背景介绍
PyTorch:是Facebook公司于2017年1月发布的神经网络,深度学习开发平台。但是PyTorch的历史可以追溯到2002年,当时Torch使用了一种小众语言Lua作为借口,使用人数较少,在2017年推出了Python接口的Torch,故称为PyTorch,现在也称为了当下最流行的深度学习框架之一。

PyTorch特点
PyTorch具有高度的简洁性:和TensorFlow1.x版本有较大差距,便于用户使用和理解。
PyTorch具有较快的速度:PyTorch的速度表现胜过TensorFlow和Keras等框架。
PyTorch使用方便:PyTorch写代码非常的优雅,所思即所写,不用考虑太多关于框架本身的束缚。
PyTorch具有活跃的社区,目前由作者亲自维护,供广大用户的学习和交流。
PyTorch具有功能强大的可视化组建Visdom,可以在训练时监控训练过程。
PyTorch应用
PyTorch创建tensor
tensor,arange方法
1 | import torch |
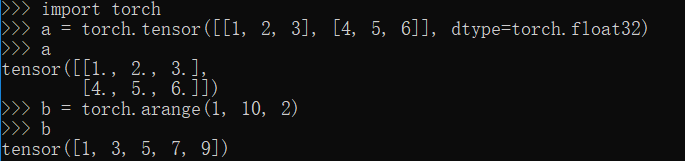
zeros,zeros_like,ones,ones_like,eye方法
1 | import torch |
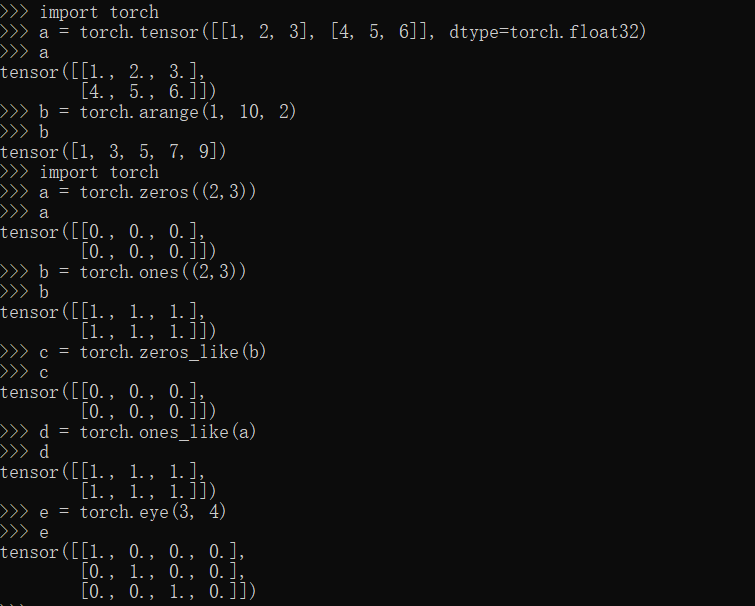
rand,randn,randperm,randint方法
