背景介绍
TensorFlow:是谷歌公司于2015年11月9日推出的一个划时代的神经网络,深度学习开发平台。TensorFlow是一个庞大的系统,结构复杂,功能强大,利用**数据流图(Data Flow Graphs)进行数值计算的开源软件库,数据流图中的结点(Node)代表数学运算操作,边(Edge)**代表节点之间流通的数据,即张量(Tensor)。

TensorFlow特点
TensorFlow具有高度的灵活性:只要能够将计算表示为一个数据流,就可以使用TensorFlow进行运算。
TensorFlow具有强的可移植性:TensorFlow支持CPU和GPU运算,并且可以运行在个人电脑,服务器,移动设备等。
TensorFlow运算简单:内部实现了自动求导方式,像搭积木一样,只要建好运算图,不需要关心求导的复杂程度。
TensorFlow具有功能强大的可视化组建TensorBoard,可以在训练时监控训练过程。
TensorFlow应用
TensorFlow创建tensor
constant方法
1 | import tensorflow as tf |

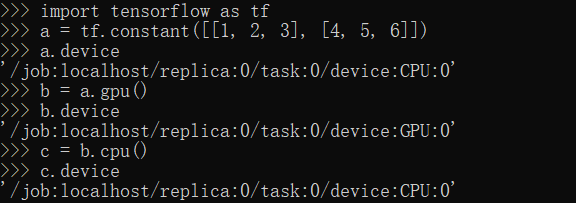
CPU,GPU方法
1 | import tensorflow as tf |
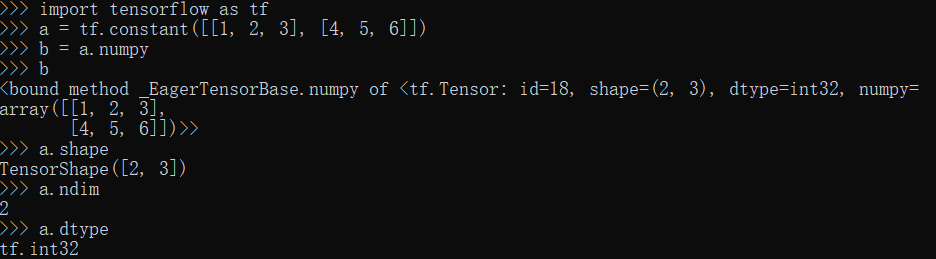
numpy,shape,ndim,dtype方法
1 | import tensorflow as tf |
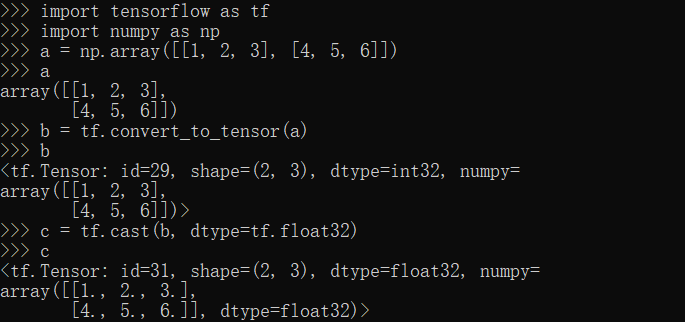
convert_to_tensor,cast方法
1 | import tensorflow as tf |
