背景介绍
Callbacks(回调函数):指在网络学习期间,对网络的性能,参数等进行修改,保存,显示,早停等一系列操作。不是深度学习必须使用的,但是掌握回调函数可以更好的让网络为我们服务,下面来具体了解一下有哪些常用的回调函数。
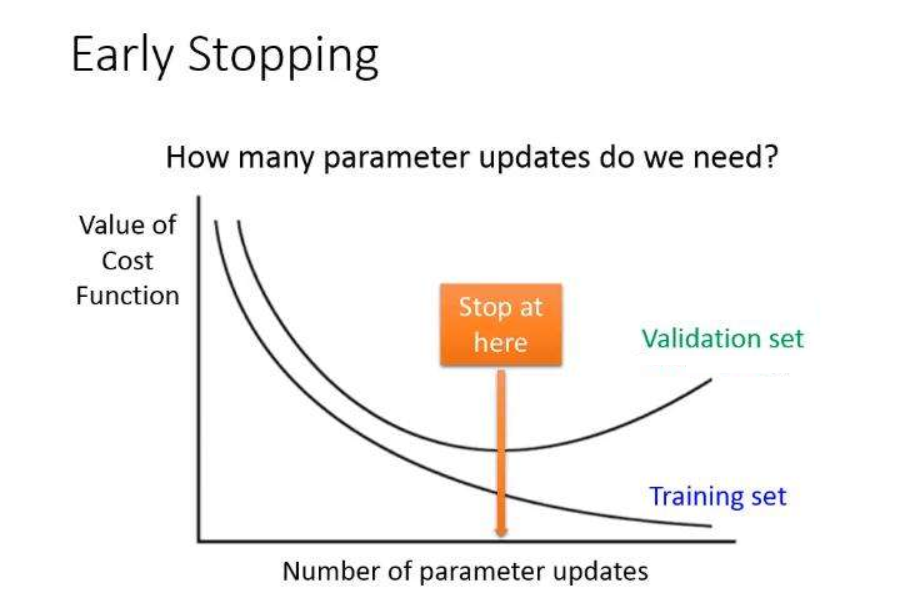
Early Stopping(早停)
在深度学习任务中,早停是提升模型性能的一个有效方法,随着训练的进行,模型在训练集和测试集上的性能会逐渐提高,但是在训练一定的周期后,我们常常会发现训练集上的准确率仍在增加,而且损失函数在减小,但是测试集上的准确率和损失函数却在某个值附近发生波动,甚至会降低准确率。这种情况我们会认为发生了Overfitting(过拟合),即模型学的太像了,把训练集中的一些特殊情况也学习进去了。举个简单的例子,我们学习认识一只老虎时,如果这只老虎是一只幼崽,我们学习的太像了,就会认为老虎就应该是那么大,当测试时,来了一只猫,我们就会当成是老虎,这就是Overfitting的简单理解。
想解决Overfitting,有很多种方法,最暴力的方法是增加数据集,还可以引入正则项,减小模型的参数,以及早停。早停是一种简单的解决Overfitting的方法,当模型的验证集已经发生波动时,我们就认为发生了过拟合,因此停止网络的学习,防止其学到过多训练集的特性。
在TensorFlow中在keras.callbacks中已经给我们提供了EarlyStopping的类,其常用参数主要有:
- monitor:监视的值,默认为val_loss,当验证集的损失函数不下降时停止学习。
- min_delta: 监视值的最小变化,默认为0,即只要损失函数降低则视为有改进。
- patience: 没有改进的周期数,如果连续patience个周期都没有改进,则停止学习。
- verbose:是否在训练过程中详细显示。
1
2
3
4import tensorflow.keras as keras
early_stopping = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=5, verbose=1)
Check Point(检查点)
为了对比各个训练周期的效果,我们可以将模型按照训练迭代周期进行保存。在TensorFlow中在keras.callbacks中已经给我们提供了ModelCheckpoint的类,其常用参数主要有:
- filepath:保存模型文件的路径。
- monitor: 监视的值,默认为val_loss。
- verbose:是否在训练过程中详细显示。
- save_best_only: 是否只保存最佳模型。
- period:每个period个周期检查一次是否需要保存。
1
2
3
4import tensorflow.keras as keras
check_point = keras.callbacks.ModelCheckpoint(weight_path + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5', monitor='val_loss', verbose=1, save_best_only=True, period=3)
CSV Logger(CSV记录器)
为了使我们能够直观方便的看到各个训练周期下模型的评价指标和损失函数,在TensorFlow中在keras.callbacks中已经给我们提供了CSVLogger的类,能够将各个训练周期的模型指标保存在csv文件中,其常用参数主要有:
- filepath:保存csv文件的文件名。
- separator: 用于分隔csv文件中元素的分隔符,默认为’,’,一般不要修改。
- append:是否在文件后面追加,如果为True则追加,如果为False则覆盖,默认为False。
1
2
3