1 | import torch |
linspace,logspace方法
1 | import torch |

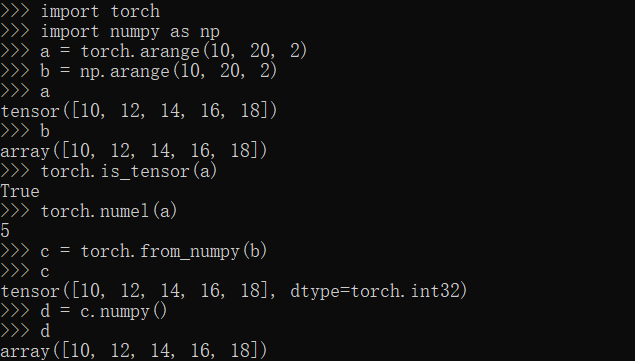
is_tensor,numel,from_numpy,numpy方法
1 | import torch |
shape,dtype方法
1 | import torch |
PyTorch切片与索引
[]索引
1 | import torch |
gather方法
1 | import torch |
PyTorch维度变换
reshape,squeeze,unsqueeze,transpose方法
1 | import torch |
torch.broadcast_tensors方法
1 | import torch |
PyTorch合并与分割
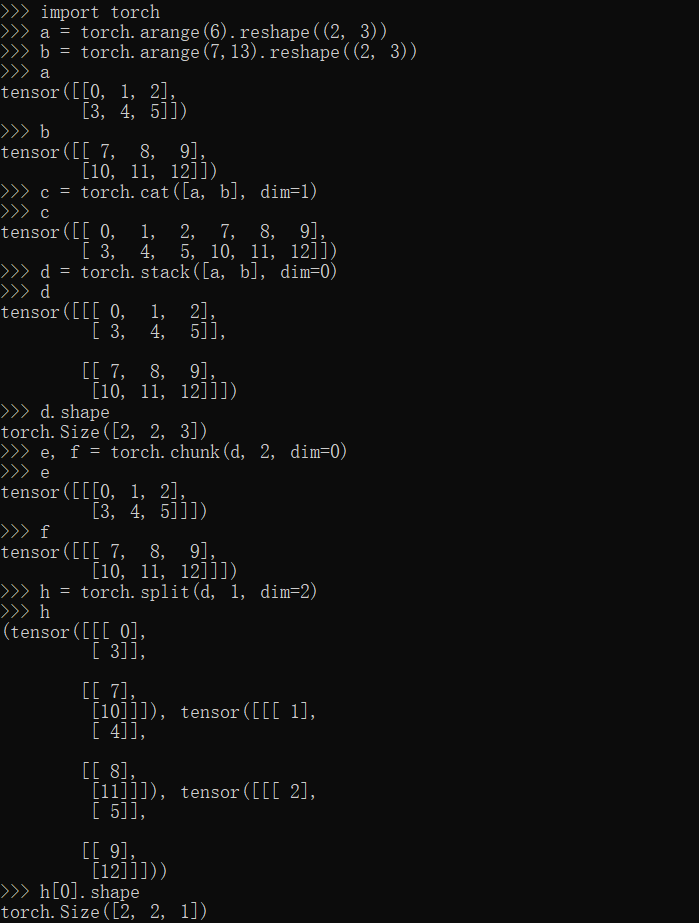
cat,stack,chunk,split方法
1 | import torch |
PyTorch数据统计
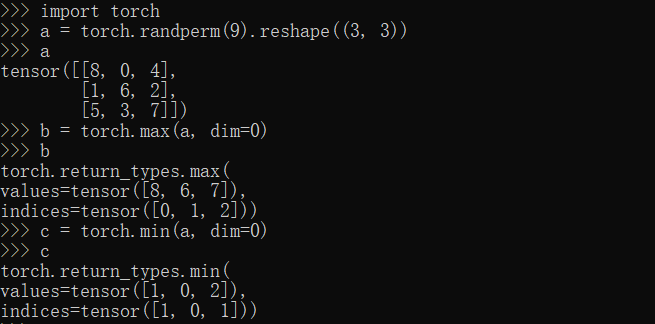
max,min方法
1 | import torch |
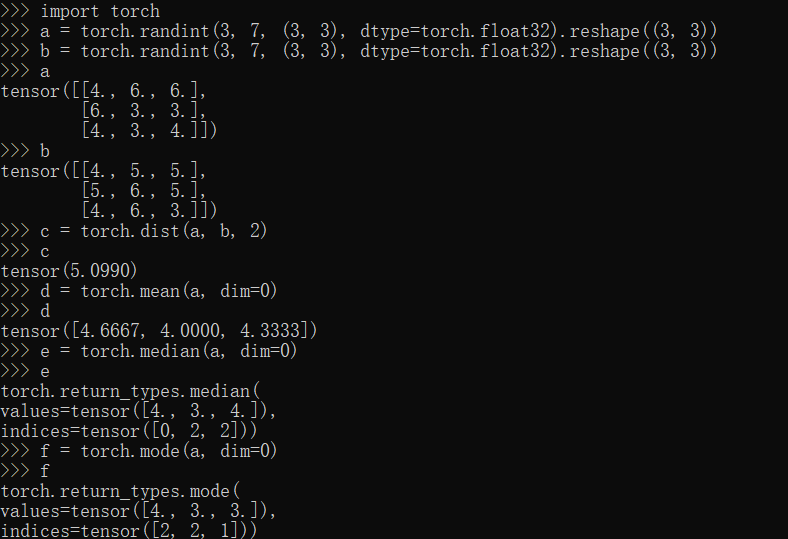
dist,mean,median,mode方法
1 | import torch |
