背景介绍
Entropy, Cross Entropy, Relative Entropy(熵,交叉熵,相对熵):在机器学习或者深度学习的过程中,避免不了与熵接触,但是熵是什么,小伙伴们是否有很多问号?感觉是那么回事,但是又无法说清楚。
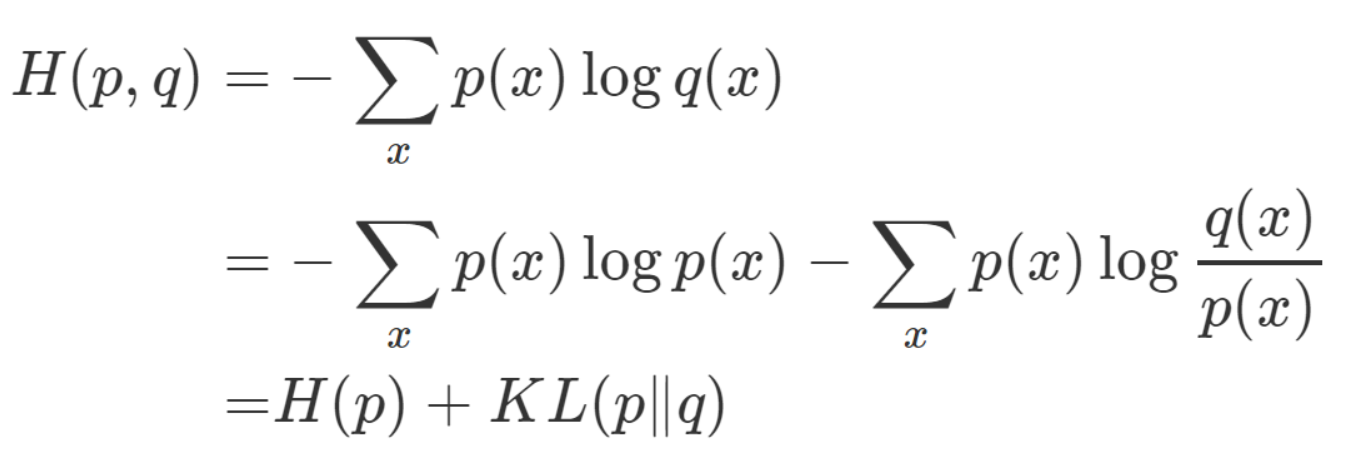
Entropy(熵)
Entropy(熵):在计算机,通信领域指的是Information Entropy(信息熵),信息熵代表随机变化或者系统的不确定性,熵越大则随机变量或系统的不确定性就越大,如何理解呢?我们可以根据分布,找到一个最优策略,信息熵就是使用最优策略衡量这个分布所花费的代价。用公式表示为
$$ H(p) = -\sum_{x}^{\ }{p(x)log_{2}(p(x))} $$
其中p为随机变化或者系统的分布函数。
举个例子说明,假如一个袋子里面有两个红球,一个白球,一个蓝球,取出一个球是什么颜色,问这个系统的信息熵为多少?计算步骤为
$$ H = -\frac{1}{2} \times log_{2}\frac{1}{2} -\frac{1}{4} \times log_{2}\frac{1}{4} -\frac{1}{4} \times log_{2}\frac{1}{4} = 1.5 $$
如何理解这个结果呢?我们按照最优策略进行代价计算,最优策略是花费一次机会猜红球,猜对了概率为0.5,如果猜错了则还需要花费一次机会猜白球或者蓝球,因此总代价为0.5 x 1 + 0.5 x 2 = 1.5。
如果有四个球,一个红球,一个蓝球,一个白球,一个黄球,则系统的信息熵则是
$$ H = -\frac{1}{4} \times log_{2}\frac{1}{4} -\frac{1}{4} \times log_{2}\frac{1}{4} -\frac{1}{4} \times log_{2}\frac{1}{4} -\frac{1}{4} \times log_{2}\frac{1}{4} = 2 $$
也很好理解,首先猜是否为红球或者蓝球,如果是,概率为0.5,再猜是否为红色,概率为0.25,所需要的代价为两次机会,其他的球同理,则总代价为0.25 x 2 x 4 = 2。
那么如果有四个球,全为红色,系统的信息熵为多少呢?