4import tensorflow.keras as keras
log_csv = keras.callbacks.CSVLogger(filename=csv_path)
Tensorboard
为了能够可视化我们的模型,以及了解数据流图的结构,在TensorFlow中在keras.callbacks中已经给我们提供了TensorBoard的类,能够在本地Web浏览器对网络参数,数据流图进行可视化,其常用参数主要有:
- log_dir: 用来保存Tensorboard的日志文件等内容的位置。
- histogram_freq: 用来计算各个层的激活值和模型权重直方图。
- **write_graph: 是否在TensorBoard中可视化图形(数据流图)**。
- pdate_freq:batch或epoch或整数,默认为epoch。使用batch,每批之后将损失和指标写入TensorBoard。epoch同理。如果使用整数,假设1000,回调将每1000个样本将指标和损失写入TensorBoard,但是向TensorBoard写入太频繁会减慢训练速度。运行后日志文件会保存在log_dir中,然后在cmd命令行中运行tensorboard –logdir=path(log_dir的绝对路径即可,也可以使用相对路径),然后会出现一个本地的Web网址,复制并在浏览器中打开即可完成可视化工作。
1
2
3
4import tensorflow.keras as keras
log_board = keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1, write_grads=True)
想了解更多关于Tensorboard的使用方法,可以参考我的另一篇博客TensorBoard黑科技,专门对TensorBoard的使用进行讲解,除了使用keras.callbacks模块下的类,还有一些其他的方法写入TensorBoard。
Reduce LR(学习率下降)
在训练过程中,往往在初始阶段使用较大的学习率,方便模型的收敛和跳出局部极小值点,而在训练后期学习率需要降低来细化我们的模型,降低损失函数,提高模型评价指标。在TensorFlow中在keras.callbacks中已经给我们提供了ReduceLROnPlateau的类,能够在训练过程中,自适应地调整学习率,其常用参数主要有:
- monitor:监视的值,默认为val_loss。
- factor:学习率下降因子,new_lr = lr x factor。
- patience:没有改进的周期数,如果连续patience个周期都没有改进,则下降学习率。
- min_lr:设置最低学习率,防止学习率过低。
1
2
3
4import tensorflow.keras as keras
reduce_lr = keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.25, patience=3, verbose=1)
想了解更多关于学习率下降的使用方法,可以参考我的另一篇博客Learning Rate黑科技,专门对学习率下降的使用进行讲解,除了使用ReduceLROnPlateau,还有一些其他的方法可以自定义学习率下降的方式。
代码实战
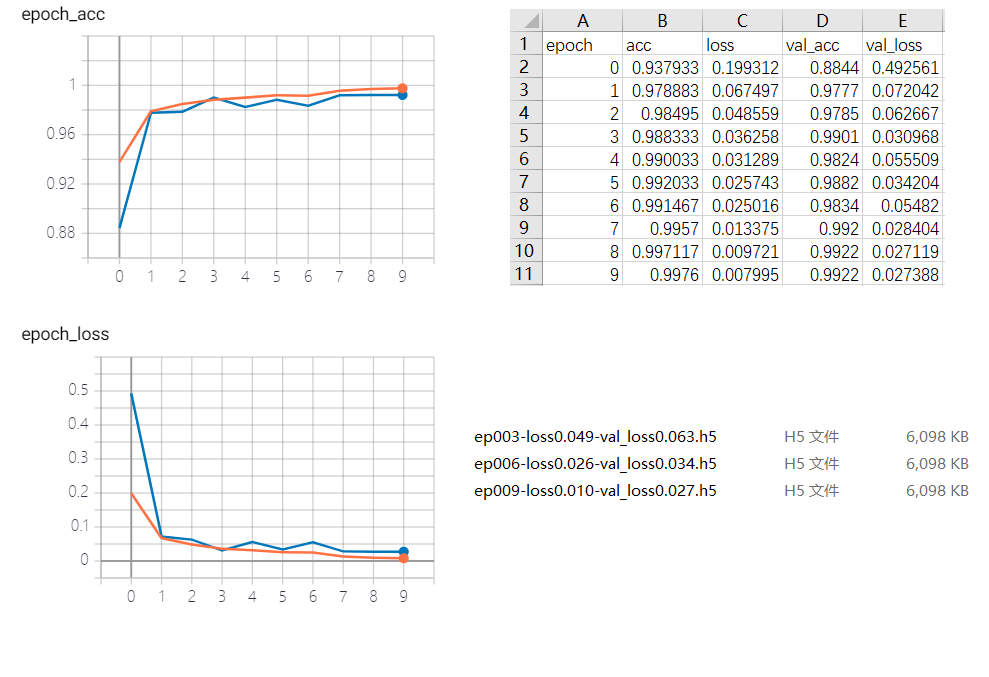
使用mnist手写数字分类作为实战,给小伙伴们演示如何使用回调函数。
1 | import datetime |
小结
回调函数是我们优化模型的重要工具,能够帮助我们更好的了解设计的模型,可以直观的看出模型需要如何改进,应该增加迭代周期还是应该早停,增加模型参数还是降低模型参数等等,要注意保存模型参数或者记录模型结果的时候,可以加入时间戳作为文件名,这样防止多次训练时产生太多文件导致分不清是哪一次训练的数据,所以小伙伴们一定要小心。