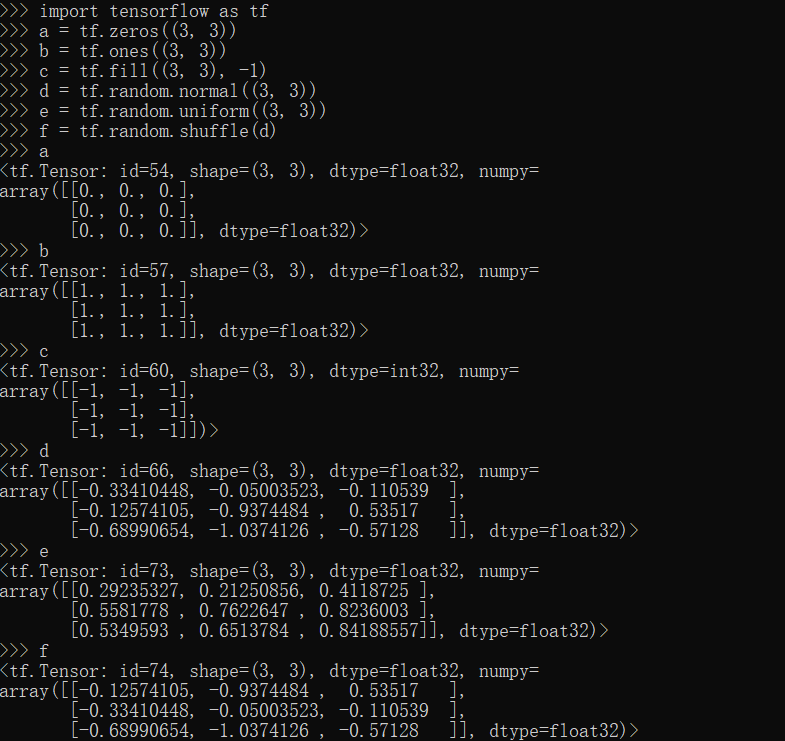
zeros,ones,fill,random方法
1 | import tensorflow as tf |
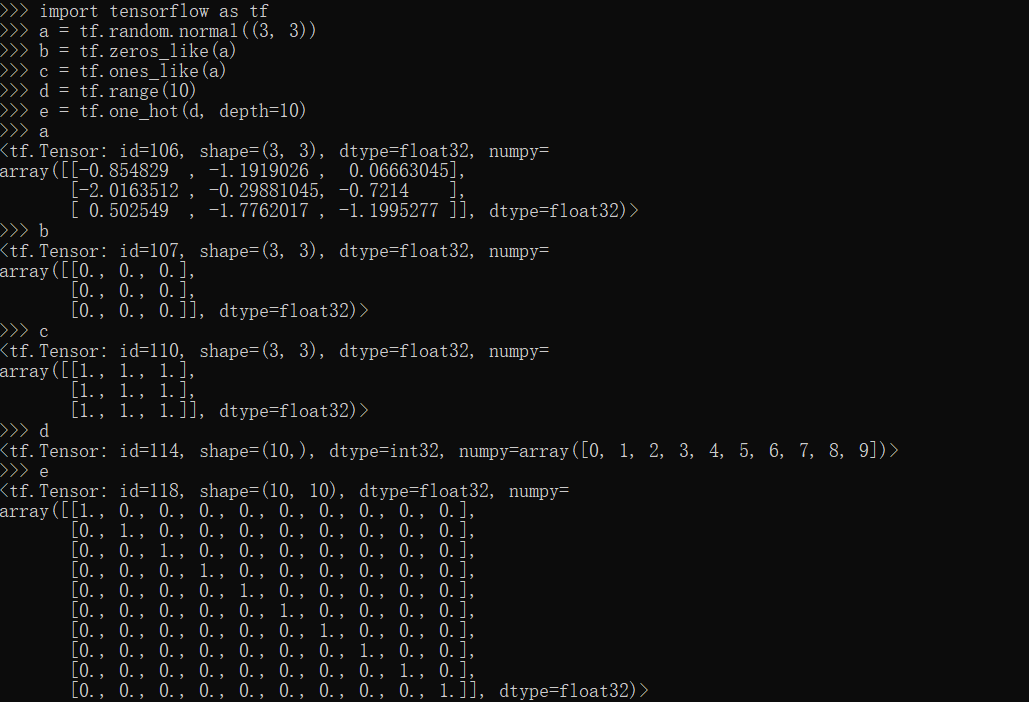
zeros_like,ones_like,one_hot,range方法
1 | import tensorflow as tf |
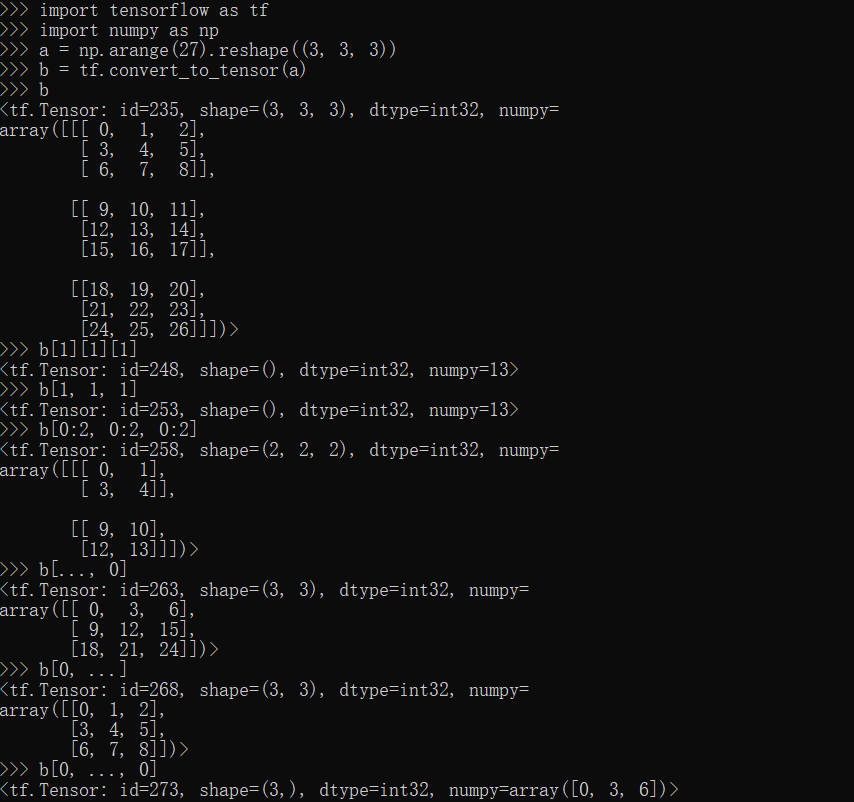
TensorFlow切片与索引
[]索引
1 | import tensorflow as tf |
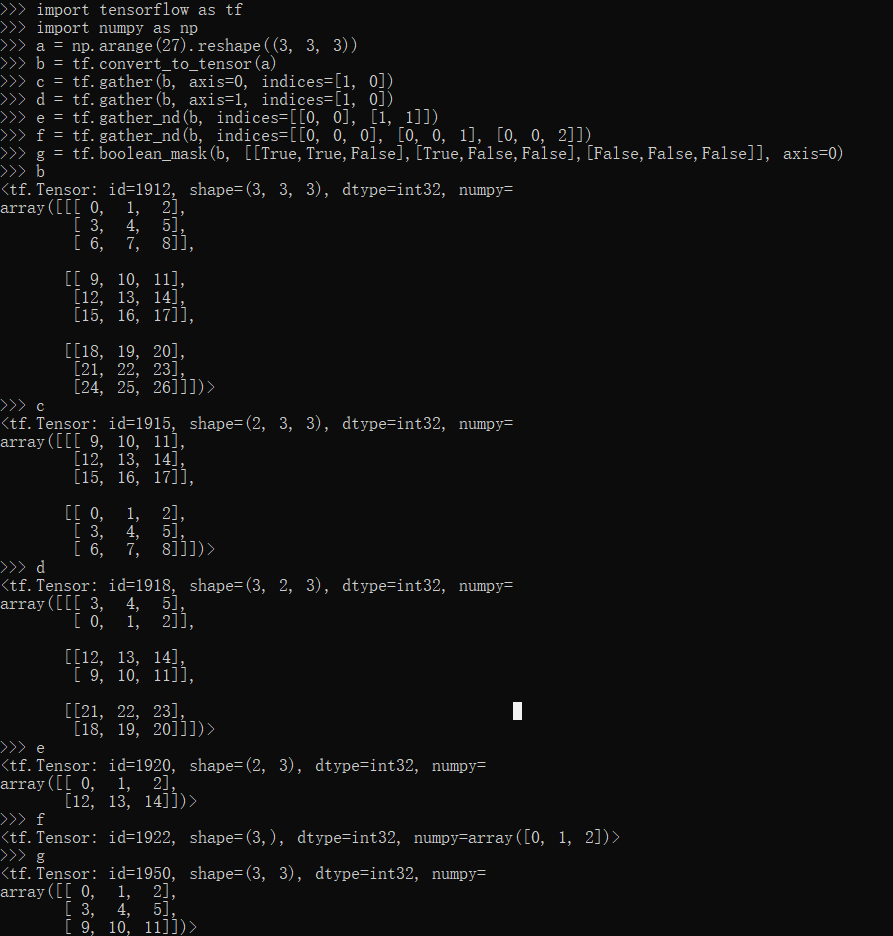
gather,gather_nd,boolean_mask方法
1 | import tensorflow as tf |