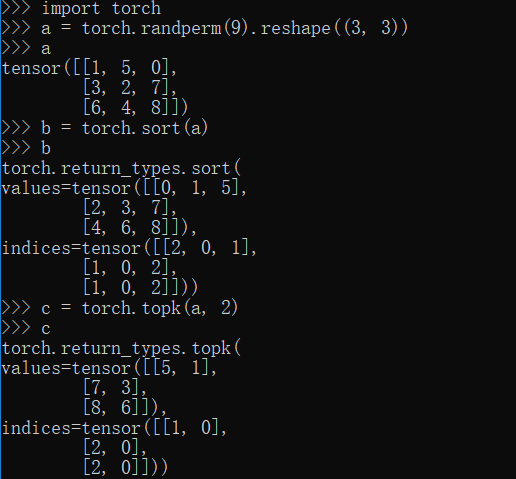
sort,topk方法
1 | import torch |
PyTorch张量限幅
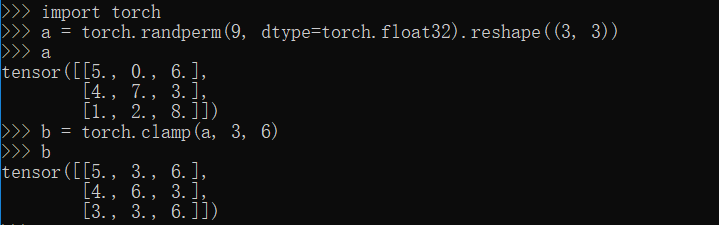
clamp方法
1 | import torch |
PyTorch数学运算
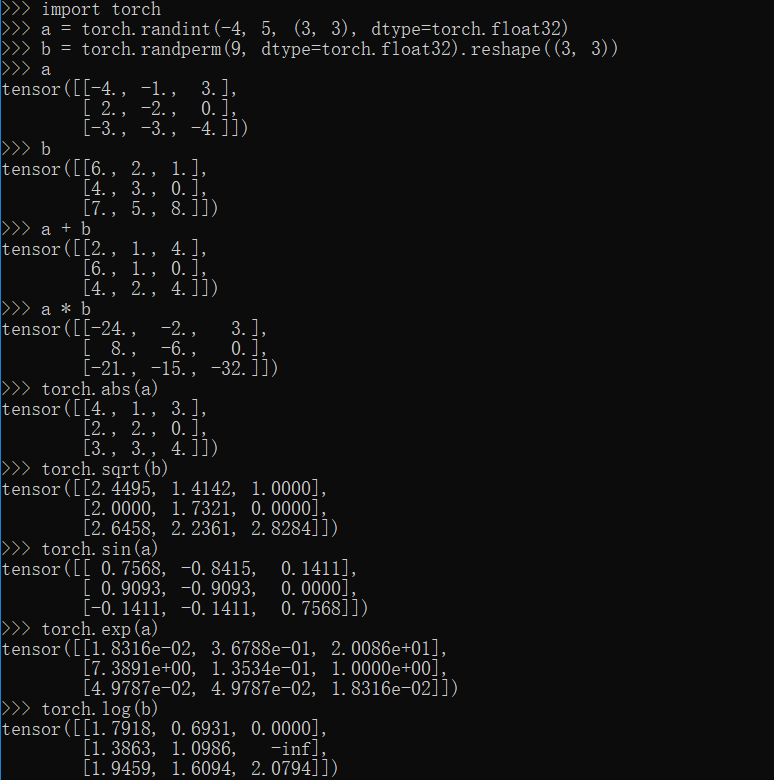
常规运算方法
1 | import torch |
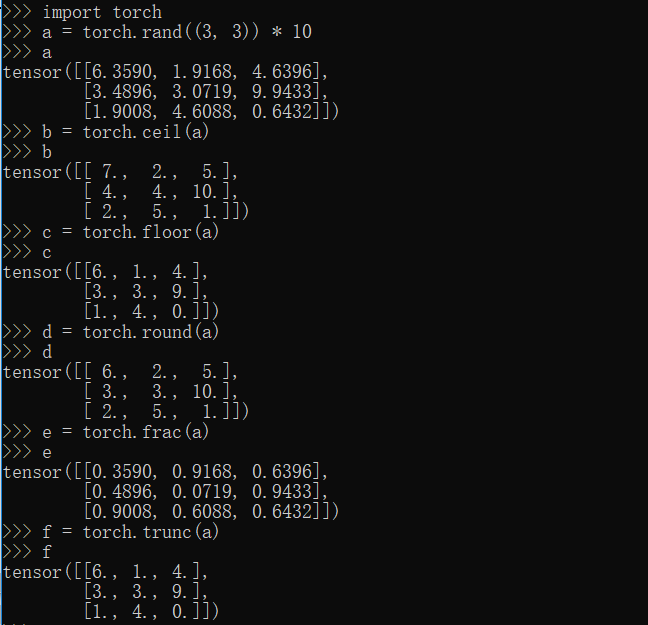
ceil,floor,round,frac,trunc方法
1 | import torch |
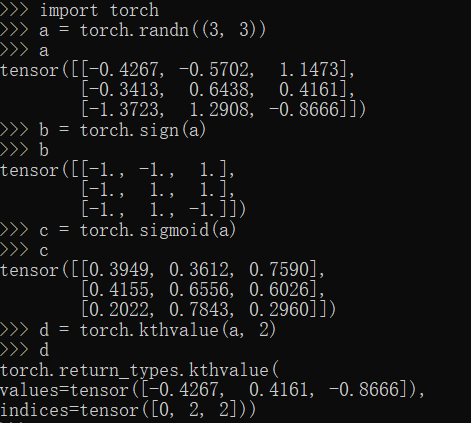
sign,sigmoid,kthvalue方法
1 | import torch |
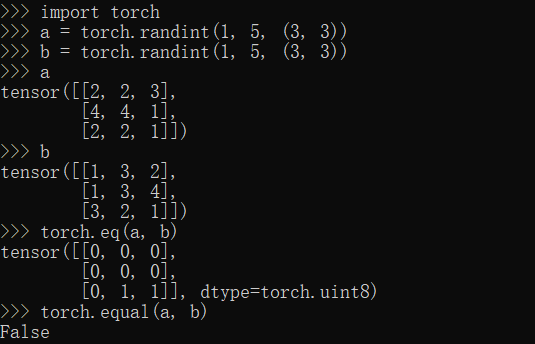
eq,equal方法
1 | import torch |
PyTorch线性代数
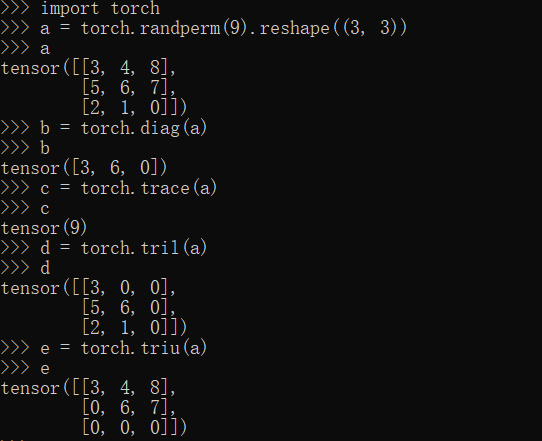
diag,trace,tril,triu方法
1 | import torch |
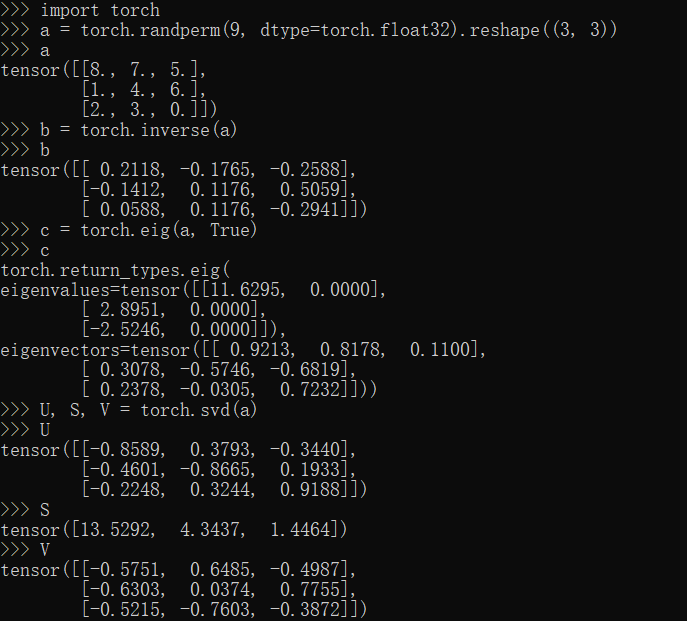
inverse,eig,svd方法
1 | import torch |
