原理解读
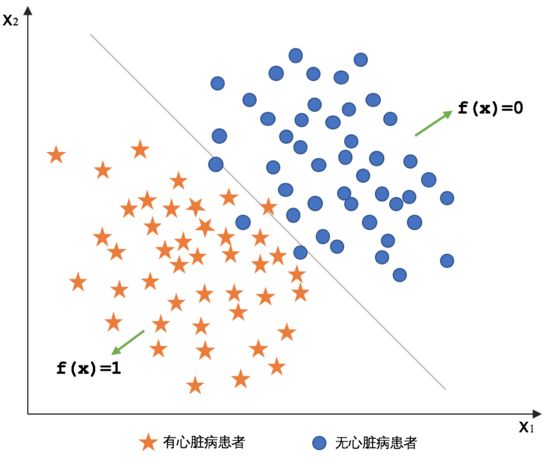
逻辑回归(Logistics Regression):是一种广义线性回归,都具有 w’x+b,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w’x+b作为因变量,即y =w’x+b,而logistic回归则通过函数g将w’x+b对应一个隐状态p,p =g(w’x+b),然后根据p 与1-p的大小决定因变量的值。如果g是logistic函数,就是logistic回归。
核心思想
预测函数
对于二分类问题,$y \in \lbrace 0,1 \rbrace$,1表示正例,0表示负例。逻辑回归是在线性函数$W^Tx$输出预测实际值的基础上,寻找一个假设函数函数$h_W(x)=g(W^Tx)$,将实际值映射到到0,1之间,如果
$$y =\begin{cases} 1 & h_W(x) \ge 0.5 \ 0 & h_W(x) <0.5 \end{cases}$$
逻辑回归中选择对数几率函数(logistic function)
$$g(z)=\frac{1}{1+e^(-z)}$$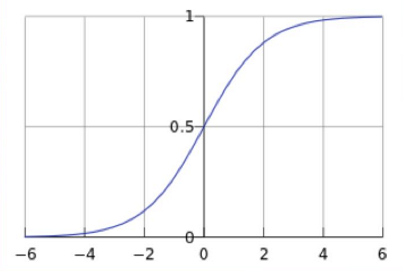
有一个非常重要的性质,可以方便我们的计算。
$$g(z)’=g(z) \cdot (1 - g(z))$$
损失函数
我们假设
$$ \begin{cases}P(Y=1|X) = p(x) \ P(Y=0|X) = 1 - p(x) \end{cases} $$
根据极大似然估计可知
$$ \hat{w} = \underset{w}{argmax} \ L(w) = \underset{w}{argmax} \prod_{i = 1}^{N} [p(x_i)]^{y_i} \cdot [1 - p(x_i)]^{1 - y_i} $$
两边同时取对数,计算对数似然函数。
$$ \hat{w} = \underset{w}{argmax} \ ln(L(w)) = \underset{w}{argmax} \sum_{i = 1}^{N} [y_i \cdot ln(p(x_i)) + (1 - y_i) \cdot ln(1 - p(x_i))]$$
因为我们在计算时常常求最小值,因此我们设计损失函数,令$J(w) = -\frac{1}{N} ln(L(w))$
$$ \hat{w} = \underset{w}{argmin} \ J(w)=-\frac{1}{N} \underset{w}{argmax} \ ln(L(w))$$
$$ \hat{w} = -\underset{w}{argmin} \frac{1}{N} \sum_{i = 1}^{N} [y_i \cdot ln(p(x_i)) + (1 - y_i) \cdot ln(1 - p(x_i))]$$
下面转化为求$\underset{w}{argmin} \ J(w)$,使用常见的梯度下降法进行求解。
$$ g_i = \frac{\partial J(w)}{\partial w_i} = (p(x_i) - y_i) \cdot x_i $$
$$ w_i^{k + 1} = w_i^k - \alpha \cdot g_i$$
代码实战
LR_train.m
1 | clear;clc; |
LR_test.m
1 | close all; |
实验结果
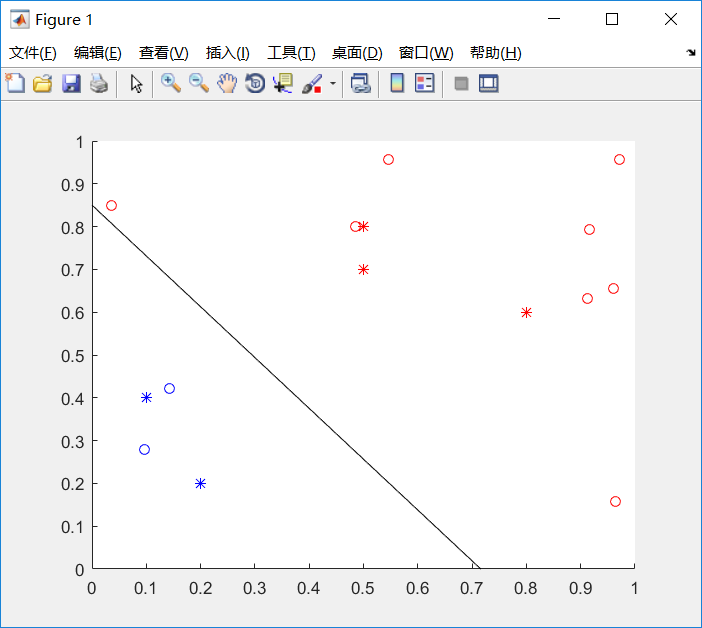
性能比较
- 优点:
- 算法简单,容易理解
- 适合于大多数线性分类的任务
- 鲁棒性较好,能够抵挡轻微噪声的影响
- 缺点:
- 容易欠拟合
- 在多分类任务或者非线性任务上难以使用
- 特征空间较大或者特征缺失情况下表现较差