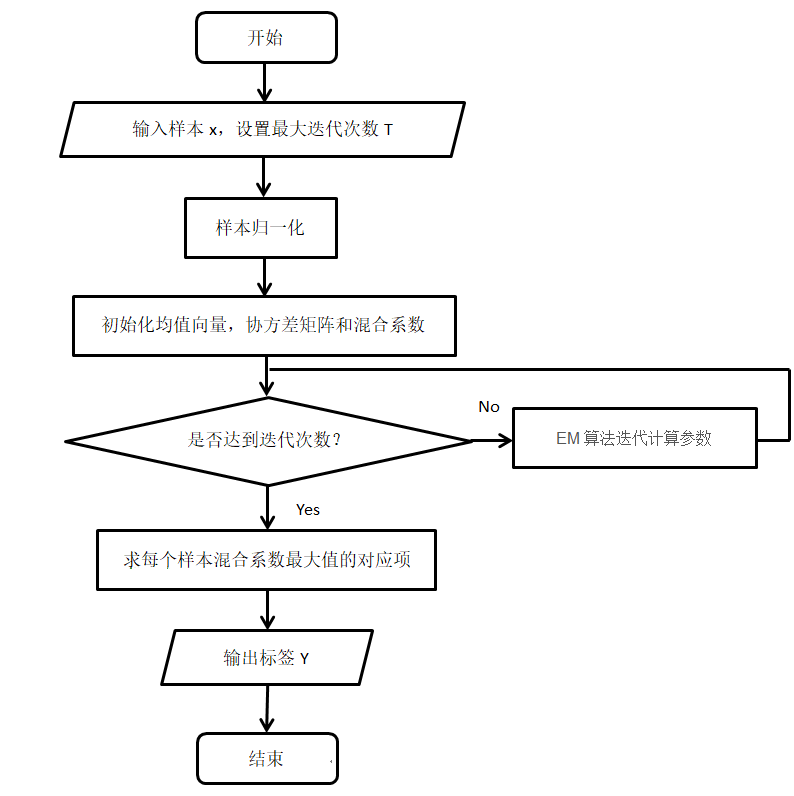
算法流程
代码实战
代码中所用数据集可以查看相关文档,数据集(Data Set)
GMM_main.m
1 | clear;clc;close all; |
GMM_classify.m
1 | function y=GMM_classify(x_scale,sample_num,class_num,feat_num) |
GMM_display.m
1 | function GMM_display(x,y,sample_num,class_num) |
实验结果
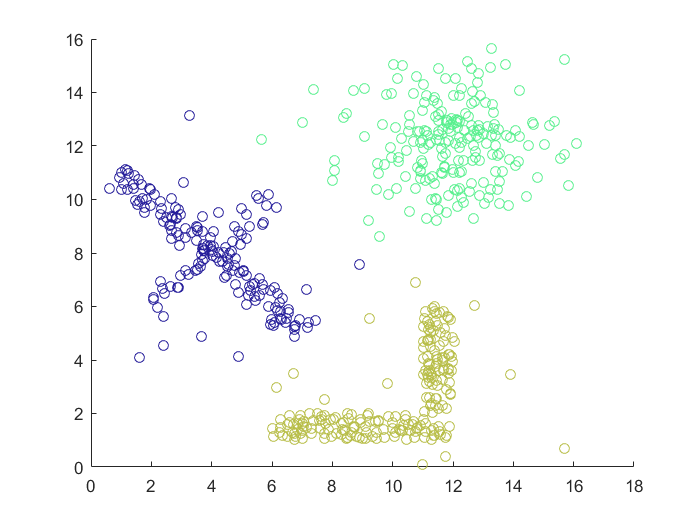
性能比较
- 优点:
- 可以完成大部分形状的聚类
- 大数据集时,对噪声数据不敏感
- 对于距离或密度聚类,更适合高维特征
- 缺点:
- 计算复杂,速度较慢
- 难以对圆形数据聚类
- 需要在测试前知道类别的个数
- 初始化参数会对聚类结果产生影响