背景介绍
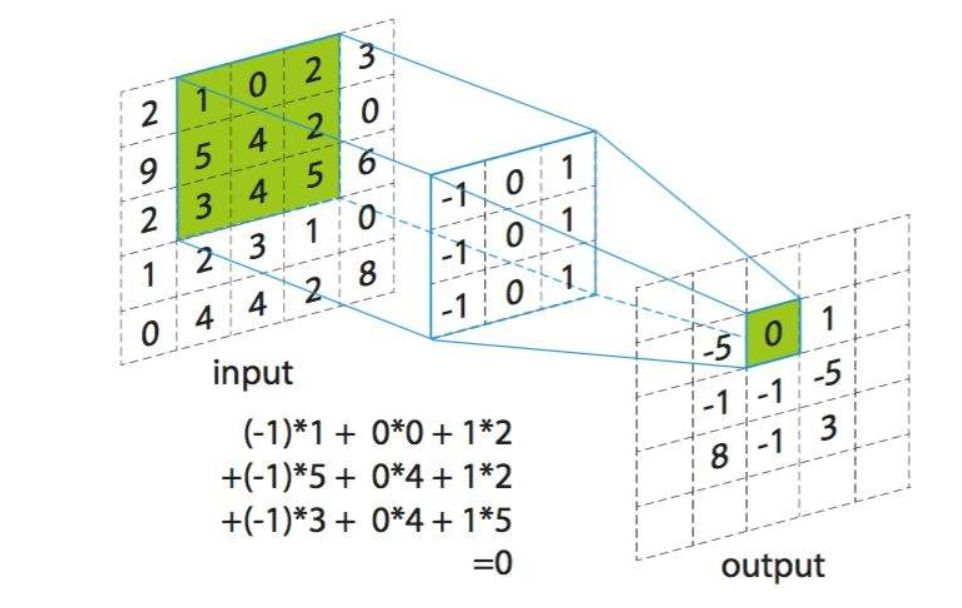
Convolution:在这个博客中,我们谈论的卷积并不是实际意义中的卷积,而是神经网络中的卷积。小伙伴们可能会有疑问,两个卷积有区别吗?学过信号处理或者图像处理的小伙伴们应该很熟悉,卷积是要首先将核翻转180°,然后再应用于信号或者图像上,而相关则不需要翻转。因此神经网络中的卷积实际上是一种相关操作。
Receptive Field感受野
在二维卷积中不得不提到一个重要名词:感受野,在这里我只是作为科普,说一说感受野和二维卷积的关系,不从生命科学的角度具体描述感受野和神经元的关系,感兴趣的小伙伴可以去网上搜索。
想象一下,当我们看一场足球比赛,或者看一场精彩的电影时,我们的注意力集中于某个点,比如足球的运动轨迹,电影中任务的细节描写。我们的眼睛只是关注一个像素吗?答案是否定的,我们关注的是周围了一部分区域,这个区域可以称之为感受野。当我们看这个人的眼神细节时,我们还会注意到面部的动作,而很难注意到耳朵或者其他部位的变化。而卷积操作也是相同,对于某个中心点求卷积,只是计算这个点周围的值,而不去计算距离很远的像素点。意在让计算机根据人类的视觉行为做出类似的判断。
CNN卷积神经网络
CNN是目前深度学习领域中非常具有代表性的神经网络之一,在图像分析和处理领域取得了众多突破性的进展,包括图像识别,语义分割,目标检测等等。
关于卷积的计算过程,小伙伴们应该都比较了解,通过最上面的图也可以直观的看出。随着CNN的发展,尤其是2012年AlexNet网络在ImageNet上大放异彩以后,卷积神经网络持续火爆。渐渐的一些黑科技卷积也被陆续发现。这个博客目的是向大家介绍各种卷积之间的差异。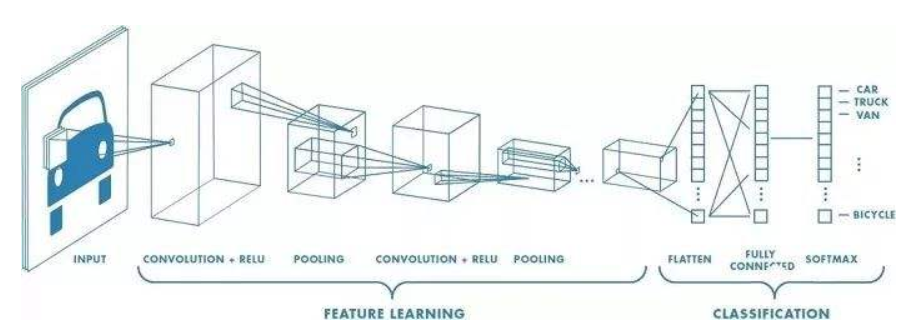
