背景介绍
Transfer learning(迁移学习):是一种常见的机器学习方法,概括的说就是将一个预训练的模型重新用在另一个任务上。其在深度学习问题上是非常受欢迎的,因为深度学习很大的一个问题就是数据集不够,神经网络的参数量少说几百万,多则上亿,因此对于数据量的要求也是十分巨大的,但是实际的问题往往很难找到足够数量的数据集,除了数据增强方法外,还可以利用迁移学习的思想。以分类问题为例,前面的卷积层和池化层的目的是特征提取,后面全连接层的目的是进行分类。因此如果我们有很好的特征提取参数,那么我们就不需要浪费太多数据集在特征提取部分,我们重点训练网络的后半部分即可。
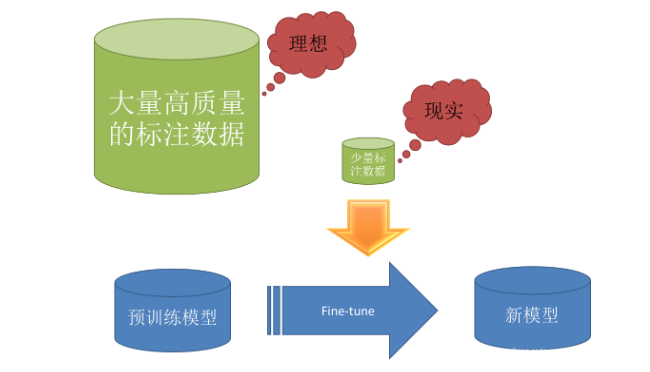
迁移学习实现
要完成迁移学习,首先两个任务要有一部分相同的网络结构,通常是前半部分的特征提取网络结构。在这里中使用TensorFlow中自带手写数字数据集mnist和时装数据集fashion_mnist为例,说明迁移学习的实现过程。
迁移学习步骤如下:
- 设要解决的问题为Q1,找到与要解决的问题类似并且有较多的数据集的问题为Q2,首先设计一个解决问题Q2的网络结构,使用Q2的数据集,训练好后将模型的权重保存。
