背景介绍
BigGAN:于2019年发表于ICLR,被誉为史上最强GAN图像生成器,BigGAN为什么那么强,因为引入了大量的黑科技,目前GitHub上面都是基于Pytorch的实现,而且代码特别繁琐,这里向小伙伴们介绍我的TensorFlow2.0简易版实现。
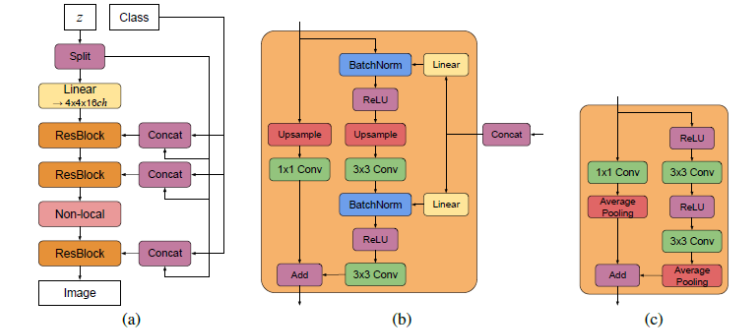
BigGAN的特点
**BigGAN可以认为SNGAN和SAGAN的结合,为了解决WGAN中的1-Lipshcitz问题,BigGAN在生成器和判别器中都借鉴了SNGAN中的Spectral Normalization(频谱归一化)的思想,而且借鉴了SAGAN的Self-Attention(注意力机制)**。
Truncation Trick(截断技巧),将噪声向量进行截断,可以提高样本的质量,但是降低了样本的多样性。
Orthogonal Regularization(正交正则化),可以降低权重系数之间的干扰。
