背景介绍
MobileNet-V3:是Google继MobileNet-V2之后的又一力作,于2019年提出,效果较MobileNet-V2有所提升。MobileNet-V3提供了两个版本,分别为MobileNet-V3-Large以及MobileNet-V3-Small,分别适用于对资源不同要求的情况。
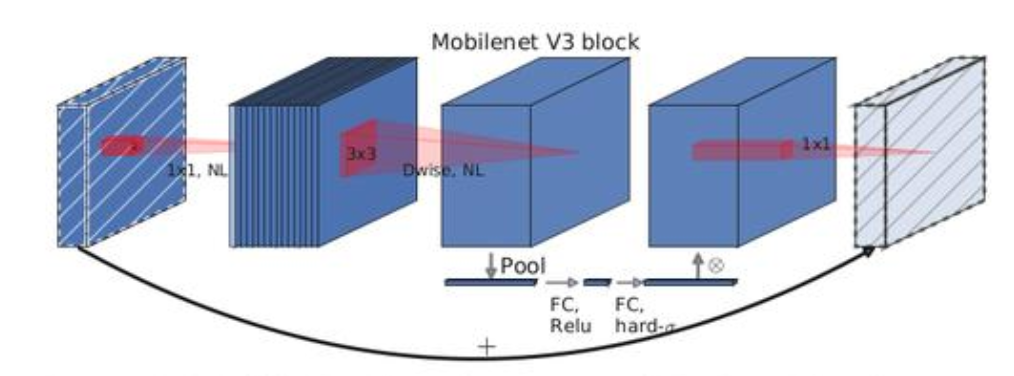
MobileNet-V3特点
保留MobileNet-V2的SeparableConv深度可分离结构和残差结构
引入SE结构,具有轻量级的注意力模型
对MobileNet-V2的头部结构进行优化,MobileNet-V2中第二层得到的特征图大小为112x112x32,而在MobileNet-V3中,只需要112x112x16即可保证精度,并且提升运行速度。
对MobileNet-V2的尾部结构进行优化,MobileNet-V2中对7x7的特征图进行1x1的卷积提升通道数,然后再进行全局平均池化,而在MobileNet-V3中,先对7x7的特征图进行全局平均池化,然后再进行1x1的卷积提升通道数,节约了49倍的参数量。
激活函数使用h-swish和ReLU6并存的方式,加快了运行的速度
Separable Convolution
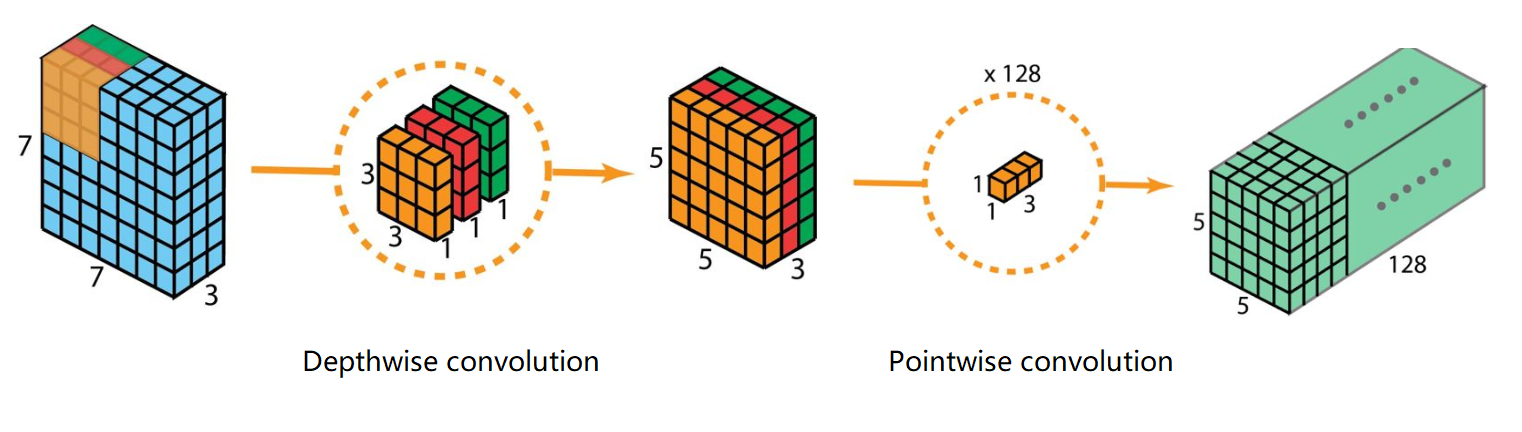
Separable Convolution(深度可分离卷积):是上面两个卷积合二为一的卷积操作。
第一步:DepthwiseConv,对每一个通道进行卷积
