背景介绍
WGAN-GP(Wasserstein Generative Adversarial Networks-Gradient Penalty):于2017年发表于NIPS,是WGAN的升级版本,WGAN理论的前提是1-Liposchitz条件,WGAN中使用的方法是权重裁剪,这不是一个非常好的办法,WGAN-GP使用了一种GP(Gradient Penalty, 梯度惩罚)的方法替代权重裁剪,构建了一个更加稳定,收敛更快,质量更高的生成式对抗网络。
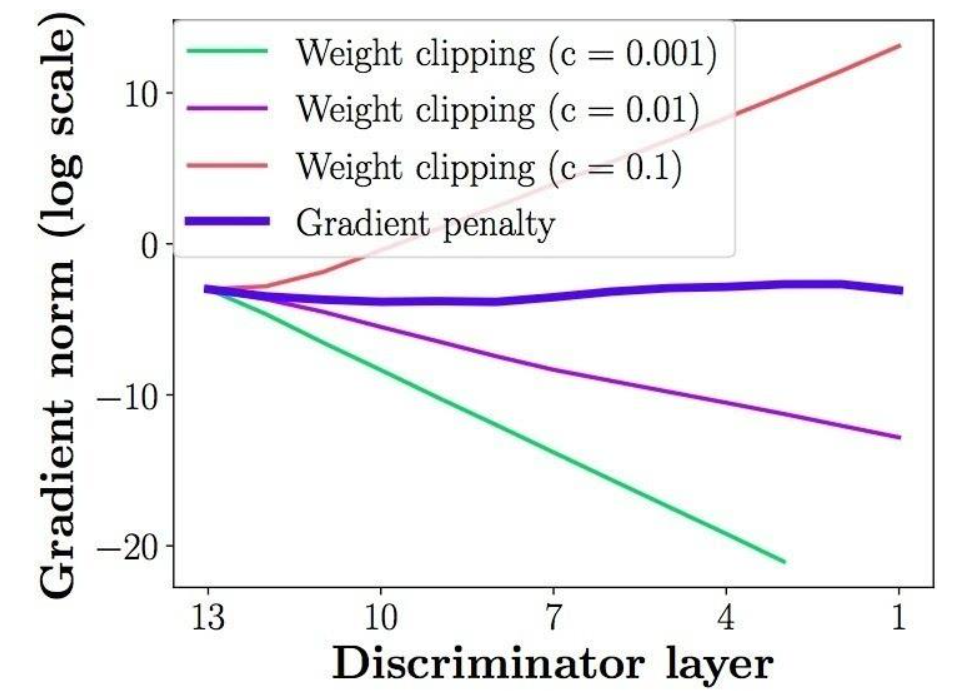
权重裁剪的缺陷
极大的限制了网络的表现能力,因为对权重进行的范围限制,使得网络很难模拟出想要得到的函数。
容易出现梯度爆炸和梯度消失的现象,而且本来生成式对抗网络的参数设置就很敏感,这样更难收敛。
WGAN-GP的特点
保持GAN的网络结构不变,将判别器网络最后的sigmoid删去。
使用随机采样作为惩罚项,不用WGAN中的权重裁剪。
重新采用Adam优化器,不存在WGAN种Adam稳定性不高的问题。
WGAN-GP图像分析
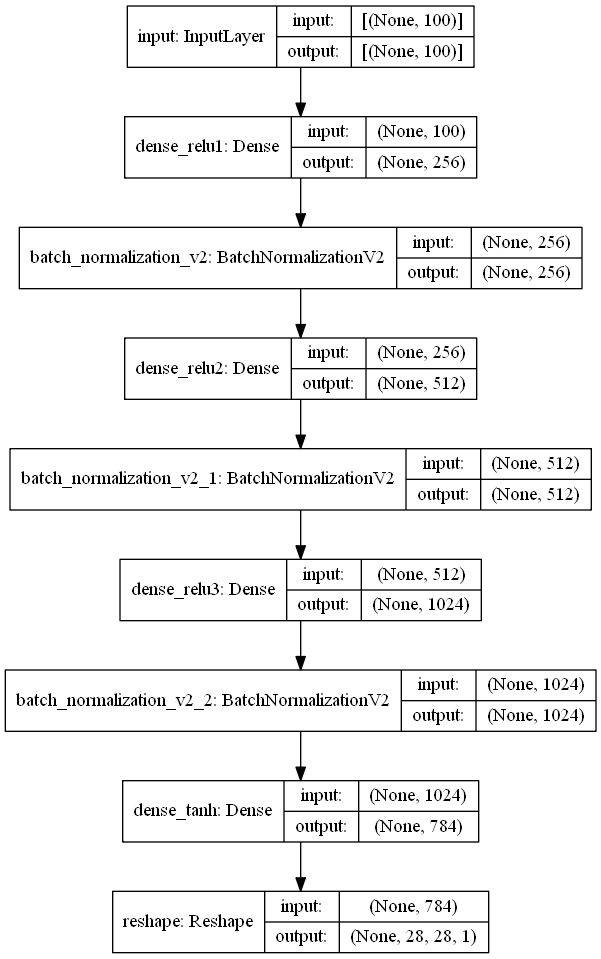
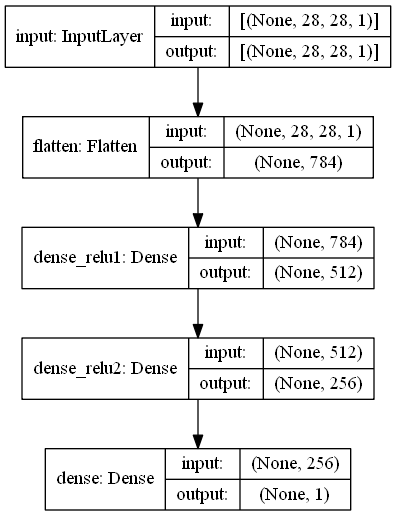
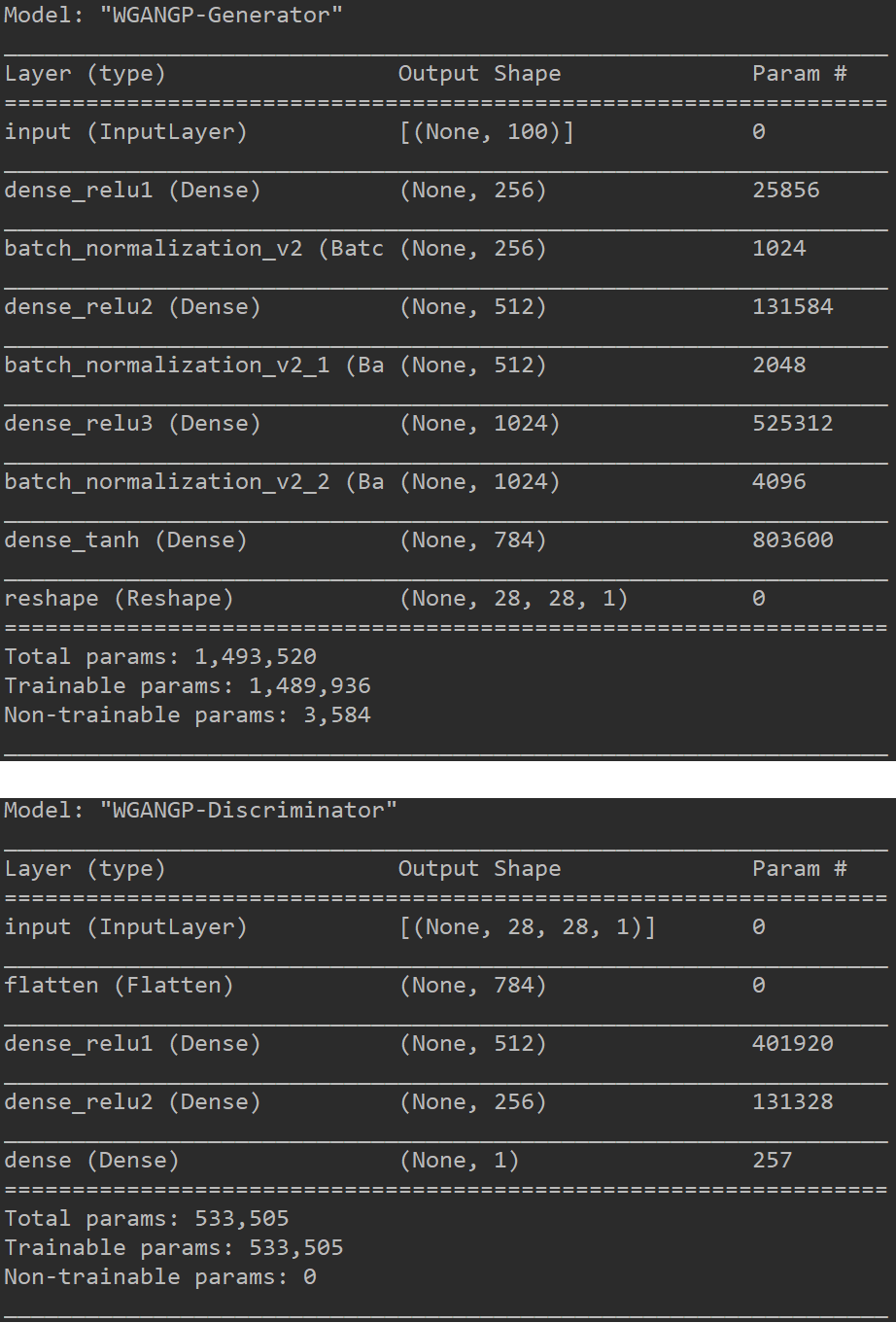
TensorFlow2.0实现
1 | import os |
模型运行结果

小技巧
- 图像输入可以先将其归一化到0-1之间或者-1-1之间,因为网络的参数一般都比较小,所以归一化后计算方便,收敛较快。