Class-Conditional-BatchNorm(类条件批归一化),在归一化时引入分类信息,可以生成指定类型的图像。
Hierarchical latent spaces(分层潜在空间),输入噪声分布在网络的各个层,并不只作用于第一层。
使用了ResNet网络结构,其中有输入和输出尺寸相同的Resblock层,输入尺寸宽高缩小两倍的Resblock_down层和输入尺寸宽高增大两倍的Resblock_up层。
batch大,参数量大,训练时间长,在这里我只展示网络结构和一些细节,训练过程我就跳过了。
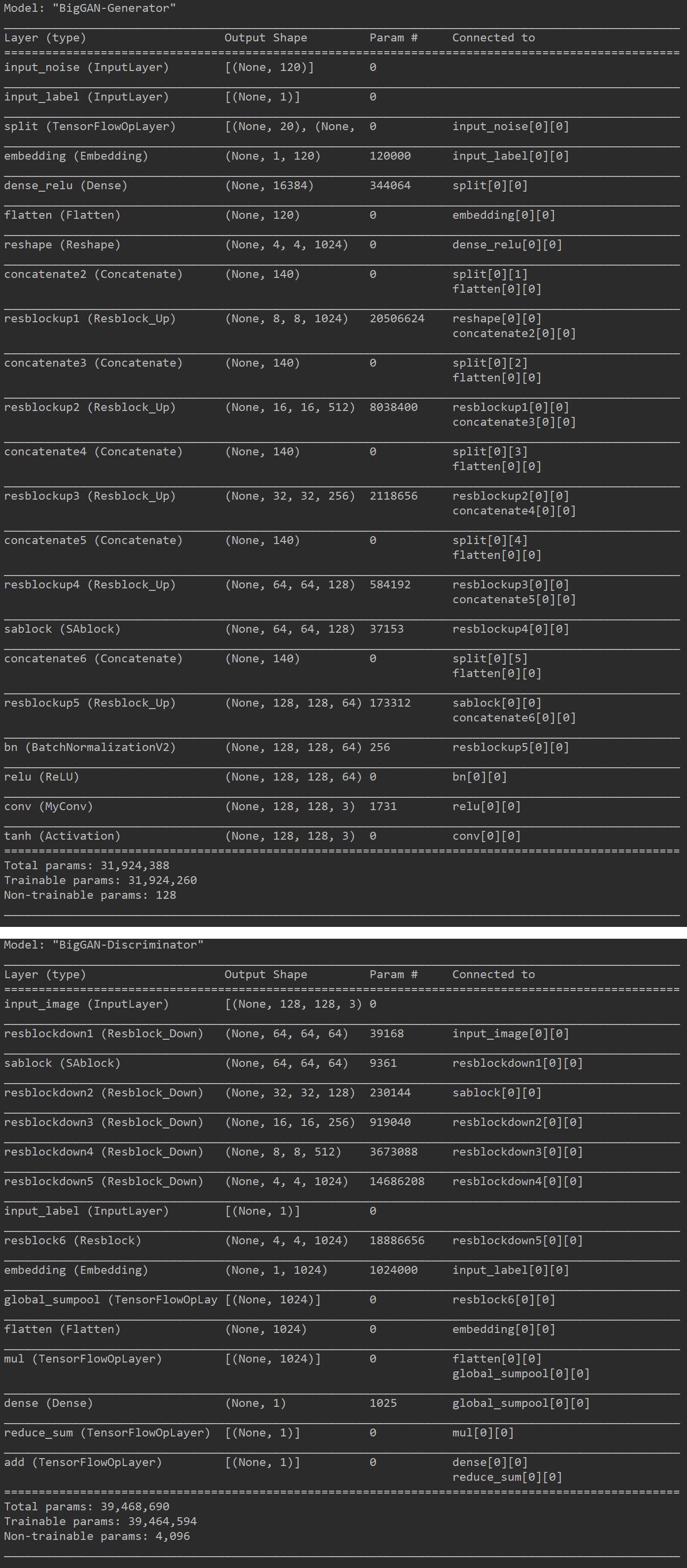
128x128网络结构
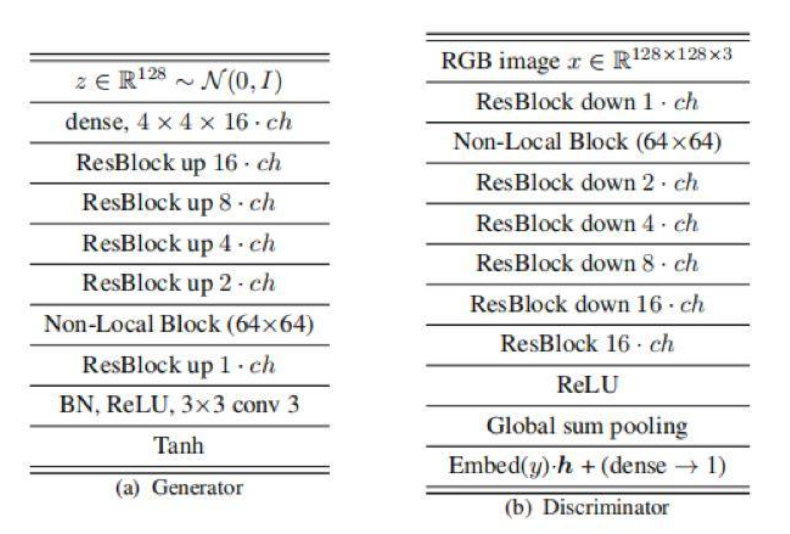
BigGAN图像分析
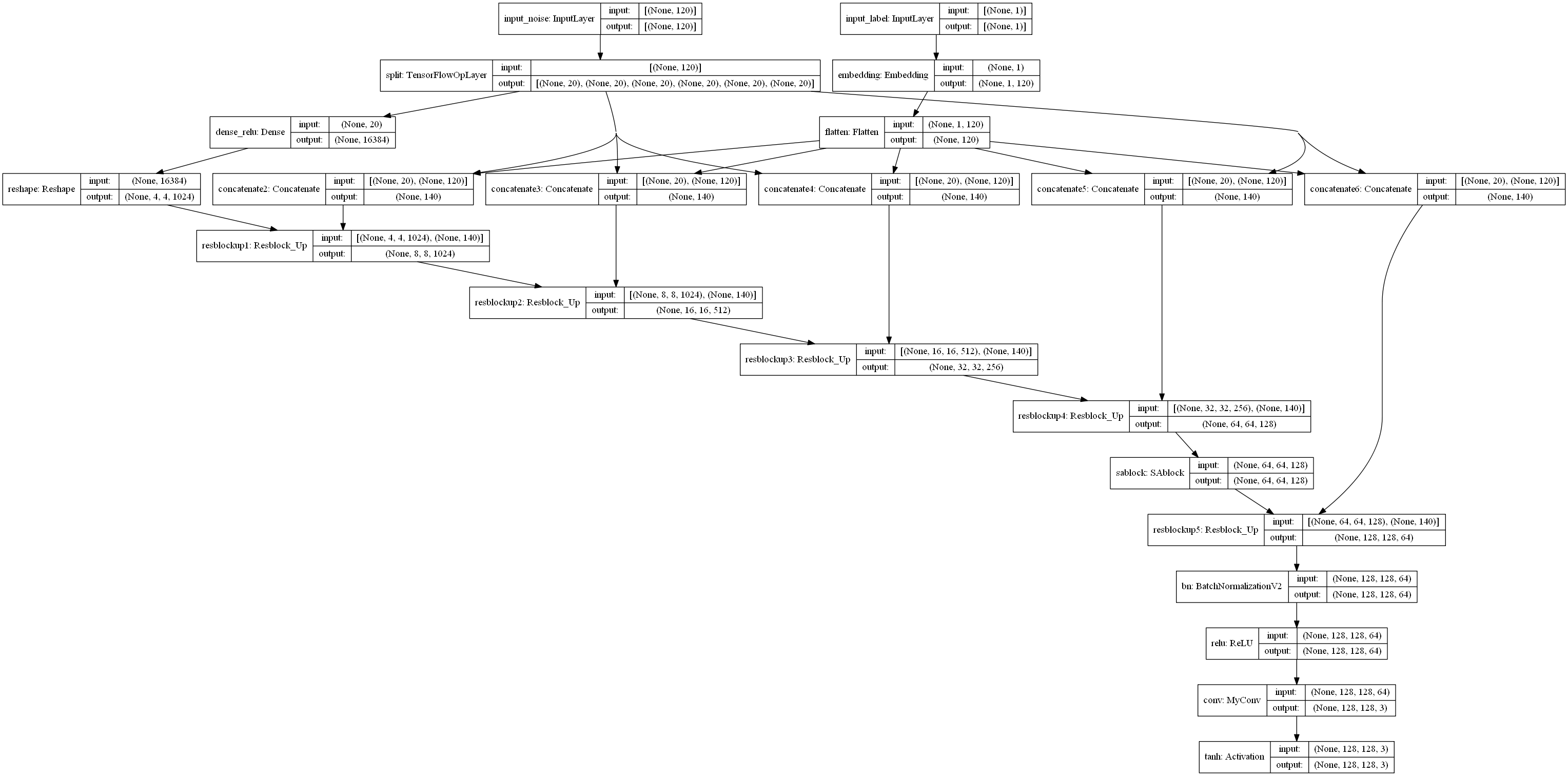
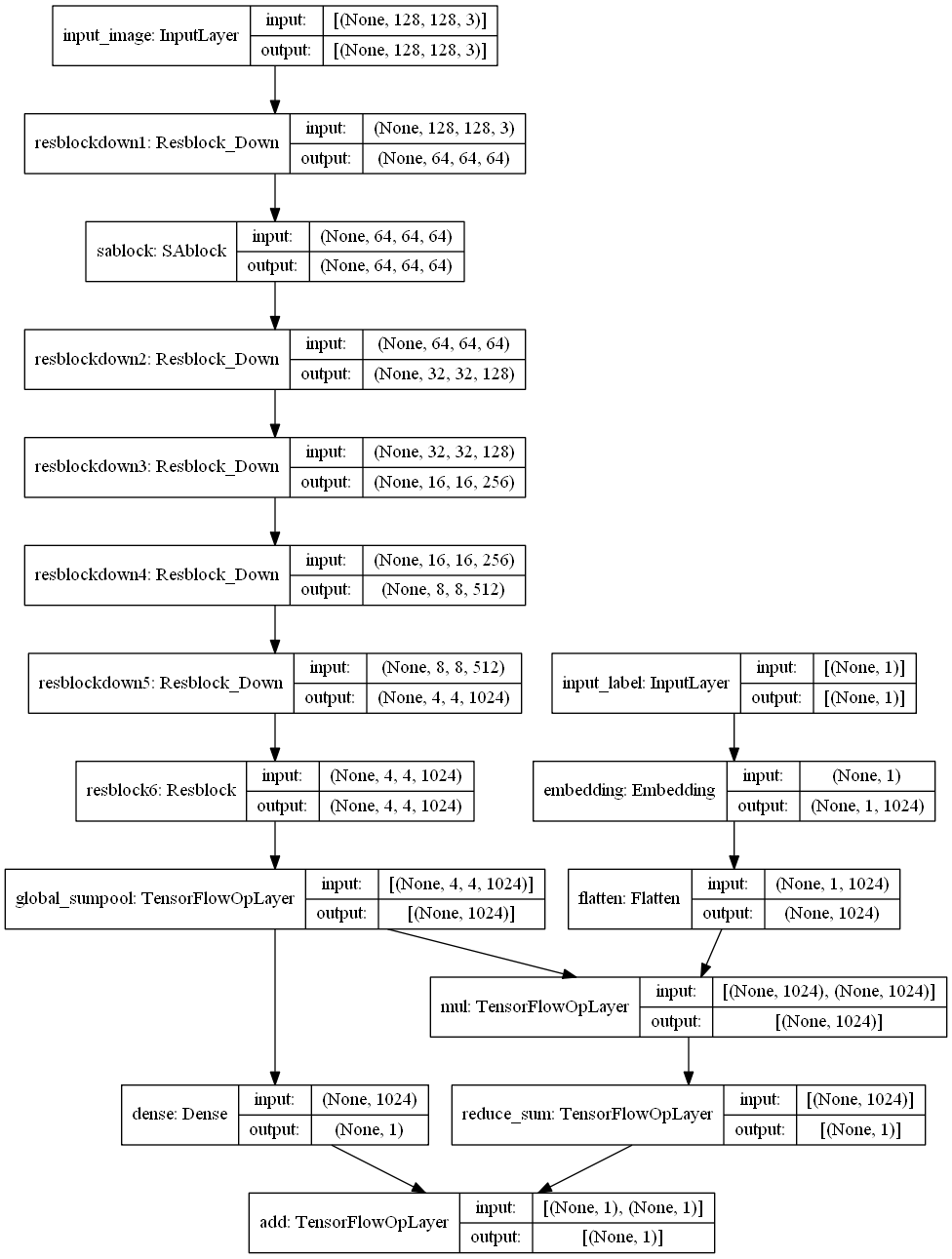
TensorFlow2.0实现