Depthwise Convolution
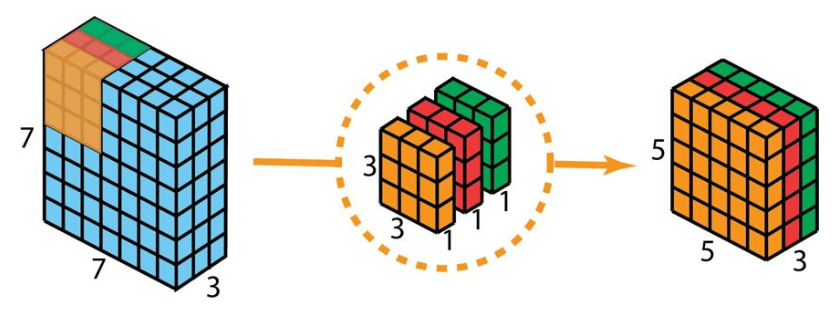
Depthwise Convolution(深度卷积):在每一个通道上单独进行卷积
参数depth_multiplier默认为1,代表每个通道数进行一次单独卷积,输出的通道数和输入通道数相等,设置depth_multiplier=n,则代表每个通道数进行n次单独卷积,输出通道数是输入通道数的n倍。
主要作用是大大降低网络的参数量,主要用于轻量级深度学习网络,在MobileNet,EfficientNet,ShuffleNet网络中都有大量使用。如果一个8x8x1024的特征图,经过5x5的卷积核后变为8x8x1024的图像,经过普通卷积的参数量为1024x(1024x5x5+1)=26215424,而深度卷积参数量为1024x(1x5x5+1)=26624,参数量缩小了约1024倍。
Pointwise Convolution
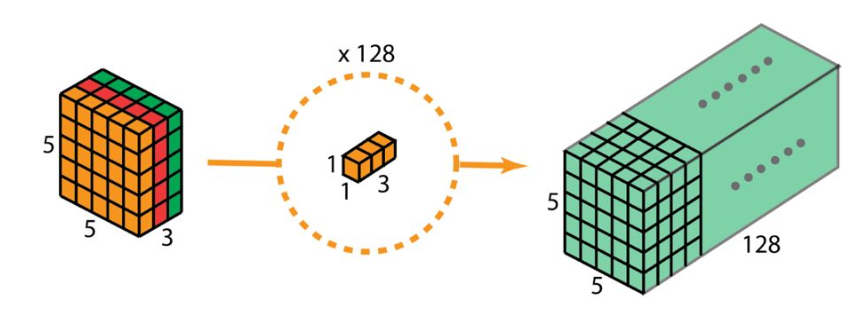
**Pointwise Convolution(点卷积)**:很好理解,卷积核的大小为1x1,小伙伴们可能产生疑问?1x1卷积有什么作用呢?
- 改变通道数,可以实现升维或者降维,在ResNet,MobileNet网络中有重要作用。
- 增加非线性关系,在保持特征图尺度的前提下,可以利用非线性激活函数增加网络深度。
- 实现跨通道信息交互,往往和Depthwise Convolution结合使用。
