
Pandas介绍
pandas是基于Numpy的一种工具,该工具纳入了大量库和一些标准的数据模型,提供了大量能使我们快速便捷地处理数据的函数和方法。
Pandas特点
Pandas解决了Numpy不利于处理数据结构的问题
Pandas能够合并处理常见数据库中的关系型运算
Pandas更贴近于日常的生活使用,即表格化的数据形式
Pandas具备数据对齐功能,且集成时间序列,既能处理时间序列数据,也能处理非时间序列数据
Pandas应用
Pandas创建表格
series方法
1 | import pandas as pd |
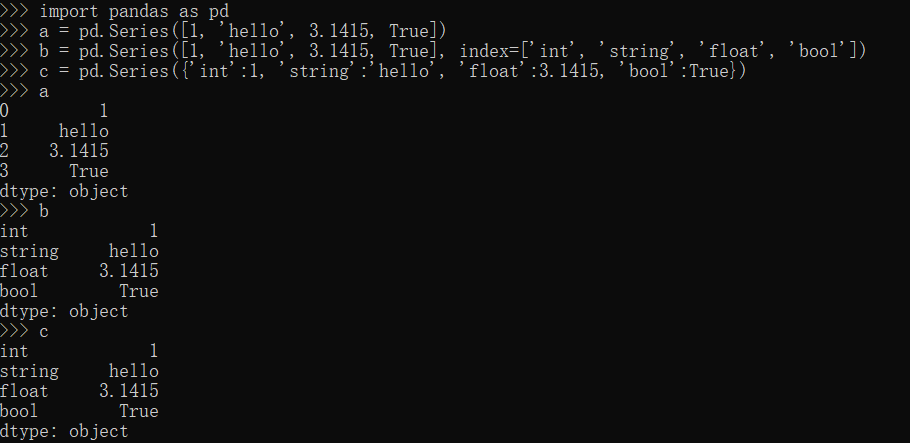
DataFrame方法
1 | import pandas as pd |

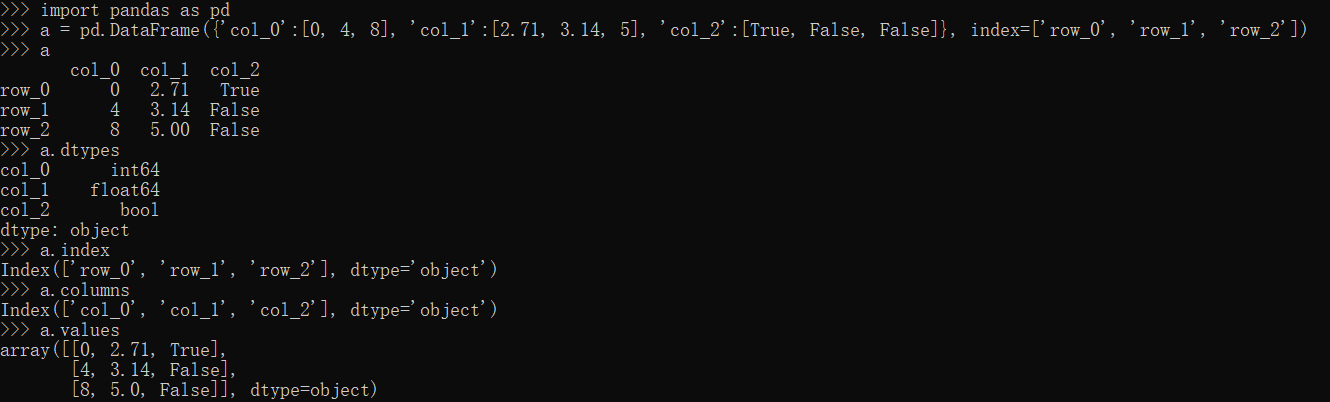
Pandas属性
dtypes,index,columns,values属性
1 | import pandas as pd |