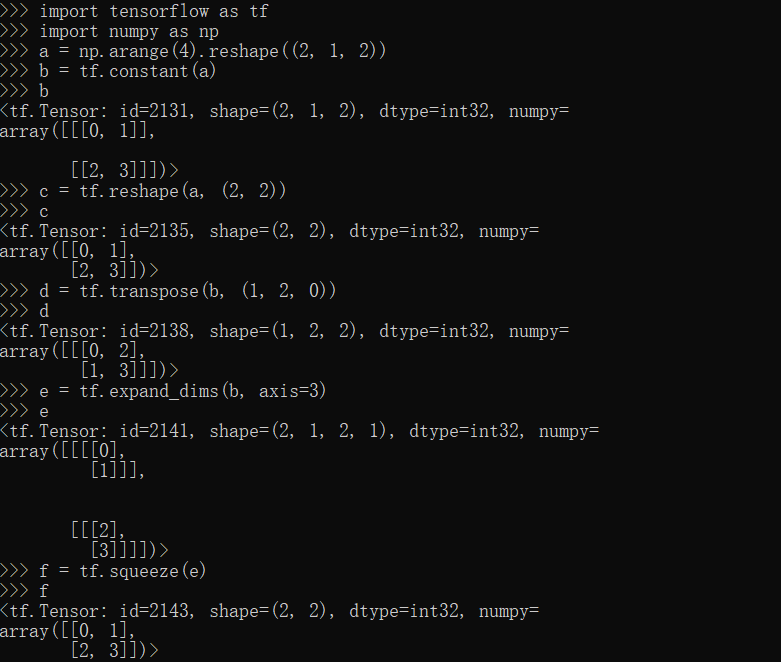
TensorFlow维度变化
reshape,transpose,expand_dims,squeeze方法
1 | import tensorflow as tf |
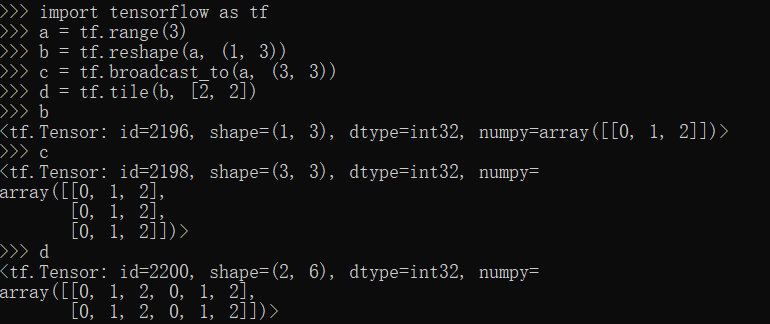
broadcast_to,tile方法
1 | import tensorflow as tf |
TensorFlow合并与分割
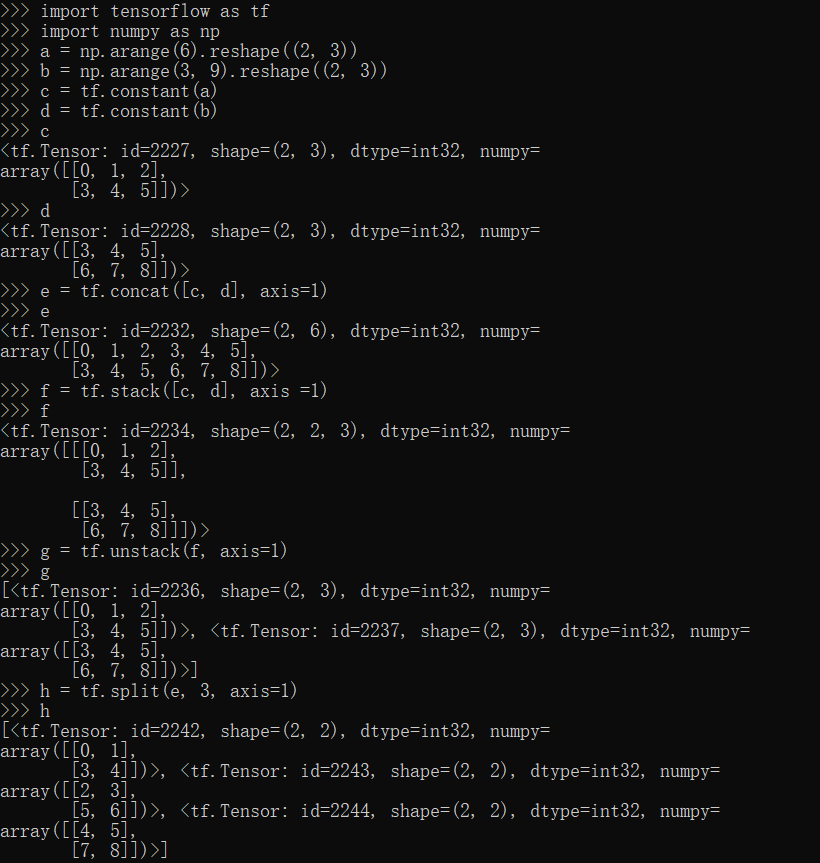
concat,stack,unstack,split方法
1 | import tensorflow as tf |
tensorflow数据统计
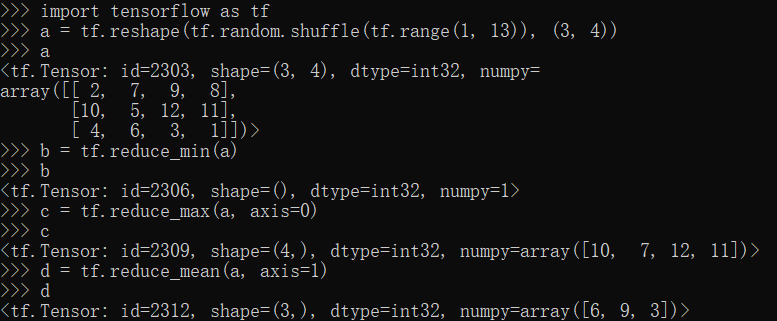
