背景介绍
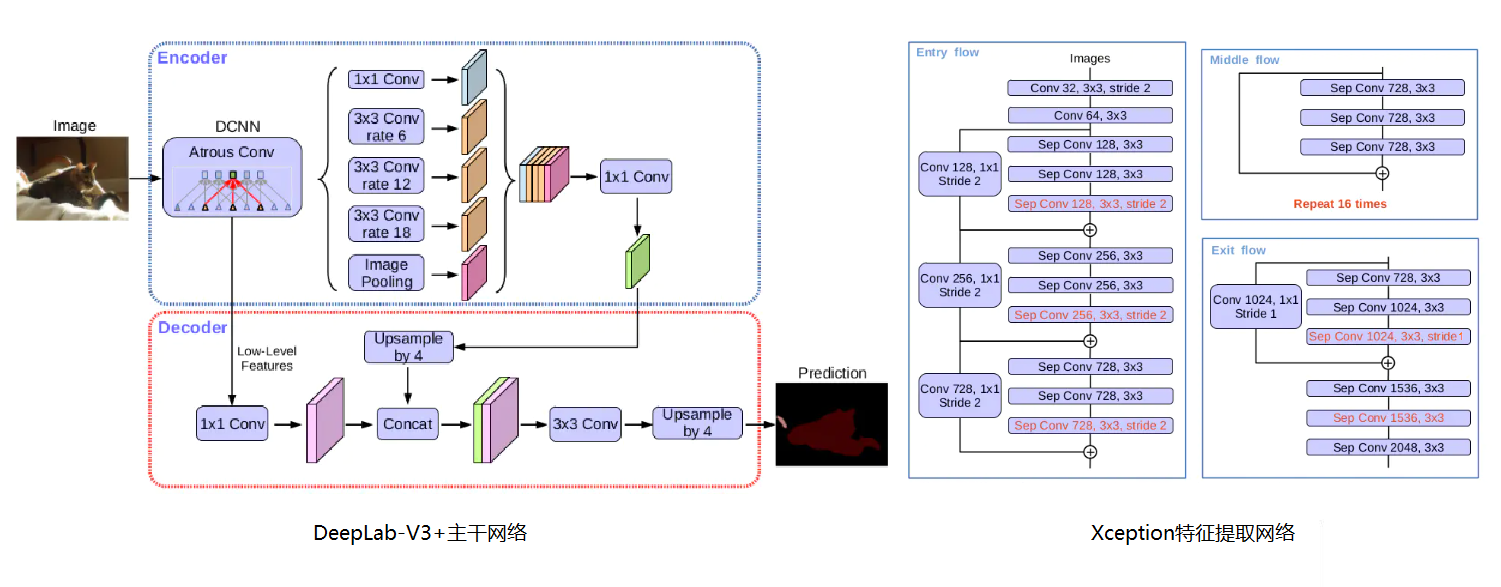
DeepLab-V3+:于2018年发表在CVPR上,应用改进的Xception作为特征提取网络,并将深度可分离卷积与ASPP(Atrous Spatial Pyramid Pooling,空洞空间卷积池化金字塔)结合,大量缩小模型参数,被认为是现在语义分割模型的新高峰。
DeepLab-V3+特点
改进了Xception,将Middle Flow从8层变为16层,加深网络层数,且将池化层替换为深度可分离卷积层,并且在3x3深度可分离卷积层后添加BN层和ReLU层。
使用ASPP结构,其中设置不同的dilation_rate提取不同尺度的特征。
从Xception浅层网络中提取出一个分支,作为浅层特征,和ASPP结构产生的深层特征进行融合
空洞卷积(atrous convolutions)和普通卷积之间的区别
空洞卷积(atrous convolutions)又称膨胀卷积(dilated convolutions),在卷积层引入了一个膨胀率(dilation rate)参数,定义了卷积核的间隔数量,普通卷积的卷积核dilation rate=1
优点:扩大感受野,相邻的像素点可能存在大量冗余信息,扩大感受野可能会获取多尺度信息,这在视觉任务上非常重要,且不需要引入额外参数,如果增加分辨率或者采用大尺寸的卷积核则会大大增加模型的参数量。
缺点:由于空洞卷积的计算方式类似于棋盘格式,因此可能产生棋盘格效应,可以参考棋盘格可视化。如果膨胀率太大卷积结果之间没有相关性,可能会丢失局部信息。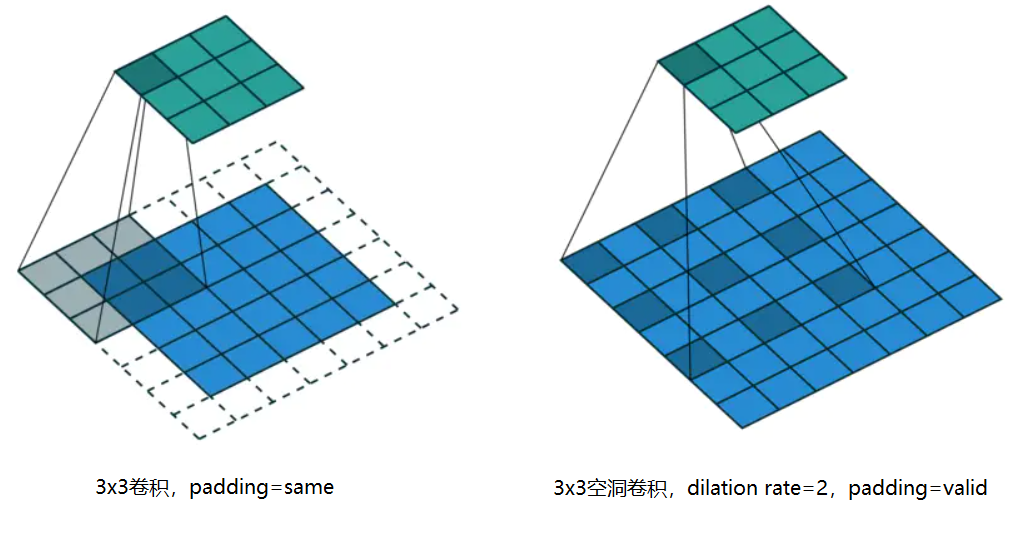
DeepLab-V3+图像分析

TensorFlow2.0实现
1 | from functools import reduce |

Shape数据集完整实战
文件路径关系说明
- project
- shape
- train_imgs(训练集图像文件夹)
- train_mask(训练集掩模文件夹)
- test_imgs(测试集图像文件夹)
- DeepLab-V3+_weight(模型权重文件夹)
- DeepLab-V3+_test_result(测试集结果文件夹)
- DeepLab-V3+.py
- shape
实战步骤说明
- 语义分割实战运行较为简单,因为它的输入的训练数据为图像,输入的标签数据也是图像,首先要对输入的标签数据进行编码,转换为类别信息,要和网络的输出维度相匹配,从(batch_size, height, width, 1)转换为(batch_size, height, width, num_class + 1),某个像素点为哪一个类别,则在该通道上置1,其余通道置0。即神经网络的输入大小为(batch_size, height, width, 3),输出大小为(batch_size, height, width, num_class + 1)。