Separable Convolution
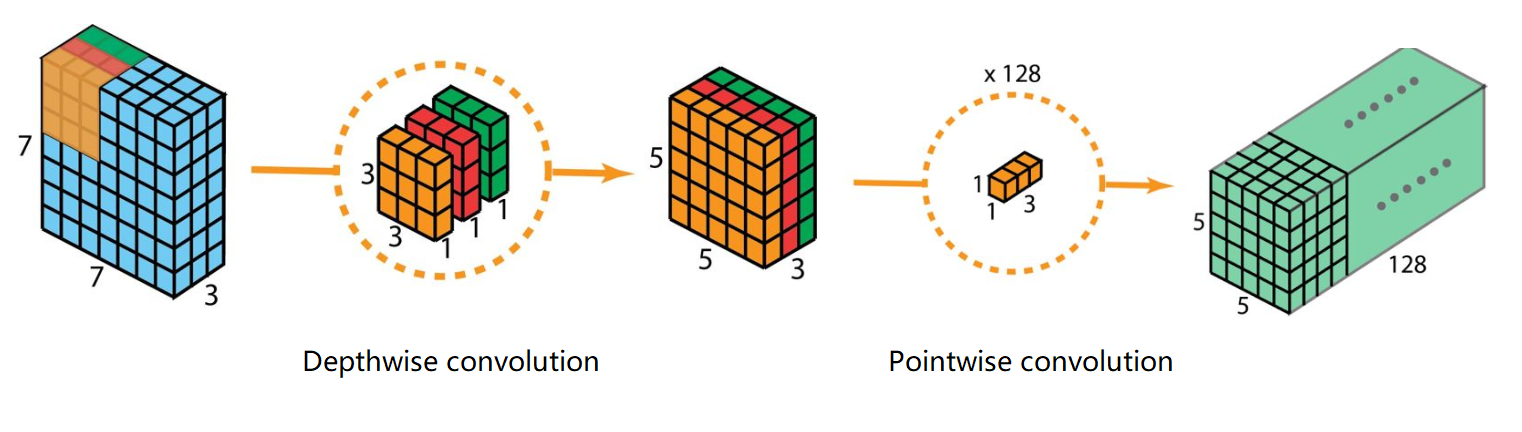
Separable Convolution(深度可分离卷积):是上面两个卷积合二为一的卷积操作。
第一步:DepthwiseConv,对每一个通道进行卷积
第二步:PointwiseConv,对第一步得到的结果进行1x1卷积,实现通道融合
主要作用是大大降低网络的参数量,并且可以调整为任意合适的通道数,在Xception,MobileNet,EfficientNet,ShuffleNet网络中有大量使用。第一步的目的是减少参数量,第二步是调整通道数,因此将两个卷积操作结合,组成深度可分离卷积。
Spatial Separable Convolution
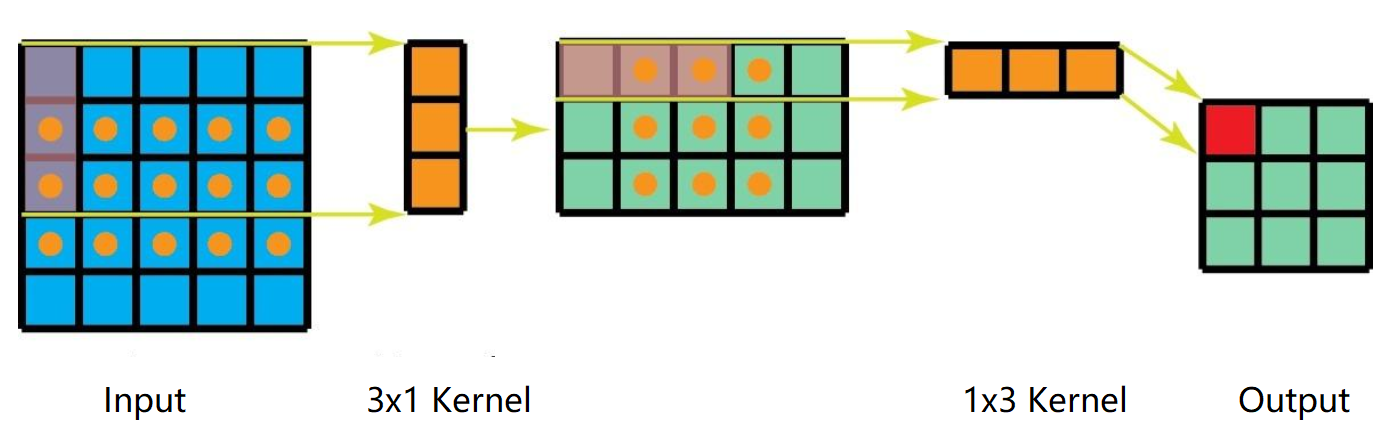
Spatial Separable Convolution(空间可分离卷积):将3x3的卷积分解为3x1的卷积核1x3的卷积,将7x7的卷积分解为7x1的卷积核1x7的卷积.。
主要作用是大大降低网络的参数量,在Inception类型的网络中有大量使用。如果一个64x64x256的特征图,经过7x7的卷积核后变为64x64x256的图像,经过普通卷积的参数量为256x(256x7x7+1)=3211520,而空间可分离卷积参数量为2x256x(256x7x1+1)=918016,参数量缩小了约3.5倍。
Atrous Convolution
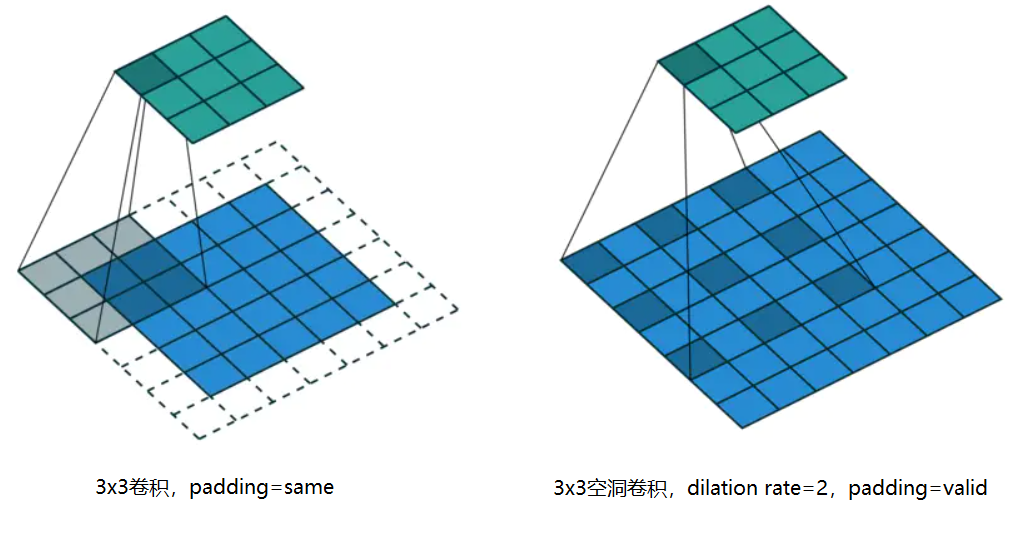
