背景介绍
Normalization(标准化):深度神经网络模型训练困难,其中一个重要的现象就是ICS(Internal Covariate Shift,内部协变量偏移),其中解决的方法就是Normalization,现在标准化成为深度学习必备神器,今天带小伙伴们看一看,瞧一瞧。
ICS的解释
ICS(Internal Covariate Shift,内部协变量偏移):将神经网络的每一层的输入作为一个分布来看代,由于神经网络的参数是随机的,因此可能会导致相同的输入分布却得到了不同的输出分布。随着网络层数的加深,输入分布再经过多次非线性变换后,已经被改变,但是其标签还是一致的,这就有一种不协调的感觉,这可能会带来下面几种问题。
- 在训练的过程中,网络需要不断适应新的输入数据分布,所以会大大降低学习速度。
- 由于参数的分布不同,所以可能导致很多数据落入饱和区,使得学习过早停止。
- 某些参数分布偏离太大,对其他层或者输出产生了巨大影响。
Normalization原理分析
为了解决上述ICS问题,我们需要将变量分布变成相同分布的,这使我们想到了标准化操作。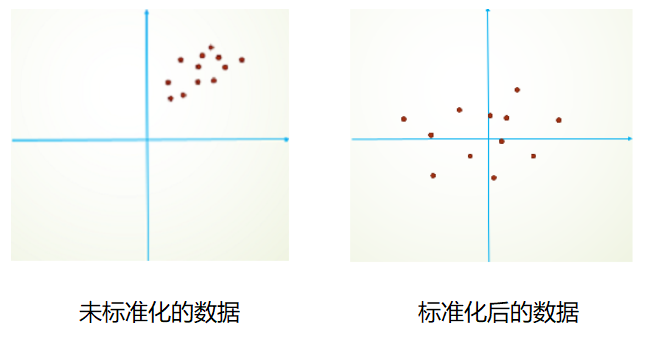
- 我们可以通过$ \hat{x} = \frac{x - \mu}{\sigma} $,$ \mu $是平移参数,$ \sigma $是缩放参数将数据变成符合均值为0,方差为1的标准分布。
- 我们再通过$ y = \gamma \cdot \hat{x} + \beta $, $ \beta $是再平移参数,$ \gamma $是再缩放参数将数据变成符合均值为$ \beta $,方差为$ {\gamma}^2 $的标准分布。
奇怪的知识增加了???为什么第一步得到标准分布之后,第二步又给变走了?
是这样的,首先为了保证模型的表达能力不因为规范化而下降,如果没有再平移和缩放,会导致输入的参数分布可能发生较大的变化,这样可能会对模型的表达能力产生影响。其次这两组参数是意义上完全不同的概念,**$ \mu $和$ \sigma $受到上一层输入的影响,$ \beta $和$ \gamma $是独立的,与输入无关,是网络后来加入的,会在接下来训练过程中不断学习的,也是为了尊重神经网络的学习结果**。因此这两步是有必要的。
Normalization优点
- 解决了ICS(Internal Covariate Shift,内部协变量偏移)问题。
- 加快学习速度,防止梯度消失现象,因为标准化后,会将数据拉回到0附近,对于Sigmoid,tanh激活函数来说,可能就会从饱和区拉回到线性区,因此可以防止梯度消失现象。
- 减弱对初始化的依赖性,因为参数需要进行标准化,所以初始化参数时,不用限制较大。
- 可以对抗over fitting,因为会将输入进行变化,当输入导致均值产生偏移,没关系,后面还有Normalization,会对偏移进行修正,所以会起到一些防止过拟合的作用。
常见的Normalization
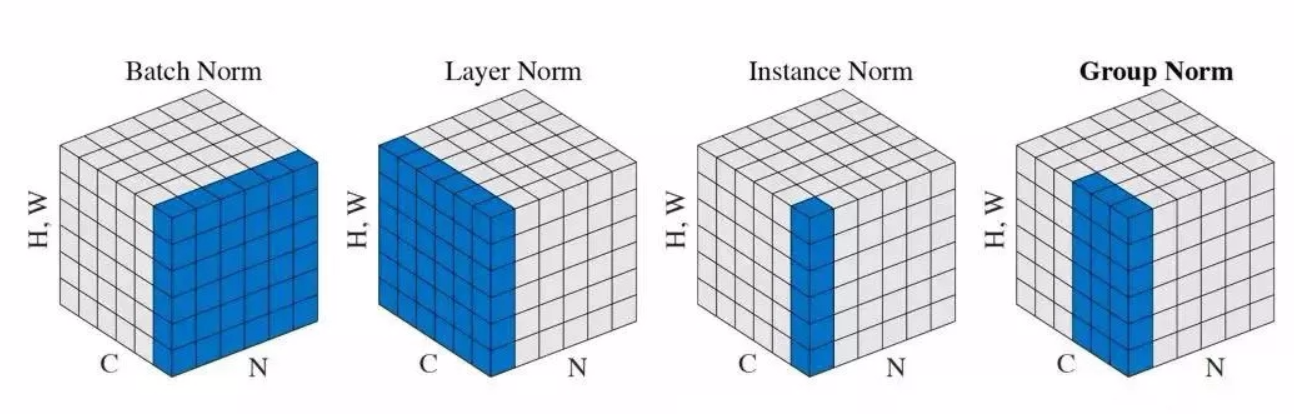
为了说明的清晰,我们将输入的feature map shape记为[N, H, W, C],其中N代表batch_size,H,W代表特征图的高和宽,C代表特征图的通道数。
并且为了直观说明,将feature map看作一个学校,N代表年级数量,规定值为3,C代表每个年级的班级数量,规定值为6,H和W代表班级的每一排和每一列,规定值都为10。
BN(Batch Normalization,2015)
BN(Batch Normalization):保留通道的维度C,对N,H,W做C次标准化,相当于分别按照班级将所有年级所有同学的成绩进行标准化(如一年级一班,二年级一班,三年级一班的所有同学进行标准化,然后再将一年级二班,二年级二班,三年级二班的所有同学进行标准化,直到将一年级六班,二年级六班,三年级六班的所有同学进行标准化,一共做了6次标准化)。batch_size越大,效果越好,适合固定深度的前向神经网络,如CNN,不适用于RNN。