1 | from functools import reduce |
模型运行结果

小技巧
- 图像输入可以先将其归一化到0-1之间或者-1-1之间,因为网络的参数一般都比较小,所以归一化后计算方便,收敛较快。
- 注意其中的一些维度变换和numpy,tensorflow常用操作,否则在阅读代码时可能会产生一些困难。
- 可以设置一些权重的保存方式,学习率的下降方式和早停方式。
- BigGAN对于网络结构,优化器参数,网络层的一些超参数都是非常敏感的,效果不好不容易发现原因,这可能需要较多的工程实践经验。
- 先创建判别器,然后进行compile,这样判别器就固定了,然后创建生成器时,不要训练判别器,需要将判别器的trainable改成False,此时不会影响之前固定的判别器,这个可以通过模型的_collection_collected_trainable_weights属性查看,如果该属性为空,则模型不训练,否则模型可以训练,compile之后,该属性固定,无论后面如何修改trainable,只要不重新compile,都不影响训练。
- 代码中正交正则化使用了闭包的概念,有关闭包的使用,可以参考我的另一篇博客,Closure & Decorators(闭包和装饰器)
- 这个模型效果太好,生成的图片甚至比真实图片还要好,一些纹理,背景细节都可以完美呈现,但是想自己实现训练过程,非常困难,因此建议小伙伴了解就可以,不用亲自实践。
BigGAN小结
BigGAN分为很多版本,有128的图像版本,256的图像版本和512的图像版本,具体模型结构都很类似,但是参数量指数级增长。这是最小的BigGAN版本,参数量都可以达到80M,虽然VGG16的参数量有一亿多,但是网络结构简单,因此训练反而快,而BigGAN含有很多细节操作,会花费较长的时间,因此训练起来非常慢,BigGAN不是单打独斗,在特点中已经分析了,可以看成SNGAN和SAGAN的共同作品,因此关于其中的数学推导可以参考网络的其他资源,在这里也不过多赘述,作为史上最强的GAN图像生成器,小伙伴们一定要了解它。