$$ H = -log_{2}1 = 0 $$
只有红球,我根本不需要任何代价就可以消除系统的不确定性,因此信息熵为0。
我第一次接触信息熵时是有点懵的,如果明天一定下雨,信息量为0,明天有50%的可能下雨,信息熵最大,等于1。是不是有点怪怪的,这不是废话吗?这对我来说有啥价值?其实不是这样,信息熵和我们的直观感觉不同,直观感觉只有确定的事情才有意义,而信息熵衡量的就是系统的不确定性,因此有种反人类的感觉。
Cross Entropy(交叉熵)
Cross Entropy(交叉熵):代表两个概率分布之间的差异性信息。如何理解呢?交叉熵就是使用预测分布的最佳策略衡量真实分布所花费的代价,这个值一定是大于等于信息熵的,用公式表示为
$$ H(p, q) = -\sum_{x}^{\ }{p(x)log_{2}(q(x))} $$
其中p为真实分布函数,q为预测分布函数。
用之前的例子说明,假如一个袋子里面有两个红球,一个白球,一个蓝球,预测结果为一个红球,两个白球,一个蓝球,问交叉熵有多少?计算步骤为
$$ H = -\frac{1}{2} \times log_{2}\frac{1}{4} -\frac{1}{4} \times log_{2}\frac{1}{2} -\frac{1}{4} \times log_{2}\frac{1}{4} = 1.75 $$
如何理解这个结果呢?我们使用预测分布的最优策略按照真实分布的概率,进行代价计算,交叉熵越低,则预测分布越接近真实分布,当两个分布相同时,交叉熵等于信息熵,因此在分类函数常常使用交叉熵作为Loss函数。
Relative Entropy(相对熵)
Relative Entropy(相对熵):又被称为KL散度(Kullback-Leibler divergence),是两个概率分布间差异的非对称性度量。如何理解呢?设两个分布分别为p和q,KL(p||q)就是按照p的最佳策略来计算p的分布所需要的代价(信息熵)与按照q的最佳策略计算p的分布所需要的代价(交叉熵)之间的差异,这个值一定是大于等于0的,用公式表示为
$$ KL(p||q) = \sum_{x}^{\ }{p(x)log_2\frac{p(x)}{q(x)}} = H(p, q) - H(p) $$
其中p为真实分布函数,q为预测分布函数。
用之前的例子说明,假如一个袋子里面有两个红球,一个白球,一个蓝球,预测结果为一个红球,两个白球,一个蓝球,问相对熵有多少?计算步骤为
$$ KL(p||q) = \frac{1}{2} \times log_2\frac{\frac{1}{2}}{\frac{1}{4}} + \frac{1}{4} \times log_2\frac{\frac{1}{4}}{\frac{1}{2}} + \frac{1}{4} \times log_2\frac{\frac{1}{4}}{\frac{1}{4}} = 0.25 $$
如何理解这个结果呢?我们使用真实分布的最优策略按照真实分布的概率,进行代价计算,得到信息熵,上面计算的结果为1.5,我们使用预测分布的最优策略按照真实分布的概率,进行代价计算,得到交叉熵,上面计算的结果为1.75,相对熵就是两者之间的差异1.75 - 1.5 = 0.25,相对熵熵越低,则预测分布越接近真实分布,当两个分布相同时,相对熵为0,在多分类问题中,信息熵等于0,因此交叉熵等于KL散度,但是因为KL散度计算较为复杂,因此一般都使用交叉熵作为损失函数,但是**KL散度在某些场景下有着交叉熵无法代替的作用,如VAE(Variational Autoencoder)**。
小结
熵是我们学习机器学习和深度学习必须要掌握的基本知识,在模型的损失函数和评价指标中经常使用,小伙伴们一定要掌握它,否则只是听别人说什么交叉熵,KL散度之乎者也的,自己完全插不上话,相信大家看了这个博客后,一定能够对熵这个家族有更深刻的理解。