背景介绍
UNet:于2015年发表于MICCA,设计的就是应用于医学图像的分割,由于医学影响本身的性质,语义较为简单,结构较为固定,数据量较少且具有多模态的性质,根据CT灌注方法不同,具有不同的模态。UNet实现了使用少量数据集进行大尺寸图像的有效算法,因为结构类似U型,故称之为UNet。
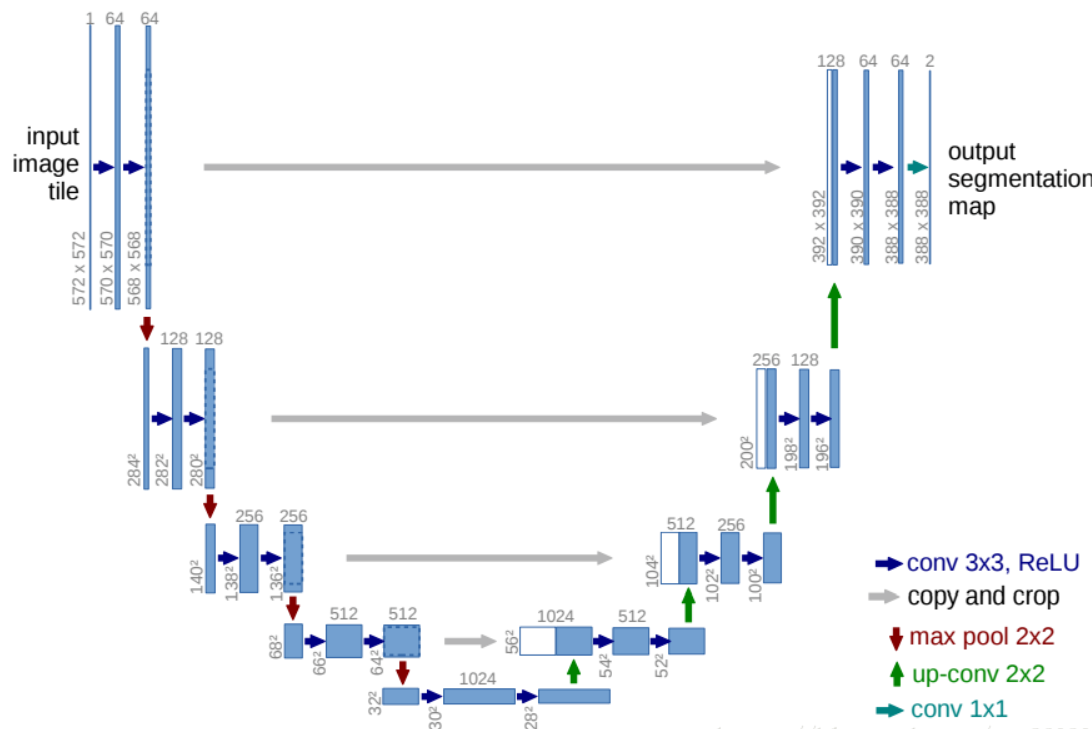
UNet特点
网络结构简单,易于实现
使用Over-tile策略,因为医学图像处理的图像尺寸较大,我们针对于某一区域进行分割时,可以获取周围更大尺寸的信息作为上下文,在卷积时只使用有效部分,这样防止padding=same时添加无效信息。因此图像的尺寸会缩小,在网络中需要对浅层特征进行Crop之后才可以与深层特征进行Concatenate。
使用随机弹性变形对数据进行增强,增加模型的鲁棒性。
使用加权Loss,对于某一点到边界的距离呈高斯关系的权重,距离边界越近权重越大,距离越远权重越小。
UNet图像分析
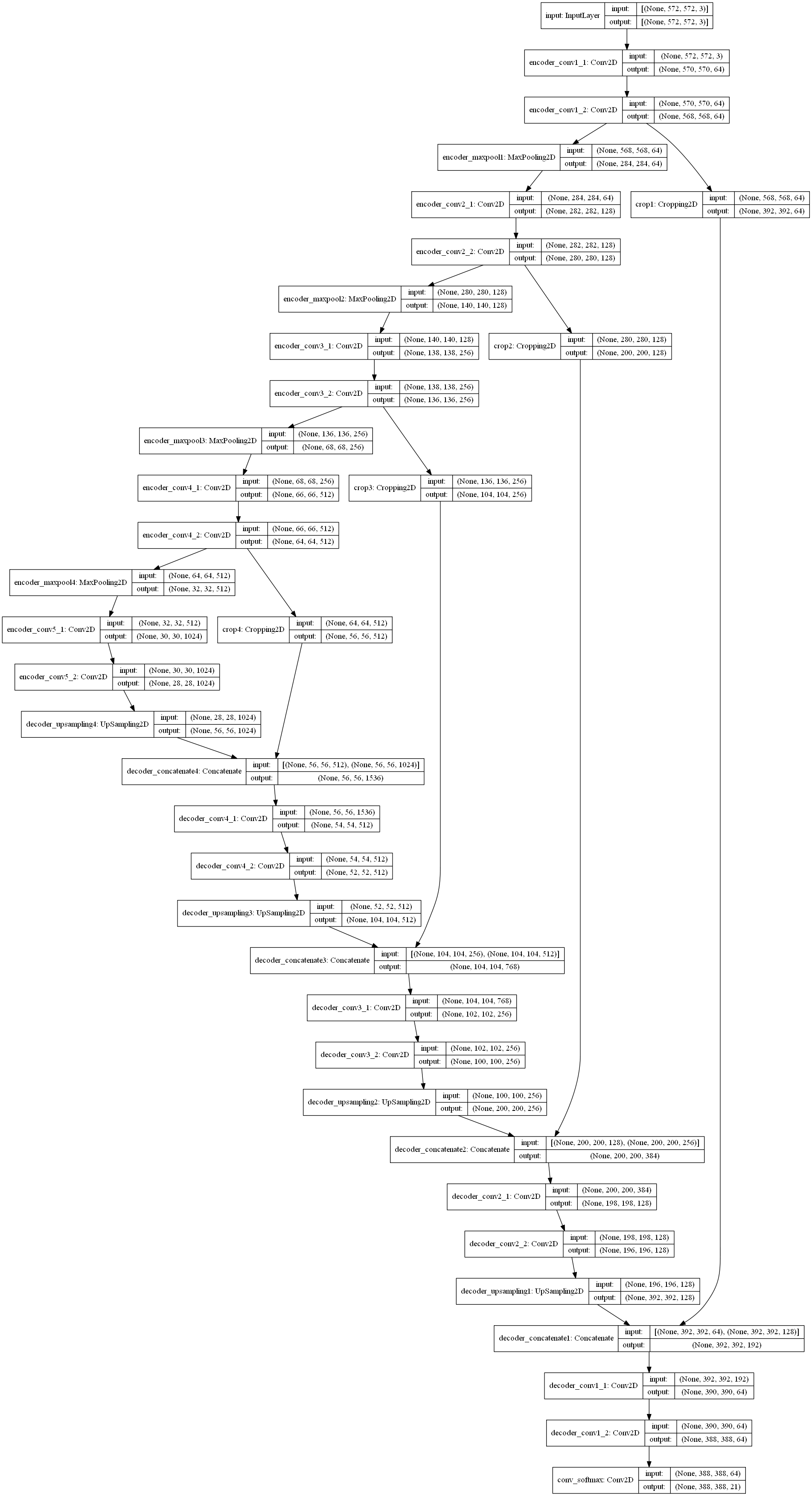
TensorFlow2.0实现