reduce_min,reduce_max,reduce_mean方法
1 | import tensorflow as tf |
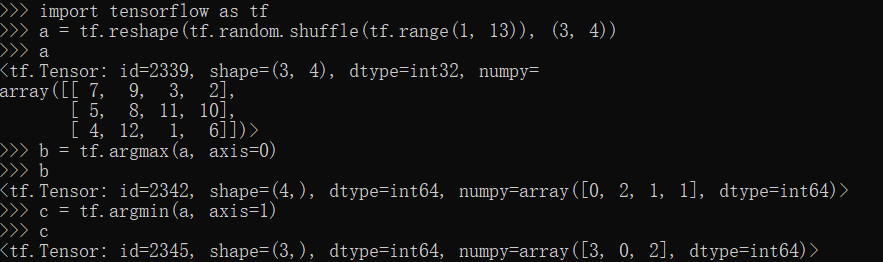
argmax,argmin方法
1 | import tensorflow as tf |
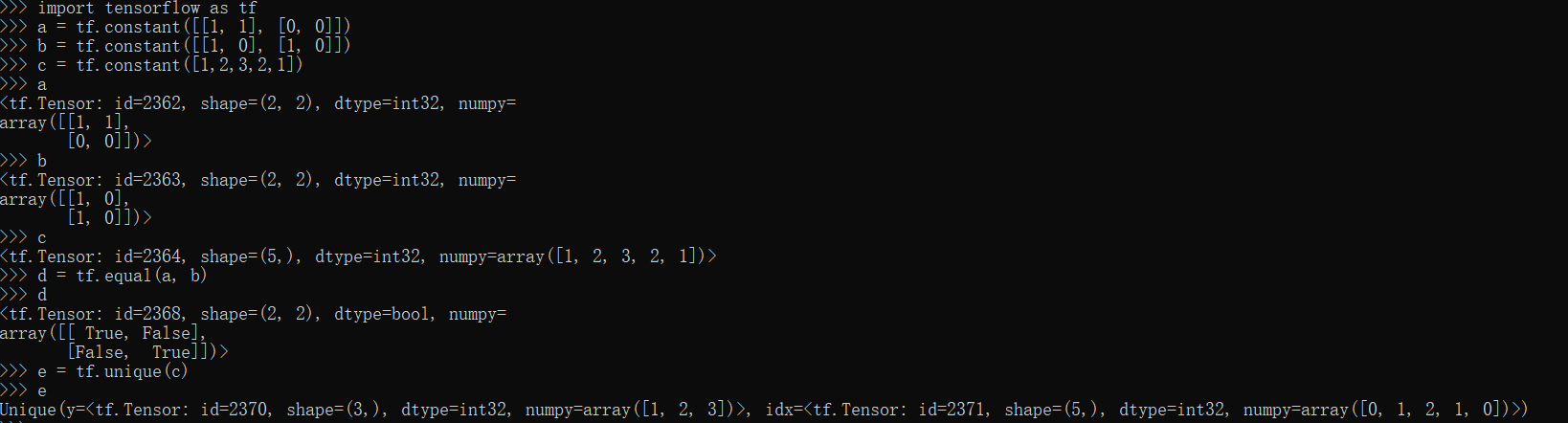
equal,unique方法
1 | import tensorflow as tf |
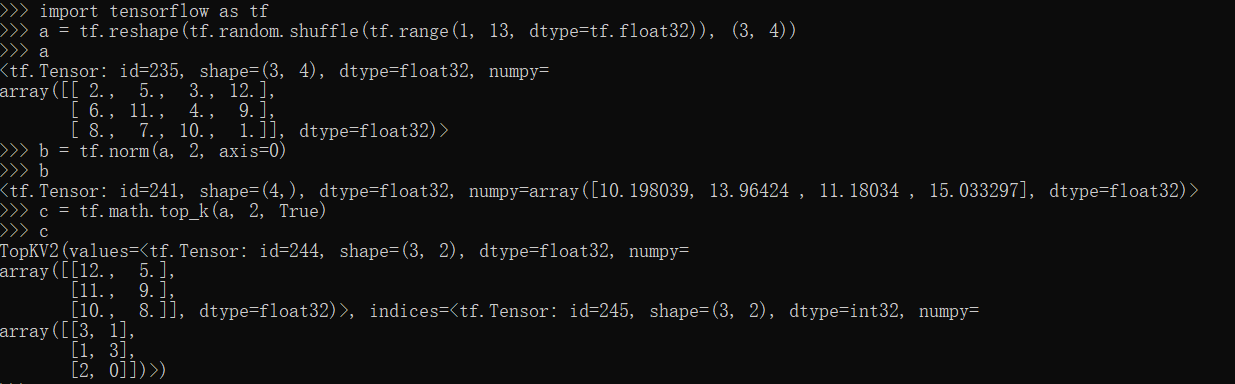
norm,top_k方法
1 | import tensorflow as tf |
tensorflow排序
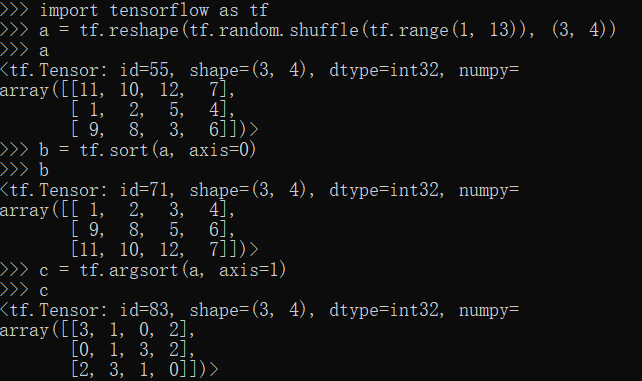
sort,argsort方法