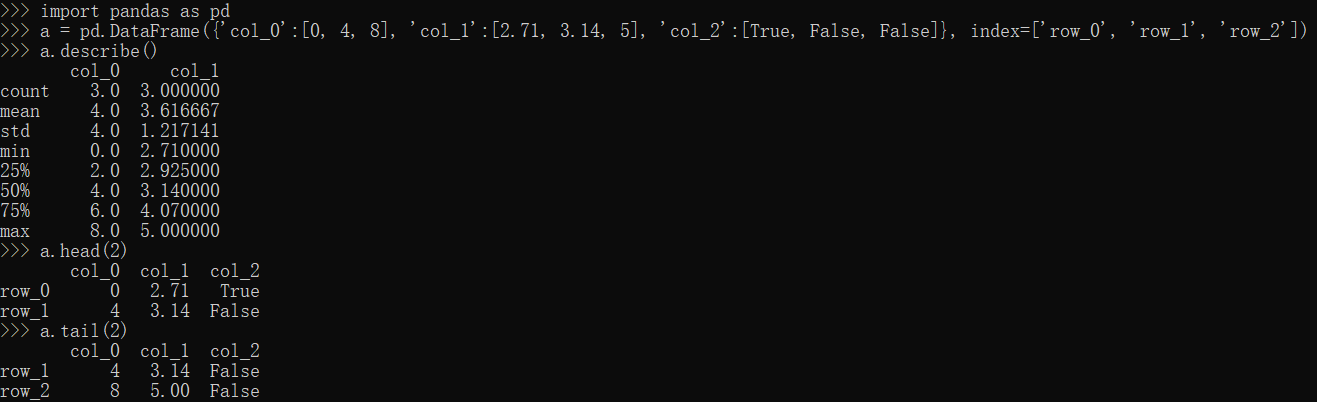
describe,head,tail属性
1 | import pandas as pd |
Pandas表格排序
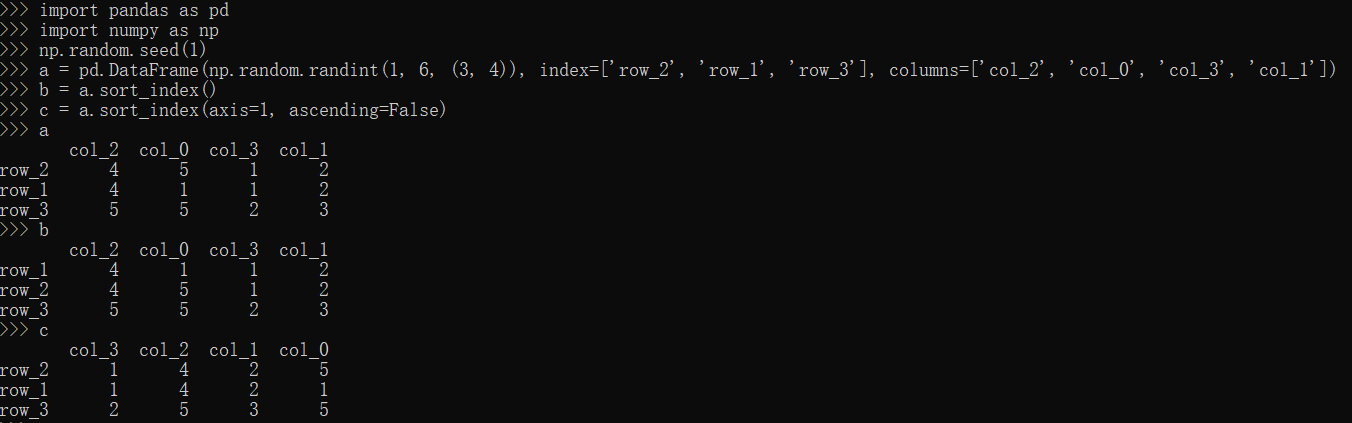
sort_index方法
1 | import pandas as pd |
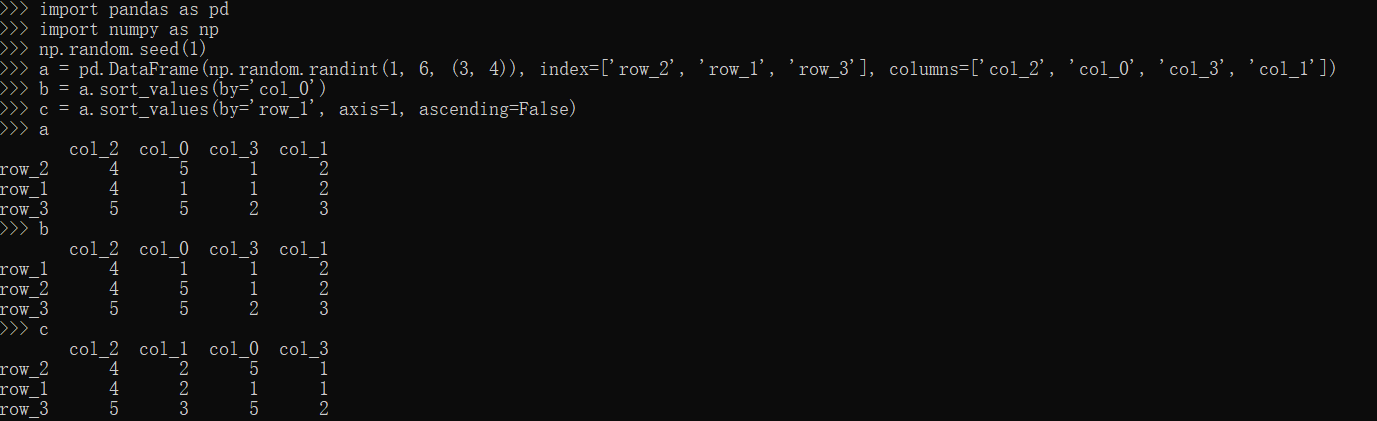