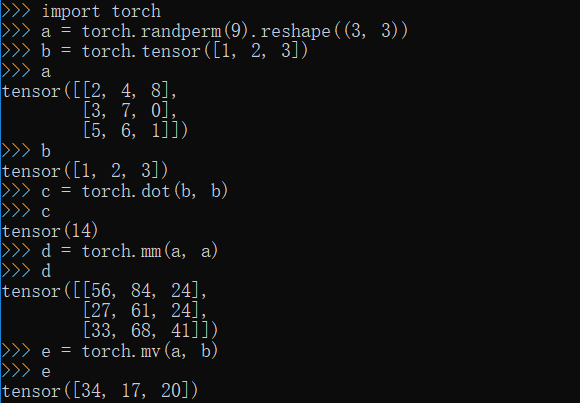
dot,mm,mv方法
1 | import torch |
PyTorch深度学习
functional(函数)模块
1 | from torch.nn import functional as f |
autograd(自动求导)模块
1 | import torch |
optim(优化器)模块
1 | import torch |
CPU与GPU模块
1 | import torch |
datasets(数据集)模块
1 | import torchvision.datasets as dsets |
data(数据)模块
1 | import torch.utils.data as Data |
nn(神经网络)模块
1 | import torch.nn as nn |
transforms(数据变换)模块
1 | import torchvision.transforms as transforms |
models(模型)模块
1 | import torchvision.models as models |
save(保持)模块
1 | import torch |
PyTorch小结
由于PyTorch的简洁性和优雅性,使得PyTorch对于入门学习的人来说非常的友好,现在PyTorch也是最热门的深度学习框架之一,具有较大的潜力。