1 | import tensorflow as tf |
tensorflow张量限幅
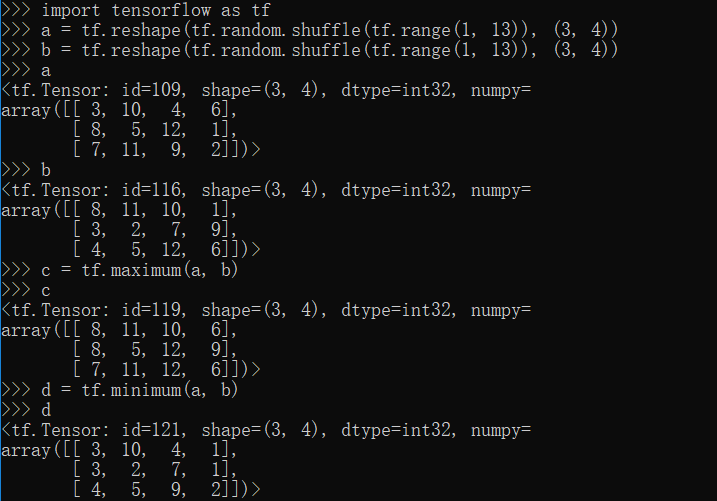
maximun,minimum方法
1 | import tensorflow as tf |
clip_by_value方法
1 | import tensorflow as tf |
tensorflow数学运算
常规运算方法
1 | import tensorflow as tf |
matmul方法
1 | import tensorflow as tf |
where方法
1 | import tensorflow as tf |
tensorflow深度学习
datasets(数据集)模块
1 | import tensorflow as tf |