1 | from functools import reduce |
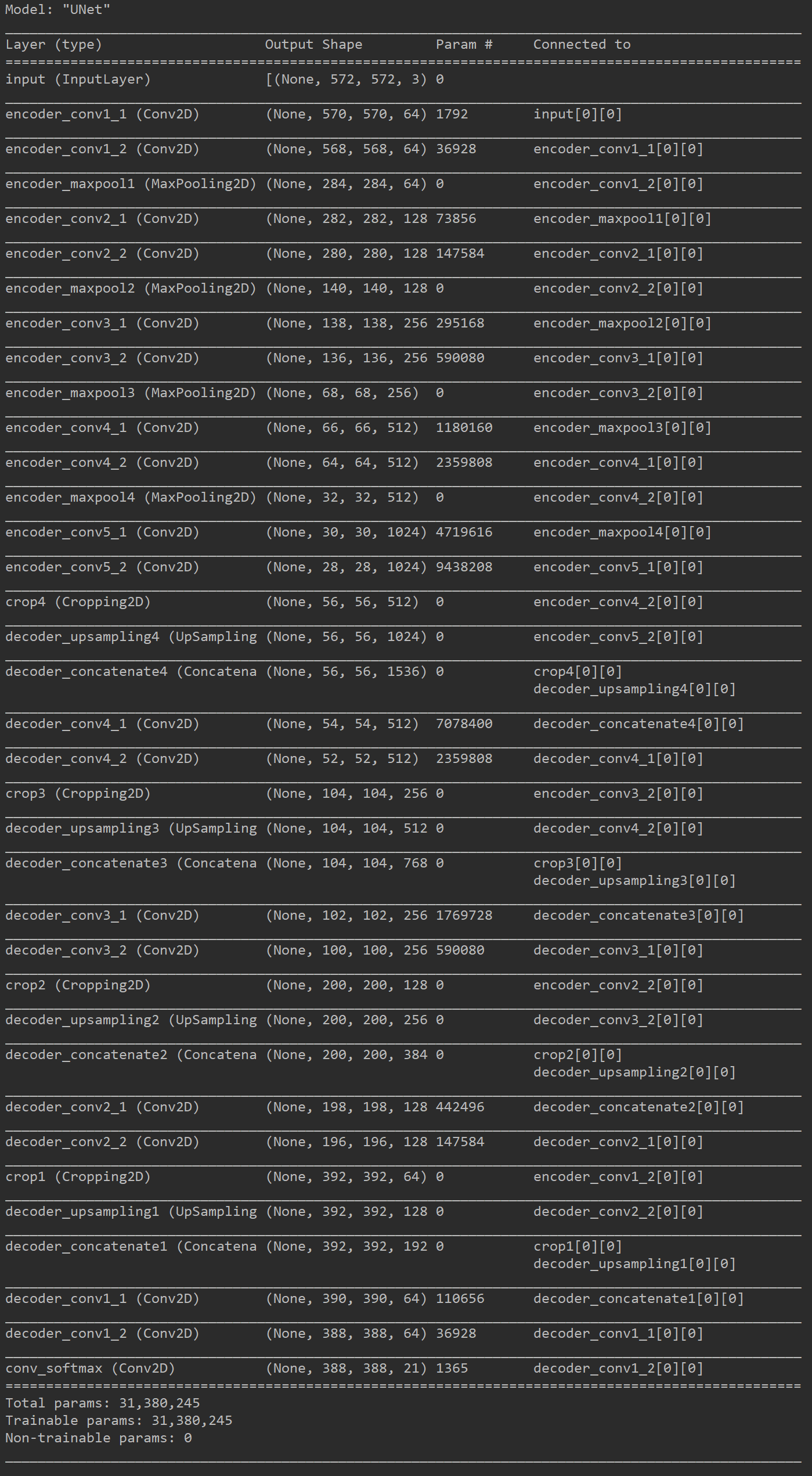
Shape数据集完整实战
文件路径关系说明
- project
- shape
- train_imgs(训练集图像文件夹)
- train_mask(训练集掩模文件夹)
- test_imgs(测试集图像文件夹)
- UNet_weight(模型权重文件夹)
- UNet_test_result(测试集结果文件夹)
- UNet.py
- shape
实战步骤说明
- 语义分割实战运行较为简单,因为它的输入的训练数据为图像,输入的标签数据也是图像,首先要对输入的标签数据进行编码,转换为类别信息,要和网络的输出维度相匹配,从(batch_size, height, width, 1)转换为(batch_size, height, width, num_class + 1),某个像素点为哪一个类别,则在该通道上置1,其余通道置0。即神经网络的输入大小为(batch_size, height, width, 3),输出大小为(batch_size, height, width, num_class + 1)。