自定义BN层
在TensorFlow2.0中已经给我们提供了BN层的类keras.layers.BatchNormalization,使用时直接调用即可,这里也给出了自定义BN层的方法。
1 | import tensorflow as tf |
LN(Layer Normalization,2016)
LN(Layer Normalization):保留batch_size的维度N,对H,W,C做N次标准化,相当于分别按照年级将所有班级所有同学的成绩进行标准化(如一年级一班,一年级二班直到一年级六班的所有同学进行标准化,然后再将二年级一班,二年级二班直到二年级六班的所有同学进行标准化,最后将三年级一班,三年级二班直到三年级六班的所有同学进行标准化,一共做了3次标准化)。通道数越大,效果越好,不依赖batch_size的大小,适合深度不固定的网络,如RNN,不适用于CNN。
自定义LN层
在TensorFlow2.0中已经给我们提供了LN层的类keras.layers.LayerNormalization,使用时直接调用即可,这里也给出了自定义LN层的方法。
1 | import tensorflow as tf |
IN(Instance Normalization,2017)
IN(Instance Normalization):保留batch_size的维度N和通道的维度C,对H,W做NxC次标准化,相当于分别按照年级和班级将所有同学的成绩进行标准化(如一年级一班的所有同学进行标准化,一年级二班的所有同学进行标准化,直到一年级六班的所有同学进行标准化,然后再将二年级一班的所有同学进行标准化,二年级二班的所有同学进行标准化,直到二年级六班的所有同学进行标准化,最后将三年级一班的所有同学进行标准化,三年级二班的所有同学进行标准化,直到三年级六班的所有同学进行标准化,一共做了18次标准化)。最初用于生成式对抗网络中的风格迁移,生成结果依赖于某个图像实例,只对特征图的高和宽进行标准化,保持图像实例之间的独立。
自定义IN层
在TensorFlow2.0中没有提供IN层的类,需要自己定义,这里也给出了自定义IN层的方法。
1 | import tensorflow as tf |
GN(Group Normalization,2018)
GN(Group Normalization):为了解决BN中对较小batch_size效果较差的问题,将通道数C分为G组,每组有C/G个通道数,然后将这些通道数中的元素标准化,做NxC/G次标准化,如果将班级数量分为2组,相当于分别按照年级先将班级分为2组,一共分成6组,然后对所有组所有同学的成绩进行标准化(如一年级一班,一年级二班,一年级三班的所有同学进行标准化,一年级四班,一年级五班,一年级六班的所有同学进行标准化,然后再将二年级一班,二年级二班,二年级三班的所有同学进行标准化,二年级四班,二年级五班,二年级六班的所有同学进行标准化,最后将三年级一班,三年级二班,三年级三班的所有同学进行标准化,三年级四班,三年级五班,三年级六班的所有同学进行标准化,一共做了6次标准化)。分组之后,不依赖batch_size的大小,因此不会被batch_size约束。
自定义GN层
在TensorFlow2.0中没有提供GN层的类,需要自己定义,这里也给出了自定义GN层的方法。
1 | import tensorflow as tf |
小结
虽然自定义标准化层看起来非常复杂,其实本质代码只有call函数中的几行而已,而且根据不同的Normalization,只需要修改求均值和方差的轴即可。**Normalization是卷积神经网络的Trick(小技巧)**,自从Normalization被提出以后,几乎各个网络都能看到它的身影,灵活掌握不同Normalization,是小伙伴们需要达成的目标。