- 注意其中的一些维度变换和numpy,tensorflow常用操作,否则在阅读代码时可能会产生一些困难。
- 可以设置一些权重的保存方式,学习率的下降方式和早停方式。
- WGAN-GP对于网络结构,优化器参数,网络层的一些超参数都是非常敏感的,效果不好不容易发现原因,这可能需要较多的工程实践经验。
- 先创建判别器,然后进行compile,这样判别器就固定了,然后创建生成器时,不要训练判别器,需要将判别器的trainable改成False,此时不会影响之前固定的判别器,这个可以通过模型的_collection_collected_trainable_weights属性查看,如果该属性为空,则模型不训练,否则模型可以训练,compile之后,该属性固定,无论后面如何修改trainable,只要不重新compile,都不影响训练。
- 代码中使用了partial偏函数的概念,是functools中的内容,有关偏函数的使用,可以参考我的另一篇博客,Function(函数)
- 本博客中的WGAN-GP是在GAN的基础上进行修改,当然小伙伴们也可以尝试在DCGAN,CGAN等模型上进行尝试。
WGAN-GP小结
因为WGAN-GP基本没有修改网络结构,因此网络参数和GAN完全相同,WGAN-GP在提出时对网络的损失函数进行了大量的分析,使用随机采样的思想代替权重裁剪,增加了网络的表现能力和稳定性,这种GP思想对后面生成式对抗网络的发展有着巨大的推动作用,小伙伴们可以跳过WGAN的学习,但是WGAN-GP是需要我们了解的模型。