- 设计一个解决问题Q1的网络结构,将相同的层给予相同的名称,加载权重时,调用load_weights()函数,其中参数by_name赋值为True,即根据名称加载对应的权重,名称不相同的层则不加载权重。
- 训练时可以使用较大的学习率,而且让model.layers[i].trainable = False,冻结前面的特征提取网络,因为相似的问题具有相似的特征提取权重,不会偏差太大,如果一开始就一起训练,则可能会使特征提取网络的权值产生较大的变化,浪费训练周期和数据集。
- 训练一段时间后,使用较小的学习率,并将前面的特征提取网络解冻model.layers[i].trainable = True,为了更好的提取出适合于本问题的特征,再训练一定的时间,即可完成整个迁移学习过程。
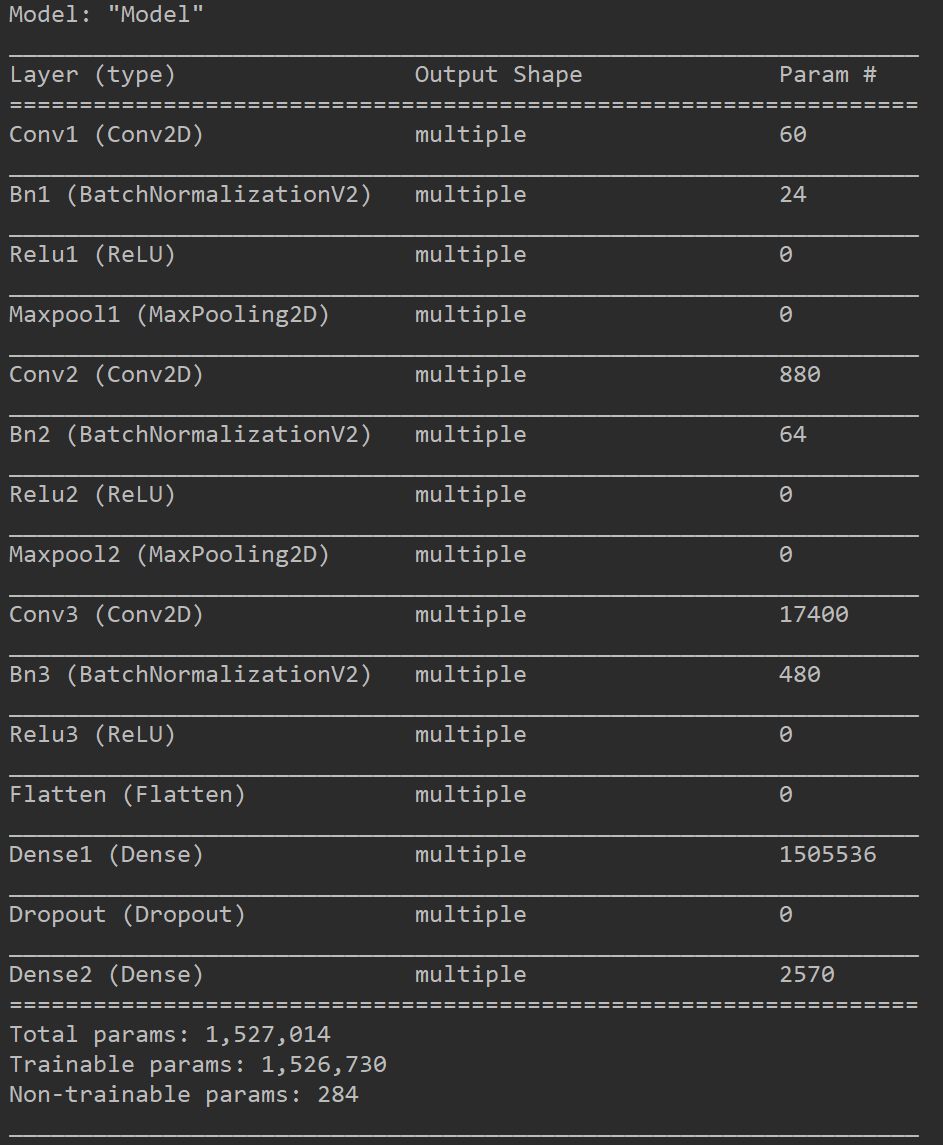
第一部分,获取相似问题的权重
设计一个解决时装分类问题的网络模型,因为类别较少,因此网络模型较小,主要是为了说明迁移学习的过程。模型的参数保存在fashion_mnist.h5文件中,实际的代码如下。