sort_values方法
1 | import pandas as pd |
pandas切片与索引
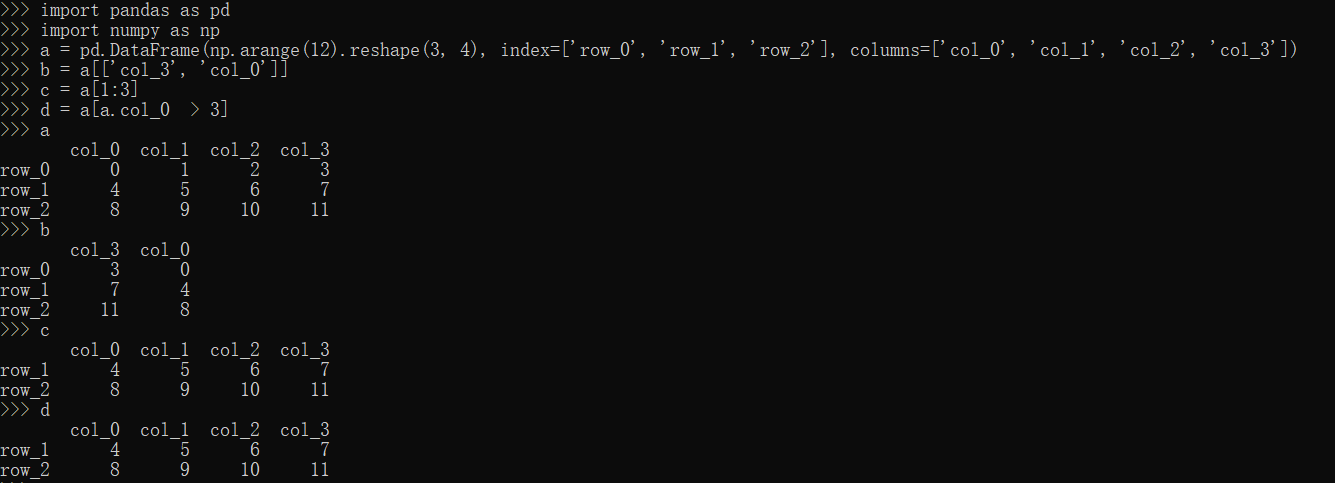
[]方法
1 | import pandas as pd |
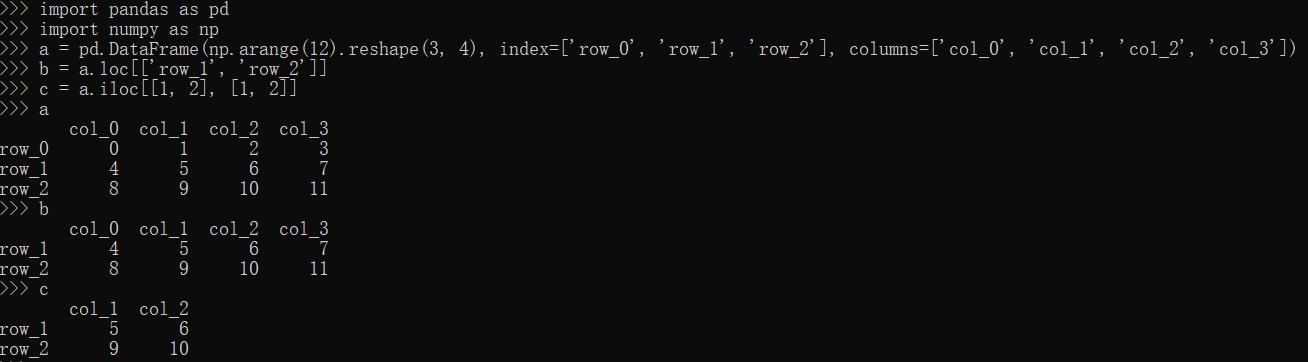
loc,iloc方法
1 | import pandas as pd |
pandas修改内容