- 设计损失函数,简单情况设置交叉熵损失函数即可达到较好效果。
- 搭建神经网络,设置合适参数,进行训练。
- 预测时,需要根据神经网络的输出进行逆向解码(编码的反过程),寻找每一个像素点,哪一个通道上值最大则归为哪一个类别,即可完成实战的过程。
小技巧
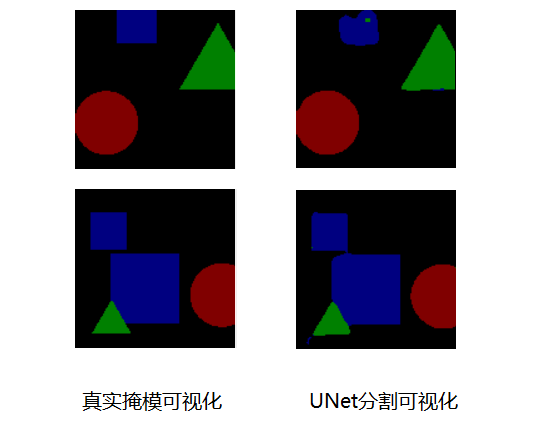
- 设置的图像类别数为实际类别数+1,1代表背景类别,此数据集为3类,最后的通道数为4,每一个通道预测一类物体。在通道方向求Softmax,并且求出最大的索引,索引为0则代表背景,索引为1则代表圆形,索引为2则代表三角形,索引为3则代表正方形。
- 实际中用到的图像的尺寸一般都不是特别大,因此不需要将图像进行Crop,所以卷积的padding修改为same。
- 损失函数使用交叉熵即可,使用加权Loss,计算量较大,而且需要计算边缘操作。
- 设置了权重的保存方式,学习率的下降方式和早停方式。
- 使用yield关键字,产生可迭代对象,不用将所有的数据都保存下来,大大节约内存。
- 其中将1000个数据,分成800个训练集,100个验证集和100个测试集,小伙伴们可以自行修改。
- 注意其中的一些维度变换和numpy,tensorflow常用操作,否则在阅读代码时可能会产生一些困难。
- UNet的特征提取网络类似于VGG,小伙伴们可以参考特征提取网络部分内容,选择其他的网络进行特征提取,比较不同网络参数量,运行速度,最终结果之间的差异。
- 图像输入可以先将其归一化到0-1之间或者-1-1之间,因为网络的参数一般都比较小,所以归一化后计算方便,收敛较快。
- 实际的工程应用中,常常还需要对数据集进行大小调整和增强,在这里为了简单起见,没有进行复杂的操作,小伙伴们应用中要记得根据自己的需要,对图像进行resize或者padding,然后旋转,对比度增强,仿射运算等等操作,增加模型的鲁棒性,并且实际中的图像不一定按照顺序命名的,因此应用中也要注意图像读取的文件名。
完整实战代码
1 | import os |
模型运行结果
UNet小结
UNet是一种简单的语义分割网络,在输入图像尺寸为572x572时,参数量为31M。因为其padding方式使其图像尺寸缩小,适合于大尺寸图像的分割,并且采用加权损失函数和优秀的图像增强操作,使得其在医学图像处理中有良好的表现。