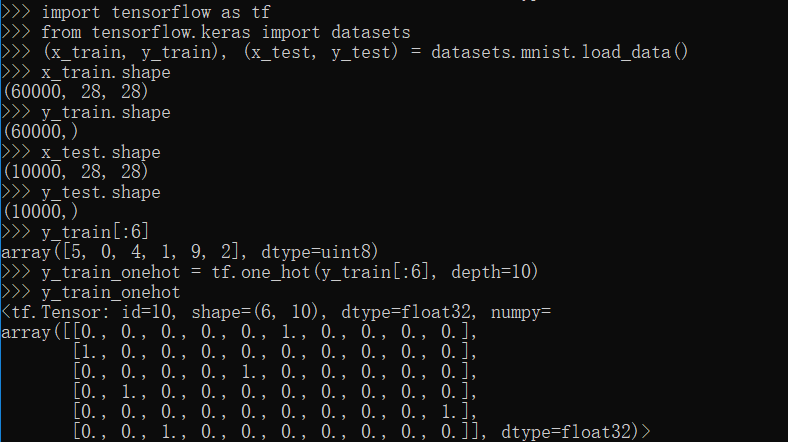
data(数据操作)模块
1 | import tensorflow as tf |
nn(神经网络)模块
1 | import tensorflow as tf |
optimizers(优化器)模块
1 | from tensorflow.keras import optimizers |
layers(网络层)模块
1 | import tensorflow as tf |
losses(误差计算)模块
1 | import tensorflow as tf |
Gradient(梯度下降)模块
1 | import tensorflow as tf |
TensorBoard模块
1 | # 首先要安装TensorBoard,pip install tensorboard |