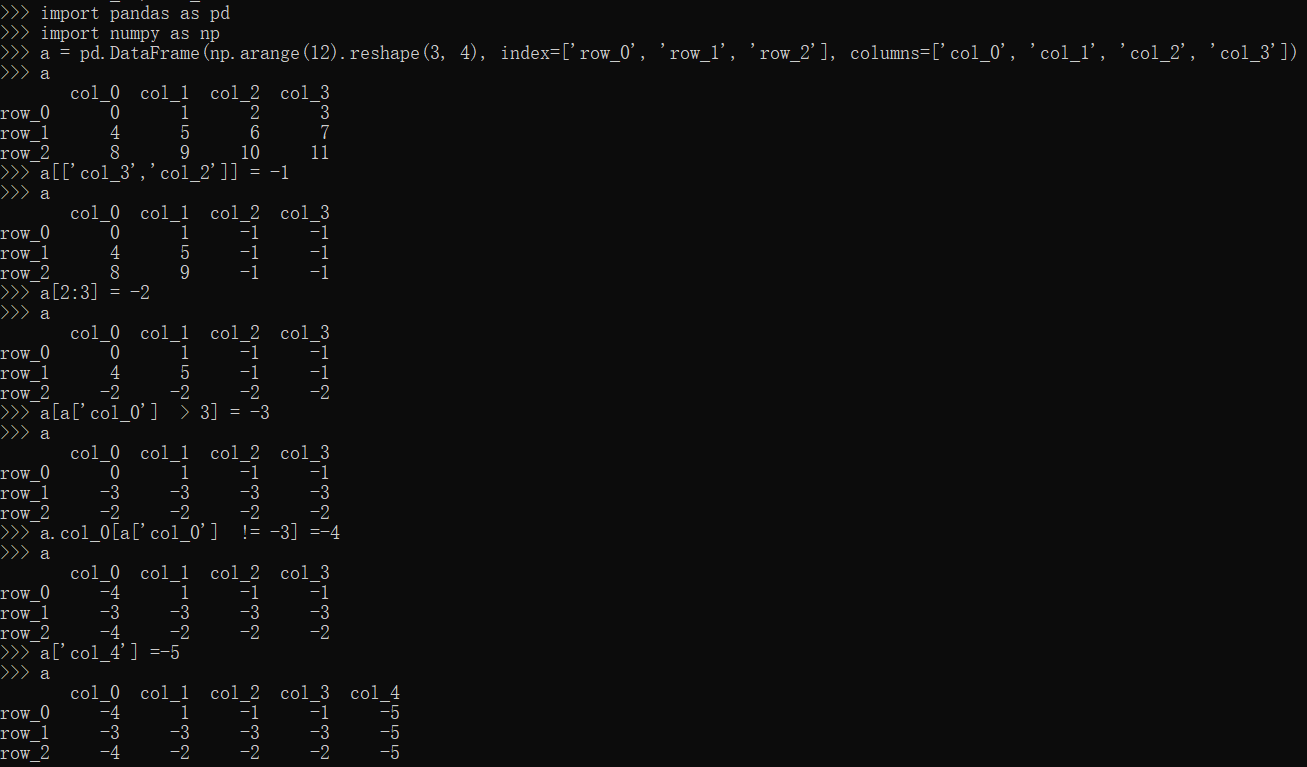
[]方法
1 | import pandas as pd |
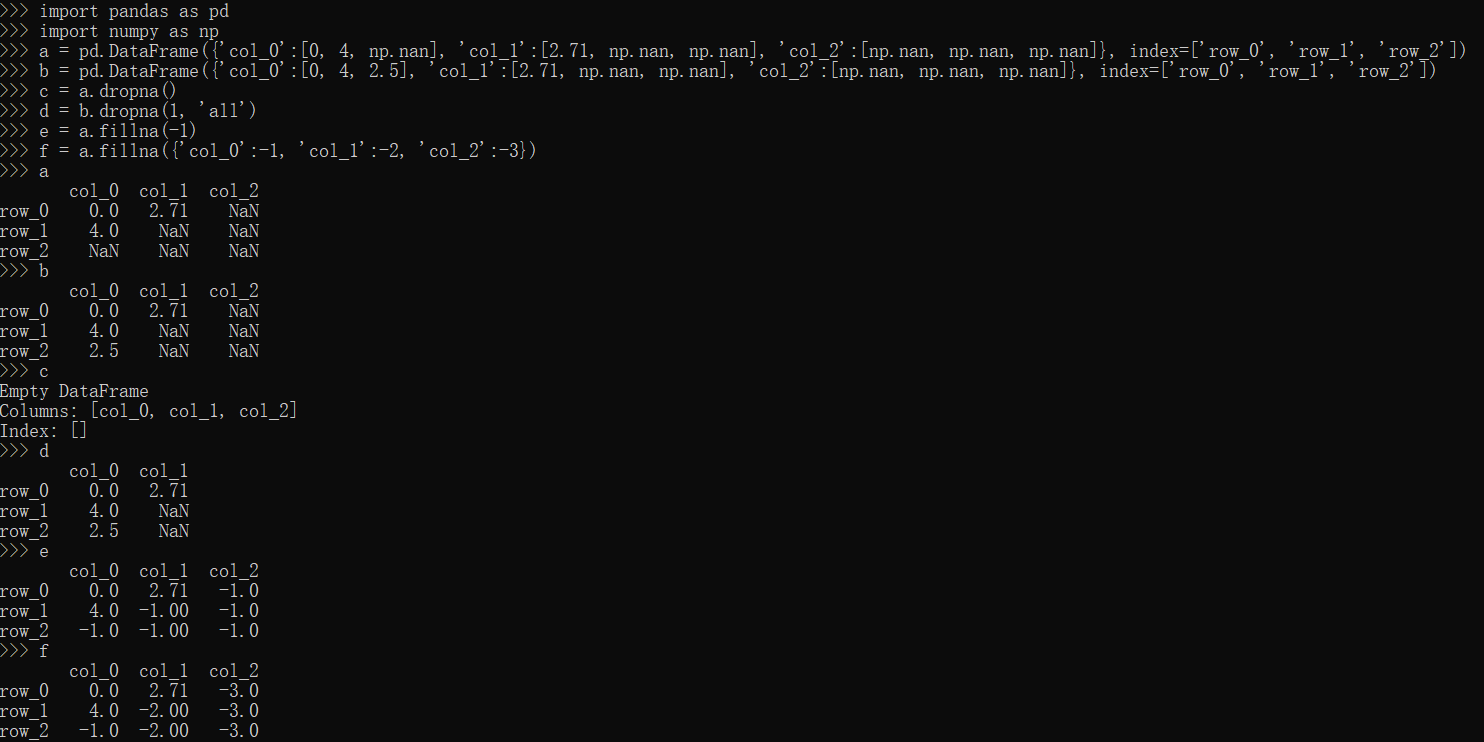
dropna,fillna方法
1 | import pandas as pd |
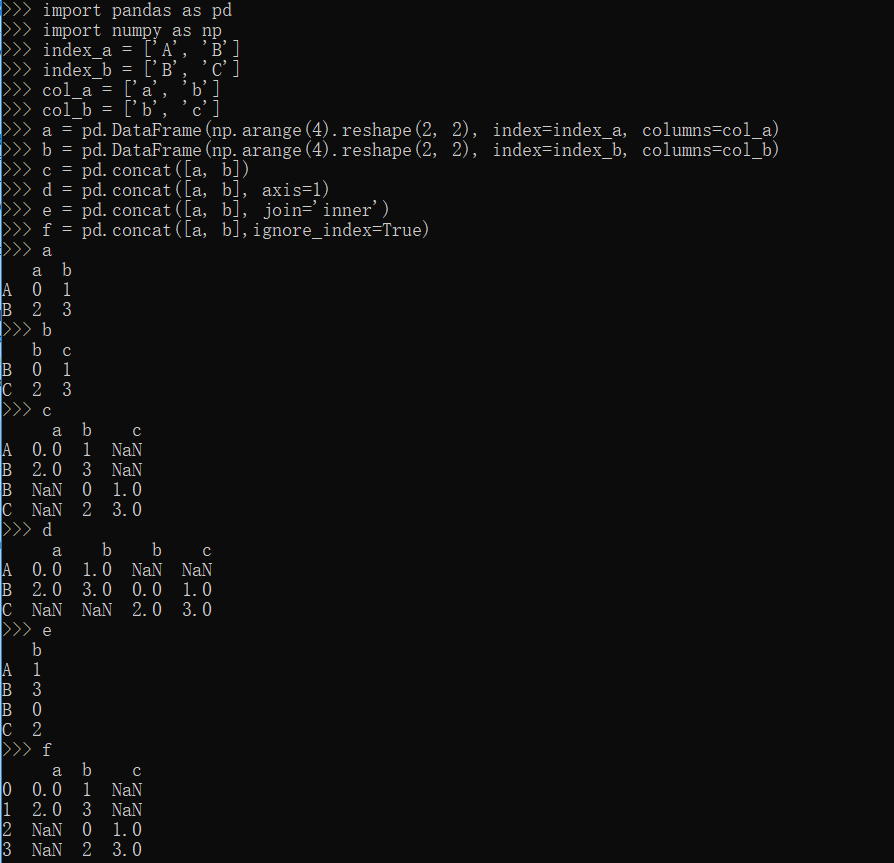
pandas合并
concat方法
1 | import pandas as pd |
