背景介绍
Dynamic & Static(动态图与静态图):根据深度学习框架的不同,可以分成静态图框架和动态图框架,其中静态图框架的代表是TensorFlow1.x,Caffe2等,而动态图的代表是TensorFlow2.x,PyTorch等等。

动态图和静态图的区别
静态图:先定义计算图,不断使用,相同类型的数据只定义一次计算图,之后再次运行时不需要重新定义,也不需要重复执行代码,只需要将数据送入数据流即可。
特点:静态图保存了网络结构并且进行图优化,更加高效,但是弊端就是出错时很难进行单步调试,而且代码风格非常繁琐。
动态图:每次计算需要重复之前的代码。
特点:更加符合Python的代码风格,便于调试,弊端是效率较低。
动态图和静态图的转换
<color=red>以TensorFlow2.0为例,因为既可以使用静态图也可以使用动态图,TensorFlow2.0默认使用动态图机制,如果想使用静态图提高计算效率,可以在函数前加上@tf.function装饰器。
1 | import tensorflow as tf |
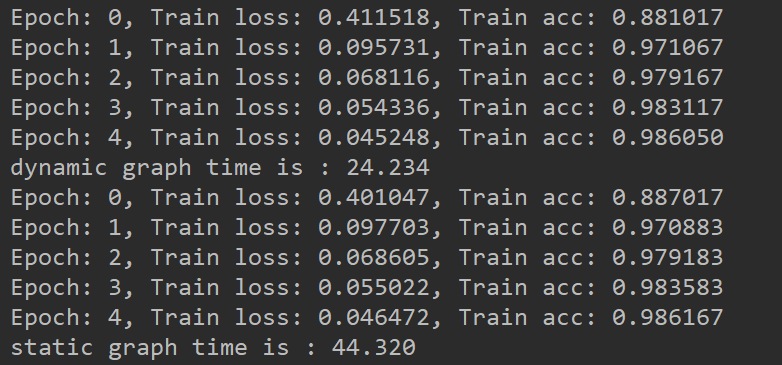
从上面这个例子可以看出,使用静态图计算和使用动态图计算达到了相同的效果,但是动态图的计算速度却比静态图慢很多,但是在静态图函数中加入断点无法进入函数,动态图可以加入断点进行调试,因此需要小伙伴们自行选择。当然也可以选择fit或者train_on_batch进行训练,它们都是使用静态图进行计算的。
<color=red>下面我们探究为什么静态图无法加入断点进行调试?
1 | import tensorflow as tf |
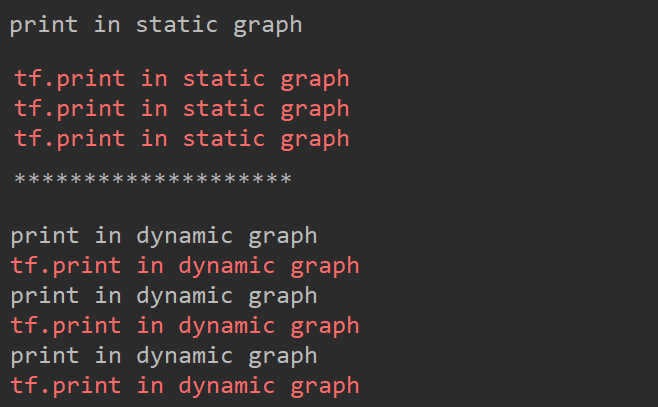
从这个例子中可以看出,在调用@tf.function修饰的函数时分为两步,第一步是建立图的过程,第二步是输入数据的过程。第一步建立图的过程是静态执行模式,执行普通的Python语言,对其中的数据Tensor数据是没有数值的,类似于TensorFlow1.x中的placeholder,建立图时的计算只是建立运算关系和节点,因此会输出print in static graph一次,第二步输入数据时,才会将数据送入各个节点之中进行计算,在这个例子中没有输入数据,但是tf.print函数也是一个节点,因此在节点计算时会输出三次tf.print中的内容,而print函数不是节点,因此只会在第一步执行一次,以后无论执行多少次相同运算图的内容,print函数都不会执行,除非重新建立运算图。而动态图执行过程中,每一次都要进入dynamic函数中输出tf.print函数和print函数,因此每一个都会输出三次。