第二步:PointwiseConv,对第一步得到的结果进行1x1卷积,实现通道融合
主要作用是大大降低网络的参数量,并且可以调整为任意合适的通道数。第一步的目的是减少参数量,第二步是调整通道数,因此将两个卷积操作结合,组成深度可分离卷积。
Squeeze-and-Excitation
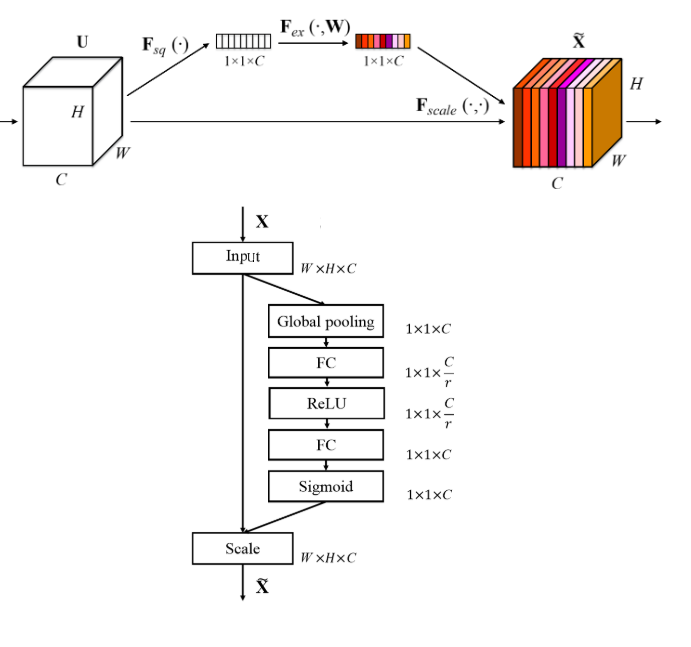
Squeeze-and-Excitation:又称为特征重标定卷积,或者注意力机制。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
首先是 Squeeze操作,先进行全局池化,具有全局的感受野,并且输出的维度和输入的特征通道数相匹配,它表征着在特征通道上响应的全局分布。
然后是Excitation操作,通过全连接层为每个特征通道生成权重,建立通道间的相关性,输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
不同尺寸MobileNet-V3网络结构
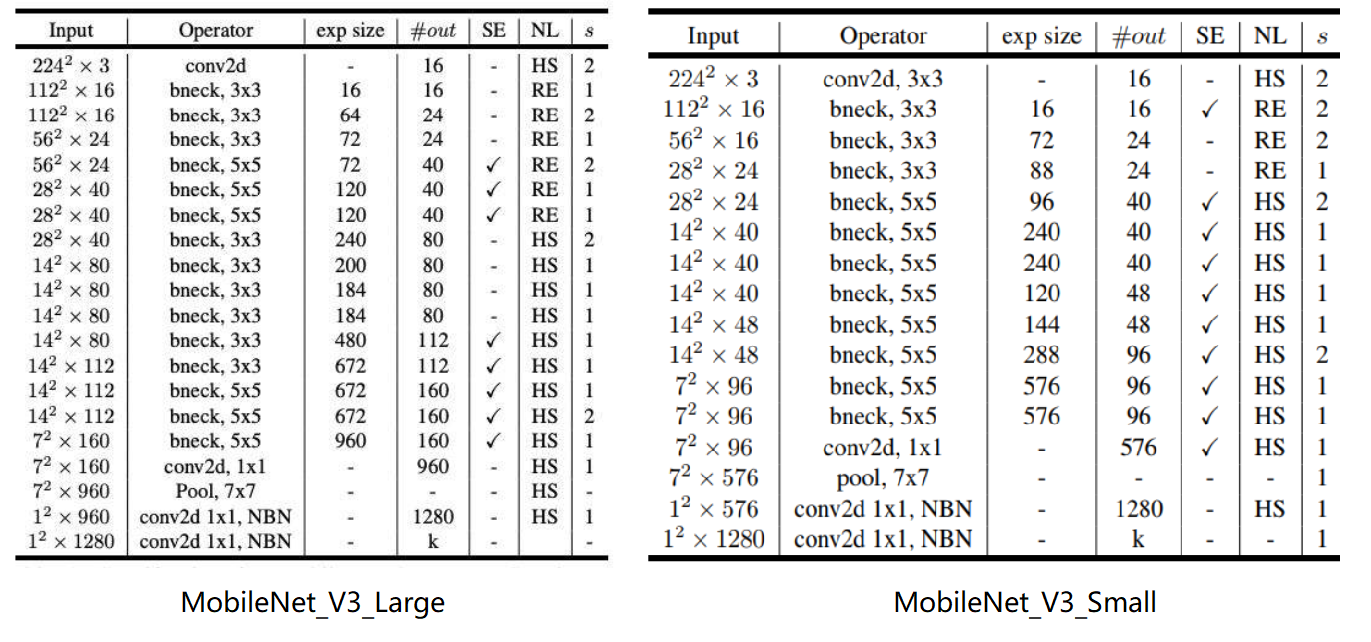
MobileNet-V3图像分析

TensorFlow2.0实现
1 | from functools import reduce |

MobileNet-V3小结
MobileNet-V3是一种复杂的轻量级深度学习网络,从上图可以看出MobileNet-V3模型的参数量为5M,其在MobileNet-V2的基础上加入了大量黑科技,因此获得了更好的效果。