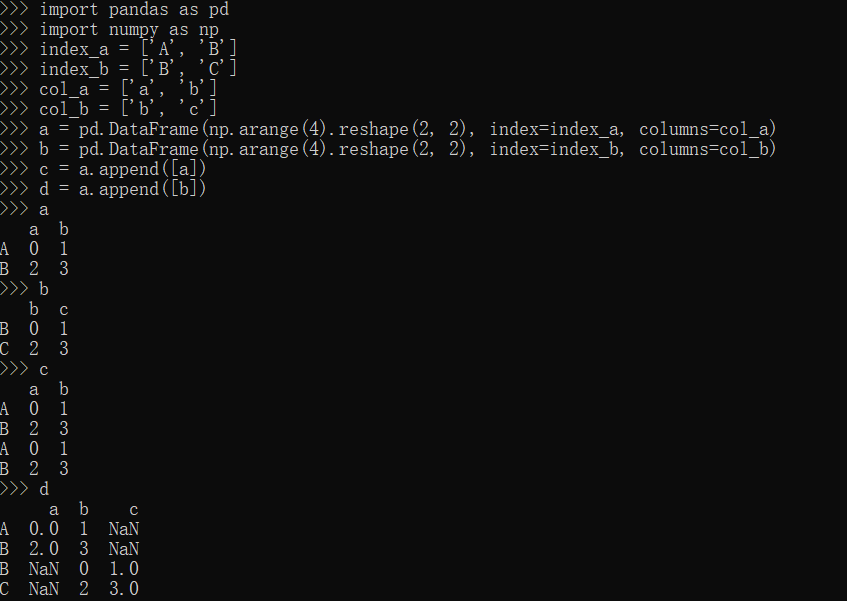
append方法
1 | import pandas as pd |
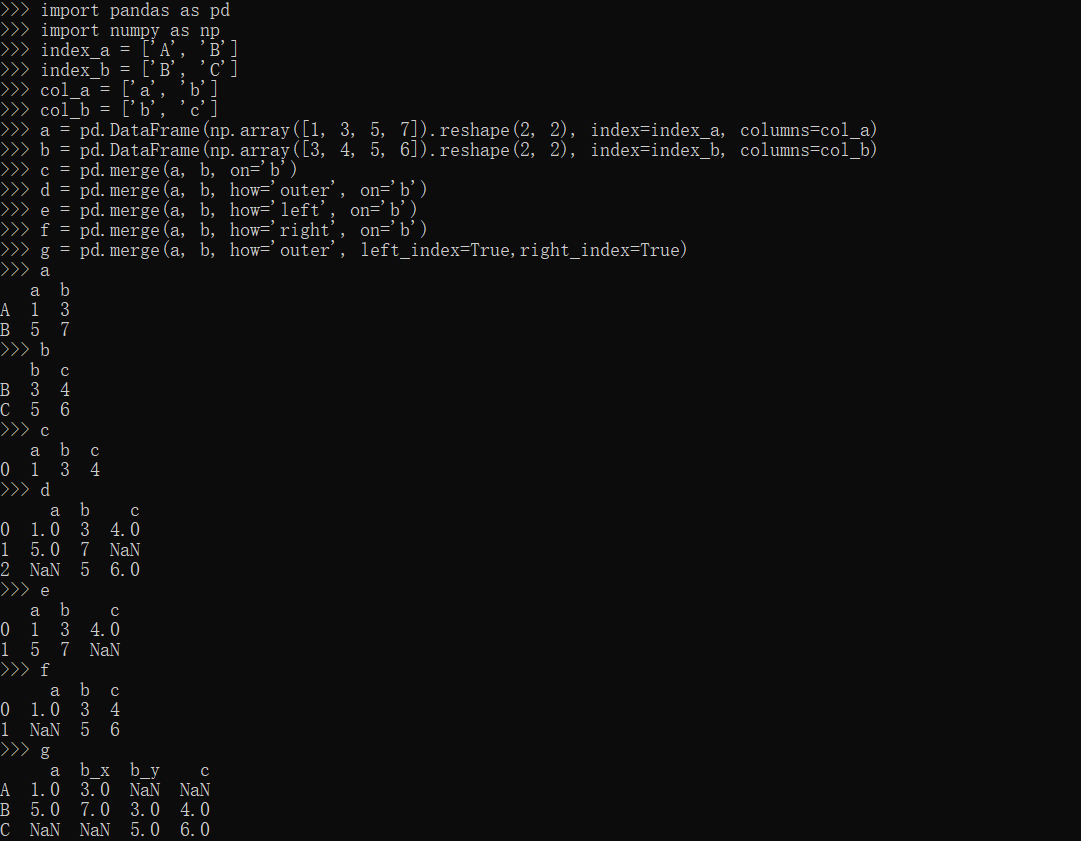
merge方法
1 | import pandas as pd |
Pandas修改行列名
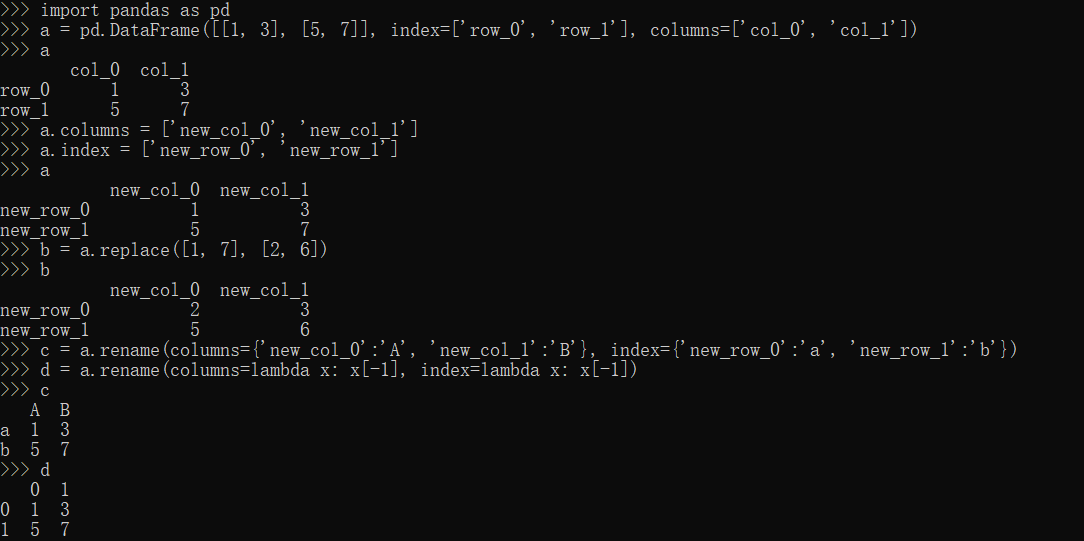
replace,rename方法