Atrous Convolution(空洞卷积):又称膨胀卷积(Dilated Convolution),在卷积层引入了一个膨胀率(dilation rate)参数,定义了卷积核的间隔数量,普通卷积的卷积核dilation rate=1。
优点:扩大感受野,相邻的像素点可能存在大量冗余信息,扩大感受野可能会获取多尺度信息,这在视觉任务上非常重要,且不需要引入额外参数,如果增加分辨率或者采用大尺寸的卷积核则会大大增加模型的参数量,在PSPNet,DeepLab-V3+网络中有大量使用。
缺点:由于空洞卷积的计算方式类似于棋盘格式,因此可能产生棋盘格效应,可以参考棋盘格可视化。如果膨胀率太大卷积结果之间没有相关性,可能会丢失局部信息。
Group Convolution
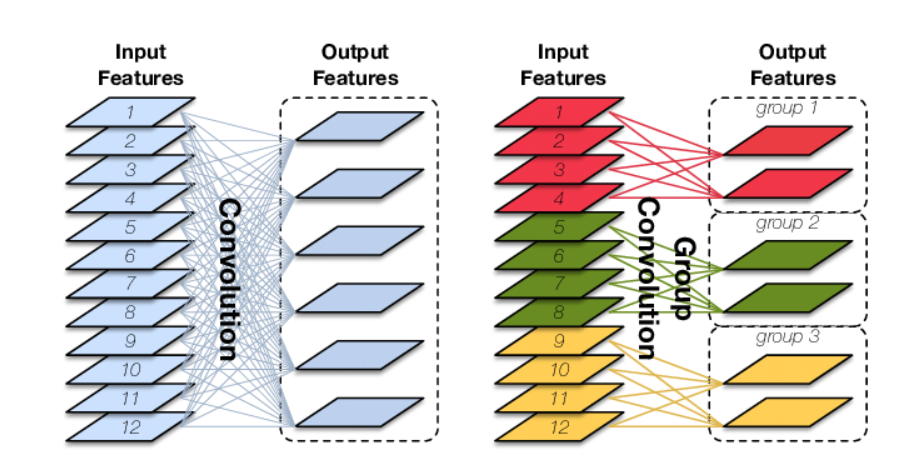
Group Convolution(分组卷积):传统卷积是采用一种卷积全连接的思想,特征图中的每一个像素点都结合了图像中所有通道的信息。而分组卷积特征图像每一个像素点只利用到一部分原始图像的通道。
主要作用是大大降低网络的参数量,在ResNeXt,ShuffleNet-V2网络中有大量使用。如果一个64x64x256的图像,经过5x5的卷积核后变为64x64x256的图像,经过普通卷积的参数量为256x(256x5x5+1)=1638656,而分成32组的分组卷积的参数量为256x(8*5x5+1)=51456,参数量缩小了约32倍,当组数变成通道数时,则类似于Depthwise Convolution深度卷积
Deconvolution
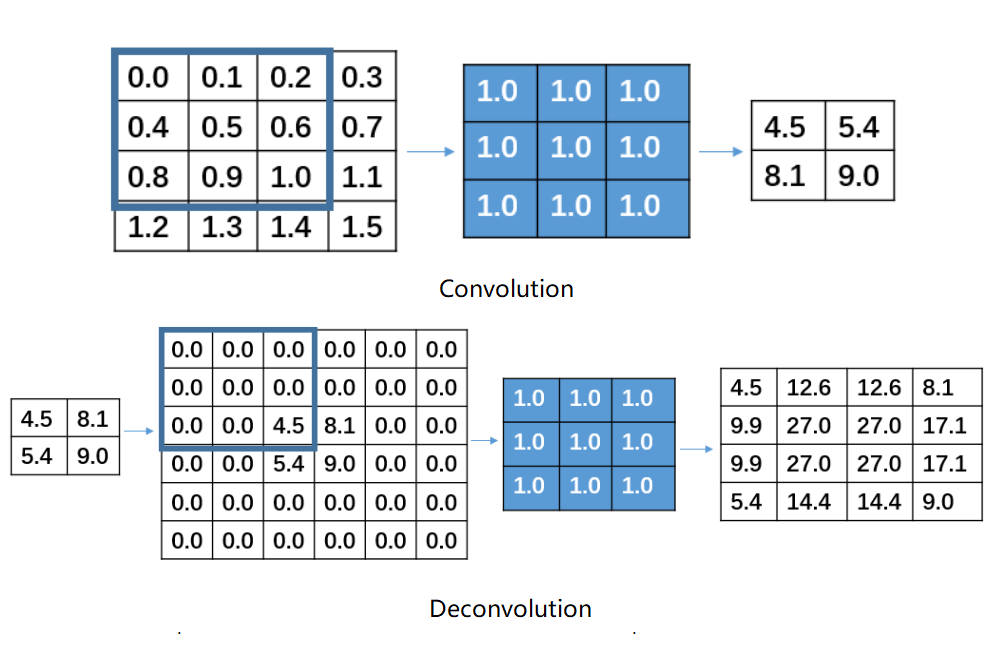