1 | import tensorflow as tf |
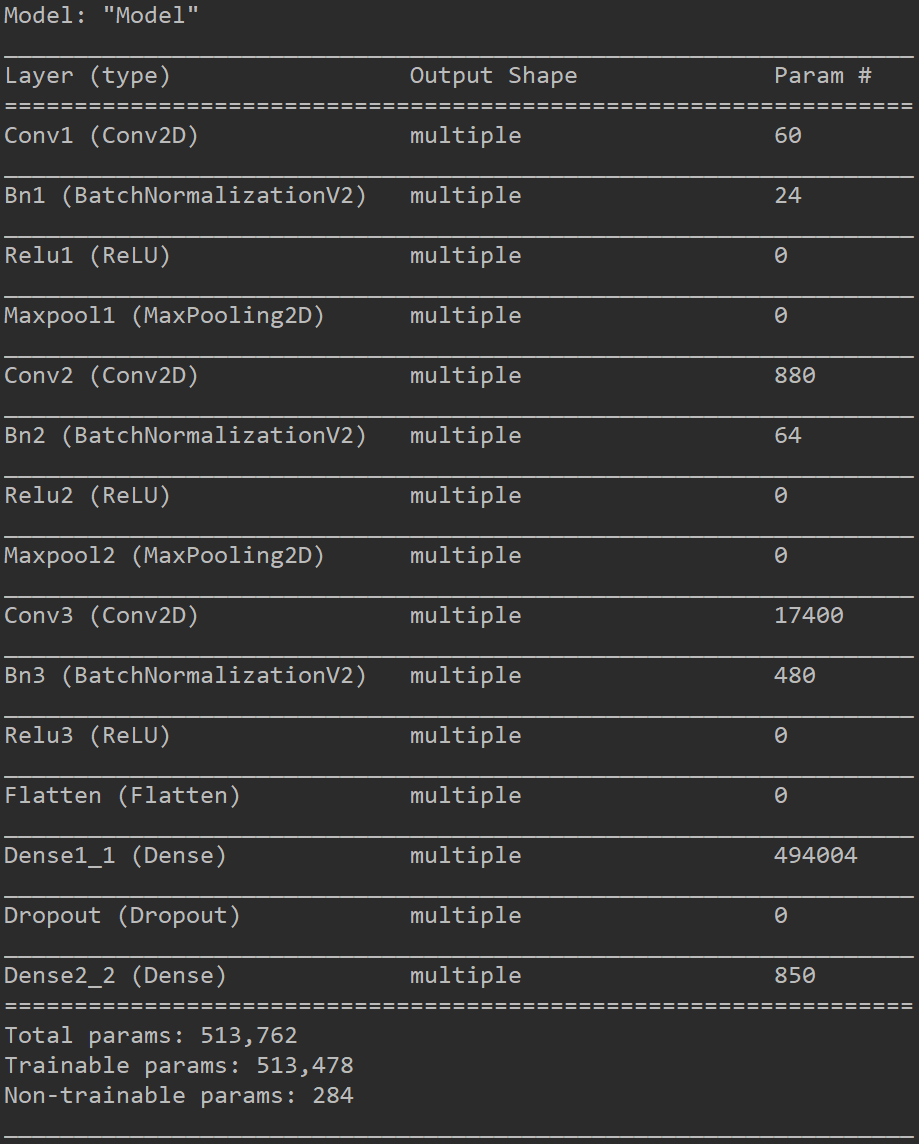
第二部分,加载第一部分的权重,并且训练本问题
设计一个解决手写数字分类问题的网络模型,手写数字比时装分类问题简单一些,因此特征提取网络不变,只改变最后两层全连接层的参数,实际的代码如下。
1 | import tensorflow as tf |
使用迁移学习与不使用迁移学习的对比
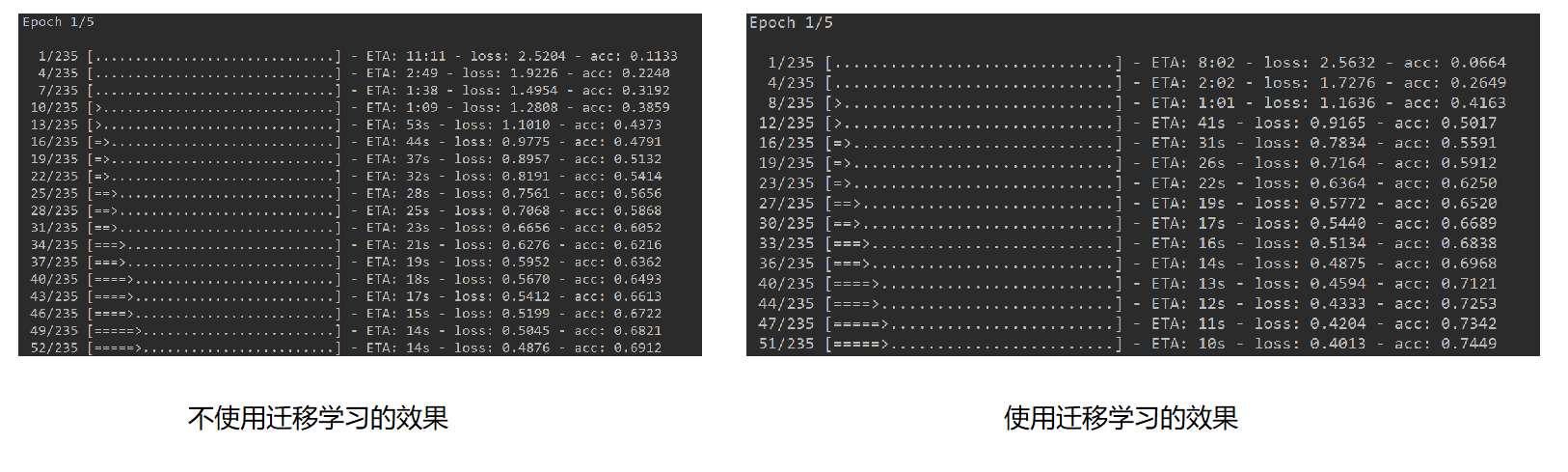
- 从上图可以明显的看出,使用了迁移学习之后,模型训练的速度大大加快了,因为利用相似问题的特征提取网络权值,只训练最后的分类网络,因此模型的收敛更加迅速。
- 因为mnist数据量并不是很少,而且分类任务比较简单,因此在很长时代的训练下,迁移学习的优势并不是很明显,在其他的复杂问题上,尤其是数据量较少的情况,效果非常明显。
小结
迁移学习不是一种算法,更多的是一种思想,一种将现有的信息借鉴过来的迁移思想,使得我们的少量数据集可以发挥更大的效果。因此在工程实际问题中常常使用,小伙伴们必须要掌握它。