1 | import pandas as pd |
pandas数理统计
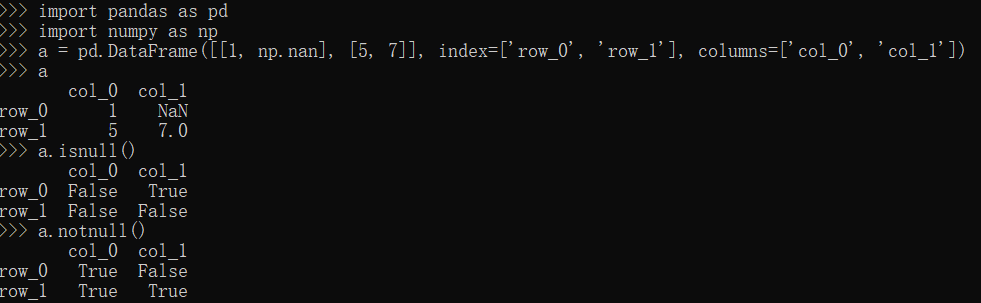
notnull,isnull方法
1 | import pandas as pd |
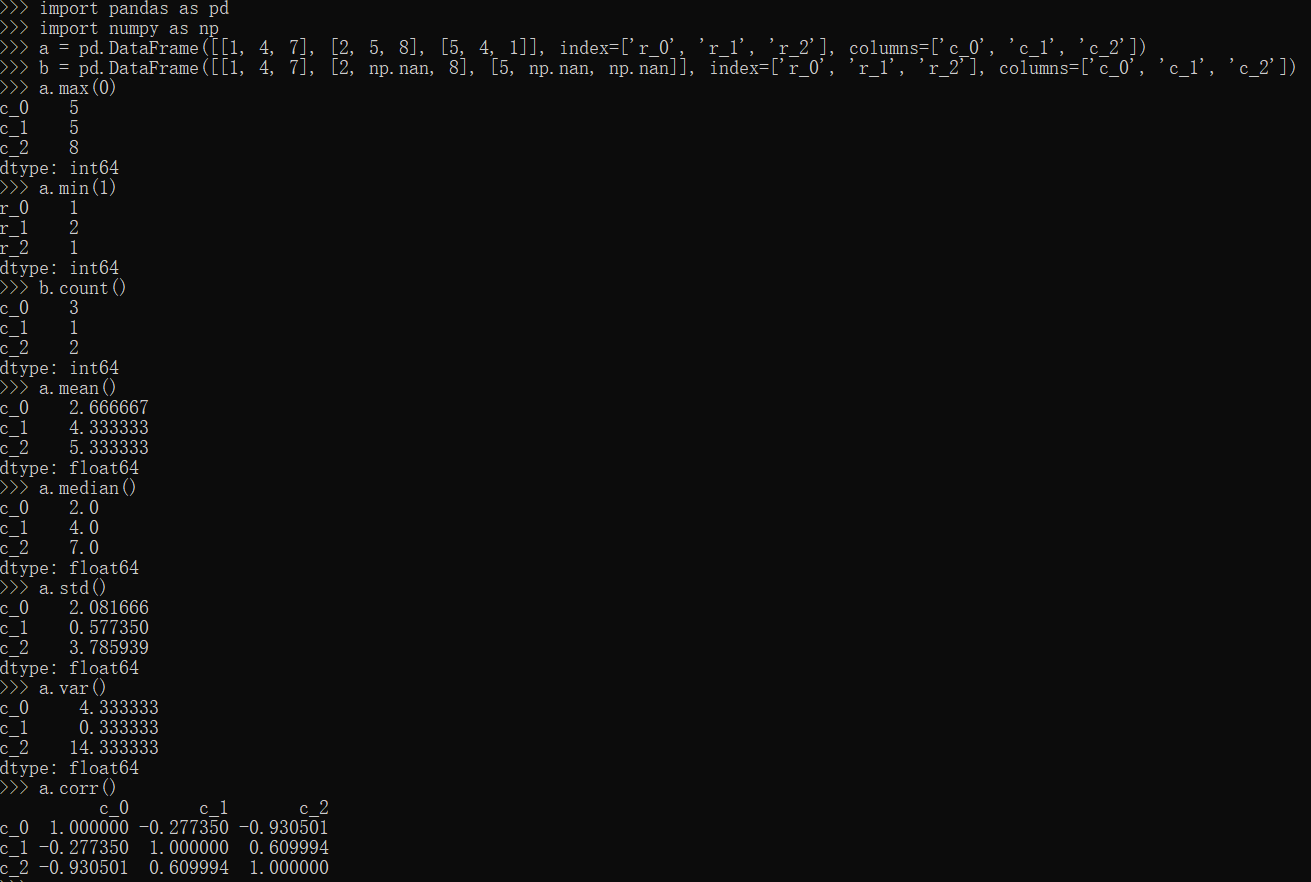
统计方法
1 | import pandas as pd |
pandas数据保存
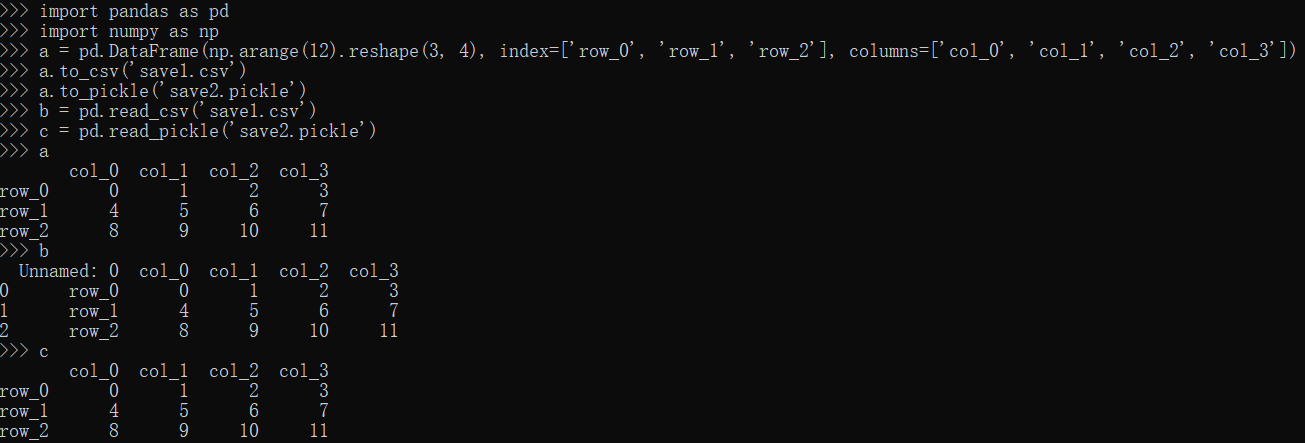
to_csv,read_csv方法
1 | import pandas as pd |
pandas数据显示
plot,plot.scatter方法
1 | import pandas as pd |
Pandas小结
Pandas可处理的数据更接近来源于生活中的数据,在数据分析,机器学习中,大量的数据都是具有标签的,不只是纯数字的数据,需要借助Pandas的帮助,因此pandas也作为机器学习三剑客之一。