Deconvolution(反卷积):本质是卷积,注意反卷积并不能从卷积的结果返回到卷积前的数据,只能返回到卷积前的尺寸。卷积通过设置kernel_size卷积核大小,strides步长和padding填充方式可以将图像的分辨率降低,相反的反卷积可以通过设置kernel_size卷积核大小,strides步长和padding填充方式先对数据进行填充,然后再进行卷积操作,可以将图像的分辨率增加。**这个方法不推荐经常使用,因为存在大量参数,而且可能会存在棋盘格效应,可以参考棋盘格可视化**。
Squeeze-and-Excitation
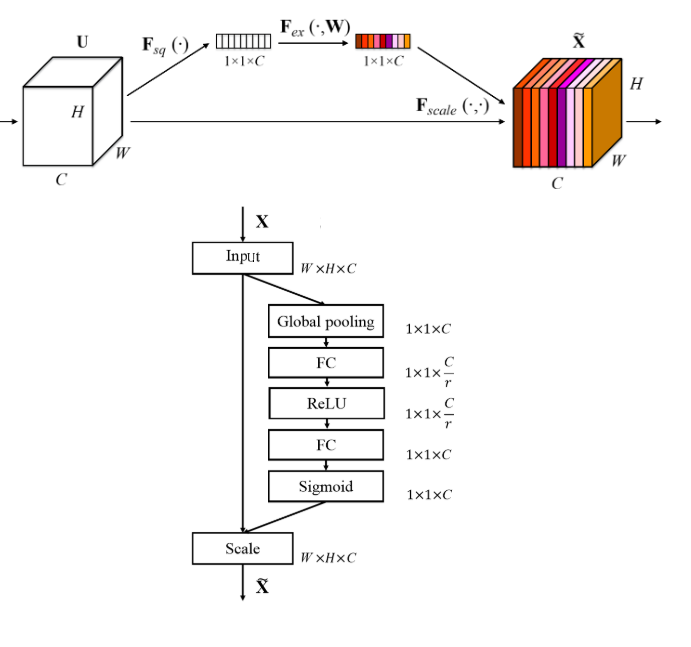
Squeeze-and-Excitation:又称为特征重标定卷积,或者注意力机制。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征,在SENet,MobileNet-V3,EfficientNet网络中有大量使用。
首先是 Squeeze操作,先进行全局池化,具有全局的感受野,并且输出的维度和输入的特征通道数相匹配,它表征着在特征通道上响应的全局分布。
然后是Excitation操作,通过全连接层为每个特征通道生成权重,建立通道间的相关性,输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
小结
卷积操作是CNN的核心,因此在学习时常常会和它们打交道,因此系统的学习各种卷积的优缺点以及利用场景,对今后的学习工作是非常有帮助的,希望小伙伴们都可以学习和掌握。