<color=red>我们验证一下上面的思想,如何重新建立运算图,而且是否重新建立运算图会重新执行print语句
1 | import tensorflow as tf |
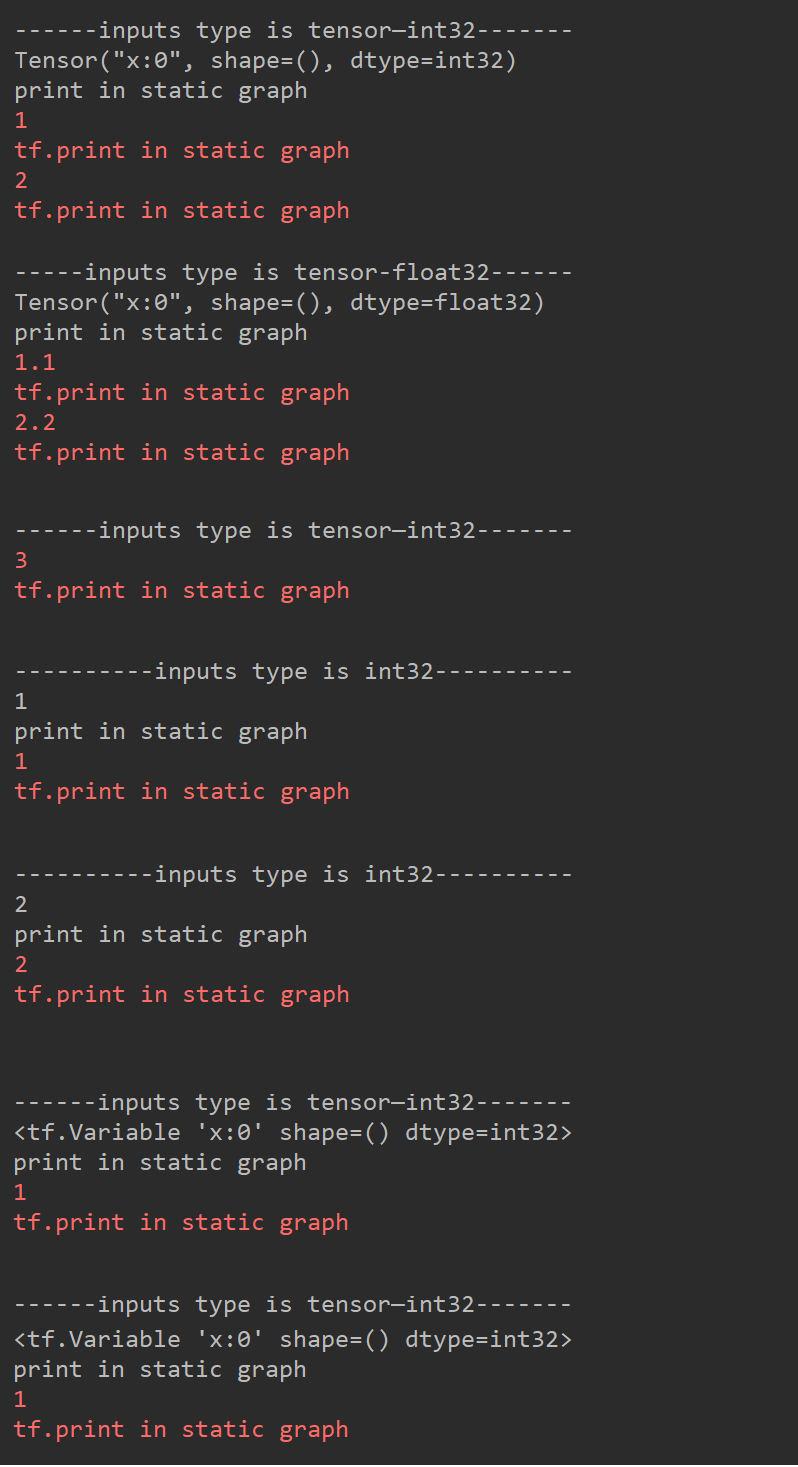
从这个例子可以明显看出同种类型和维度的常量输入只会建立一次运算图,并且保存到字典中,如果发现相同类型和维度的输入,则会调用之前建立好的运算图。第一次传入值为1的张量时,建立了一次运算图,所以会出现print in static graph的输出,而且print这个张量时,不显示数值,只显示s类型,维度和名称,因此第二次传入值为2的张量时,不需要重新建立运算图。但是当第三次传入一个值为1.1的float类型张量时,因为数据的类型不同,因此会重新建立运算图,当然之前的运算图也会保存下来,因为再次传入值为3的张量时,也没有重新建立运算图,而是调用了之前保存的运算图。但值得注意的是,python中的常数和Tensor变量,即使这个变量名称,类型和维度都相同,每次也都需要重新建立运算图,因此传入参数时尽量传入常量Tensor类型。
<color=red>使用tf.executing_eagerly()可以查看此时是静态执行模式还是动态执行模式,如果是静态执行模式,则正在搭建静态图或者数据在静态图中进行流动。
1 | import tensorflow as tf |
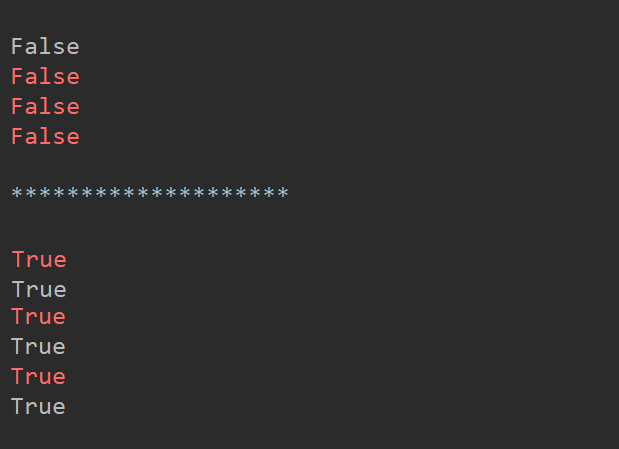
从这个例子可以看出,执行static函数时,白色的False是在搭建静态图中显示的print函数的内容,因此搭建静态图时处于静态执行模式中,红色的三次False是在数据流动中执行tf.print函数中的内容,说明在数据流的过程中也是处于静态执行模式。而白色的True和红色的True都表明在没有@tf.function装饰下,都是处于动态的执行模式。
小结
深度学习框架种类繁多,但是都大同小异,本枚菜鸟喜欢使用TensorFlow2版本,因为可以实现动态图和静态图的自由切换,让使用者学习一种框架就可以了解各种框架的不同,而且有很多的社区和官方文档,对于TensorFlow1.x版本有很多的改进,也是现在最主流的框架之一,推荐小伙伴们认真学习学习。