背景介绍
语义分割:是计算机视觉的基础任务,在语义分割中我们需要将视觉输入分为不同的可解释类别,和聚类分割方法不同点在于此,其类别在真实世界中是有意义的,而聚类分割是可以将物体分成若干部分,但是每一部分不一定是有语义的,在自动驾驶,图像搜索等等领域都是非常重要的。
数据集以及IOU介绍
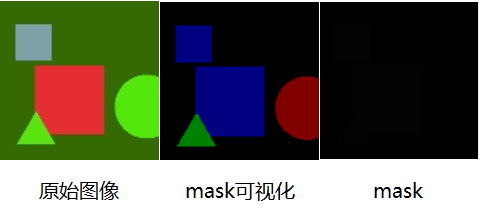
数据集:为了方便模型调试的方便,我的博客中介绍的数据集是一种简单的Shape数据集,只有1000个训练样本,为了加快训练速度,数据集的大小我也调整为128x128,这个数据集只有三类物体,分别是圆形,三角形和正方形,图像数据为jpg文件,掩模数据为png文件。
mask图像:mask图像给初学者第一眼看上去是懵逼的,当然包括我也是,这不是全黑的图像吗?这有何意义呢?掩模图像的保存是使用8位二进制数,因此它的值为0-255,称之为灰度值。每一个类别用一个数替代,为了使用方便则按顺序使用1,2,3来分别代表圆形,三角形和正方形,其中背景用0表示。在图像中,0为黑色,255为白色,灰度值越接近0,则图像越黑,越接近255则图像越白。因此在这个三类问题中,图像灰度最大为3,当然看起来是黑色的。不信可以对mask乘85则可以看到颜色。
IOU(Intersection Over Union,交并比):用于评估语义分割算法性能的指标是平均IOU,交并比也非常好理解,算法的结果与真实物体进行交运算的结果除以进行并运算的结果。通过下图可以直观的看出IOU的计算方法。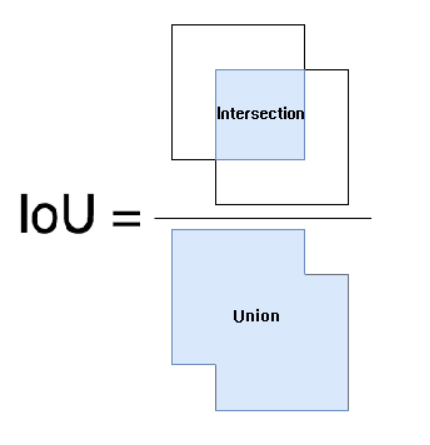
一些说明
- 在学习的时候,小伙伴可能会遇到一些代码上的困难,如tensorflow,numpy,opencv的用法,可以查看我的深度学习框架和Python常用库相关文章,里面会有一些简单的介绍,小伙伴们可以进行学习,最好是手动敲一敲,看一看。
- 因为这个博客是对学习的一些总结和记录,意在和学习者探讨和交流,并且给准备入门的同学一些手把手的教学,因此关于图像分割的算法参数设计,我都是自己尝试的,不是针对于这个数据集最优的参数,大家可以根据自己的实际需要修改网络结构。
- 实际的工程应用中,常常还需要对数据集进行大小调整和增强,在这里为了简单起见,没有进行复杂的操作,小伙伴们应用中要记得根据自己的需要,对图像进行resize或者padding,然后旋转,对比度增强,仿射运算等等操作,增加模型的鲁棒性,并且实际中的图像不一定按照顺序命名的,因此应用中也要注意图像读取的文件名。
- 为了让学习者看的方便和清晰,我没有使用多个文件对程序进行封装,因为我在刚开始学习模型的时候,查看GitHub代码,一个模型可能需要好几个文件夹,每个文件夹里面又有很多的代码文件,其中很多文件互相调用。虽然这样的工程项目是非常好管理和运行的,但是给初学者一种丈二和尚摸不着头脑的感觉,对此我深有体会。所以我就使用一个.py文件来封装,因此代码可能会有几百行,但是其中的各个函数和类都有自己的名字,可以保证学习者不会被纸老虎吓住。
- 在语义分割学习中,我会列举出一些经典的语义分割模型,因为模型太多,并且仍在不断的更新进步之中,所以大家可以联系我,和我进行沟通和交流,或者推荐给我一些优秀的模型。
- 关于问题的交流,图像的数据,需要的同学可以到主页查看我的QQ或者邮箱,我会非常荣幸的提供力所能及的帮助,小伙伴加好友的时候一定要记得备注,不然我可能会忽视一些粗心的小伙伴。
小结
语义分割是计算机视觉的基础任务,也是非常重要的任务之一,自从深度学习的时代到来,各种神经网络结构百花齐放,很难说出最好的语义分割方法,可能一个方法适用于很多数据,但也不能说明某一个算法一定优于另一个算法,我们要做的就是尽可能多的学习各种各样的深度学习模型,然后吸取这些模型成功的原因,投入到自己的工程应用之中。