背景介绍
Regularization(正则化):简单的说就是减小测试误差的行为,我们在构建深度学习模型时,最终目的是为了让模型更好的面对测试数据,而不是训练数据。但是网络在学习的过程中很容易就出现了Overfitting(过拟合),这就导致模型的泛化能力下降,所以需要引入一些正则化的方法,降低模型的复杂度。

L1 Regularization(L1正则)
$$ J’(\omega, b) = J(\omega, b) + \frac{\lambda}{2m} \underset{i}{\sum} {|\omega_{i}|} $$
其中$m$为样本个数,$\lambda$为超参数,用于控制正则化的程度。
L1 Regularization(L1正则):是指在目标函数的后面加上系数惩罚项,L1正则对应的惩罚项为L1范数,通过让原目标函数加上了所有权重绝对值之和来实现正则化。
L1 Regularization的优点:可以起到特征选择的作用,因为在梯度更新的时候,L1正则的导数为1,每次都会加上或者减去一个常数,所以很容易产生权值为0的情况,会使特征变得稀疏。
在TensorFlow中,keras.regularizers.l1给我们提供了L1正则化的函数,在网络模型中,可以通过将正则化函数赋值给网络层的kernel_regularizer参数,达到正则化的作用。
1 | import tensorflow.keras as keras |
L2 Regularization(L2正则)
$$ J’(\omega, b) = J(\omega, b) + \frac{\lambda}{2m} \underset{i}{\sum} {\omega_{i}^{2}} $$
其中$m$为样本个数,$\lambda$为超参数,用于控制正则化的程度。
L2 Regularization(L2正则):是指在目标函数的后面加上系数惩罚项,L2正则对应的惩罚项为L2范数,通过让原目标函数加上了所有权重的平方和来实现正则化。
L2 Regularization的优点:更适合防止模型过拟合。因为在梯度更新的时候,L2正则的导数与权值成比例,因此当权值缩小后,梯度也会变小,所以使系数趋向于变小但是不为0,所以L2正则会使模型变得简单,防止过拟合。
在TensorFlow中,keras.regularizers.l2给我们提供了L2正则化的函数,在网络模型中,可以通过将正则化函数赋值给网络层的kernel_regularizer参数,达到正则化的作用。
1 | import tensorflow.keras as keras |
为什么通过L1,L2正则可以防止过拟合
首先我们讨论过拟合产生的原因,过拟合是指拟合函数要考虑到每一个点,当存在噪声时,函数值不平滑,所以只有网络权值足够大时,才能够保证一些特征的变化导致函数值发生剧烈变化。也就是说网络的权值较大,加入正则化后,为了达到较小的目标函数,会降低网络的权值,所以可以防止过拟合。
Dropout(随机失活)
Dropout(随机失活):也是一种计算方便,功能强大的正则化方法,其原理是随机将某些神经元失活,只训练剩下的节点,每次失活的神经元都不一样,相当于每次迭代都是在训练不同的网络。其目的是降低节点之间的关联性和模型复杂度,使网络不要总是依赖于某些神经元的权值,从而达到正则化的效果。
在TensorFlow中,已经给我们提供了Dropout网络层,在keras.layers模块中,使用时直接在网络的某些层加上Dropout即可,非常简单。
1 | import tensorflow.keras as keras |
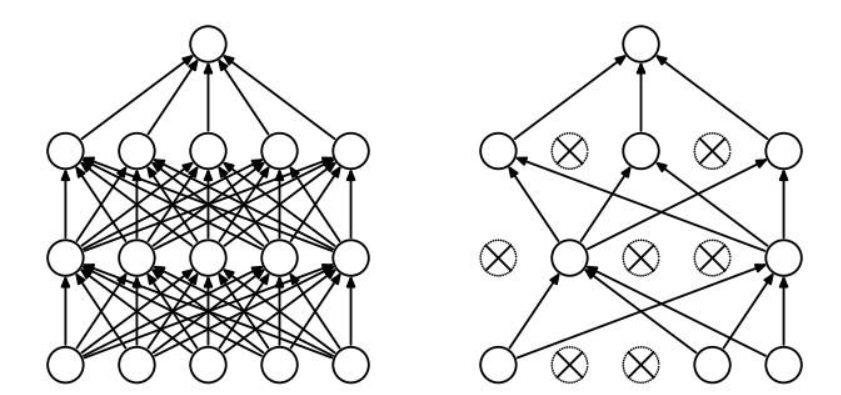
小结
深度学习中经常会出现过拟合的现象,其主要原因是深度学习网络参数量大,模型结构复杂,因此很容易就学习到一些数据特有的性质,因此就会产生过拟合,解决过拟合的方法不止Regularization和Dropout两种,还可以进行数据增强操作,使得数据变得多样化,防止模型对特定数据产生依赖,有关数据增强的内容,可以参考我的另一篇博客Data Augmentation(数据增强),里面列举了一些数据增强的常用操作。EarlyStopping(早停)也可以缓解过拟合的现象,当模型在验证集上效果出现波动,甚至下降时,我们可以考虑将模型停止学习,称之为早停,有关EarlyStopping的内容,可以参考我的另一篇博客Callbacks黑科技,在里面介绍了如何在训练中自动的监测模型的指标,并以此作为是否早停的依据。关于过拟合现象,有很多种方法可以缓解,具体如何选择,需要小伙伴们多多尝试,熟能生巧。