- 设计损失函数,简单情况设置交叉熵损失函数即可达到较好效果。
- 搭建神经网络,设置合适参数,进行训练。
- 预测时,需要根据神经网络的输出进行逆向解码(编码的反过程),寻找每一个像素点,哪一个通道上值最大则归为哪一个类别,即可完成实战的过程。
小技巧
- 设置的图像类别数为实际类别数+1,1代表背景类别,此数据集为3类,最后的通道数为4,每一个通道预测一类物体。在通道方向求Softmax,并且求出最大的索引,索引为0则代表背景,索引为1则代表圆形,索引为2则代表三角形,索引为3则代表正方形。
- ASPP模块中的膨胀率,可以根据需要进行调整,论文中膨胀率分别为6, 12, 18,在这个简单数据集中,输入尺寸为16,因此我选择的膨胀率是2,4,8。
- 设置了权重的保存方式,学习率的下降方式和早停方式。
- 使用yield关键字,产生可迭代对象,不用将所有的数据都保存下来,大大节约内存。
- 其中将1000个数据,分成800个训练集,100个验证集和100个测试集,小伙伴们可以自行修改。
- 注意其中的一些维度变换和numpy,tensorflow常用操作,否则在阅读代码时可能会产生一些困难。
- DeepLab-V3+的特征提取网络为改进的Xception,论文中也比较了ResNet特征提取网络的性能。实战中我选择的是Middle Flow为8的Xception,小伙伴们可以参考特征提取网络部分内容,选择其他的网络进行特征提取,比较不同网络参数量,运行速度,最终结果之间的差异。
- 关于特征提取网络的输出,论文中给出原尺寸缩小16倍的和缩小8倍的,两者结构差异**仅在缩小16倍的Entry Flow中有一个模块strides=(2, 2)**,性能差异不大,但是缩小8倍的网络参数量大大增加。在实战中,数据集的尺寸较小,因此我选择了缩小8倍的网络参数,小伙伴们在使用时可以酌情修改。
- 图像输入可以先将其归一化到0-1之间或者-1-1之间,因为网络的参数一般都比较小,所以归一化后计算方便,收敛较快。
- 实际的工程应用中,常常还需要对数据集进行大小调整和增强,在这里为了简单起见,没有进行复杂的操作,小伙伴们应用中要记得根据自己的需要,对图像进行resize或者padding,然后旋转,对比度增强,仿射运算等等操作,增加模型的鲁棒性,并且实际中的图像不一定按照顺序命名的,因此应用中也要注意图像读取的文件名。
完整实战代码
1 | import os |
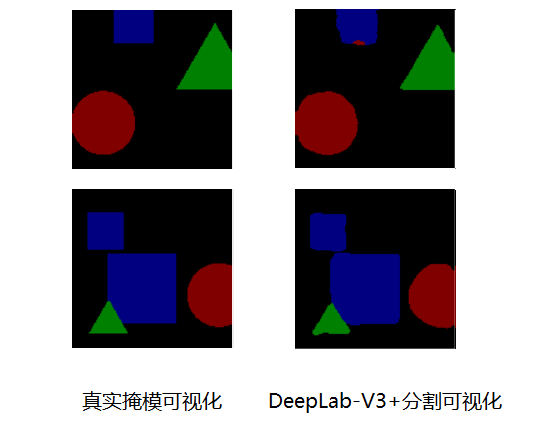
模型运行结果
DeepLab-V3+小结
DeepLab-V3+是一种高效的语义分割网络,从上图可以看出DeepLab-V3+模型的参数量只有41M,就目前来说,DeepLab-V3+是语义分割公认的最高峰,主要来源于ASPP网络结构和深浅层特征融合,是小伙伴们需要掌握的一个模型。