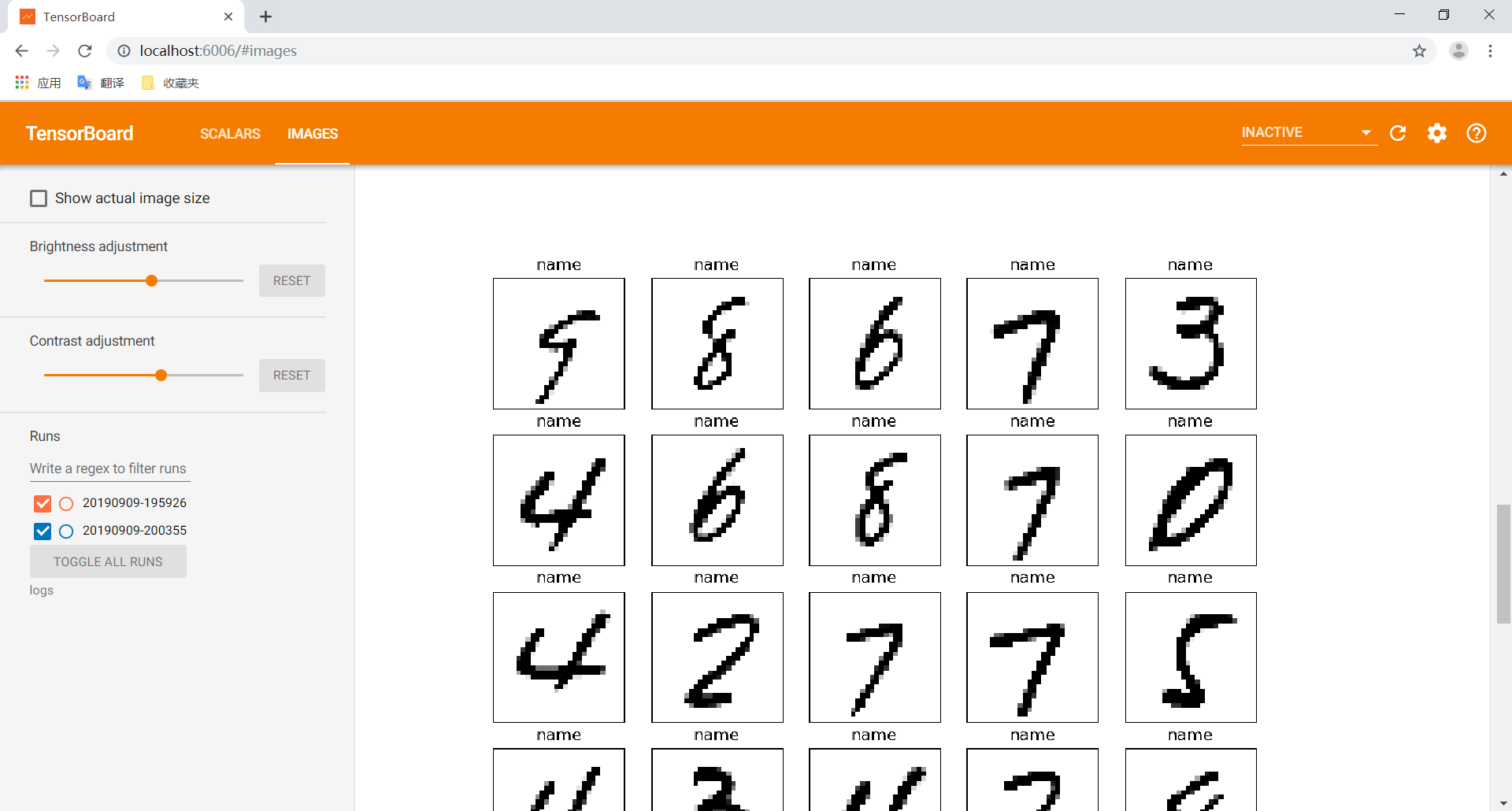
visdom模块
1 | # 首先要安装visdom,pip install visdom |
metrics(衡量指标)模块
1 | from tensorflow.keras import metrics |
Model(模型)模块
1 | import tensorflow as tf |
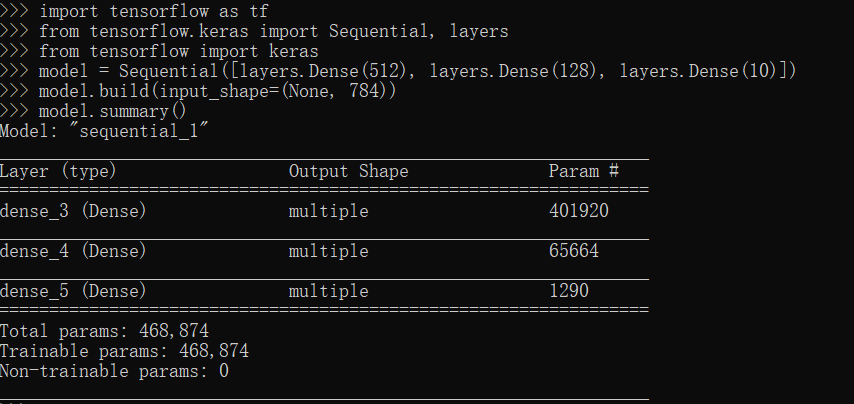
save(保存)模块
1 | import tensorflow as tf |
TensorFlow小结
由于TensorFlow背靠谷歌,具有最全的文档和资源,而且很多模型都有TensorFlow的源码实现,所以拥有较大的用户基数,这样使用户出现问题时能较容易地找到解决方案,这使TensorFlow目前作为最流行的深度学习框架。