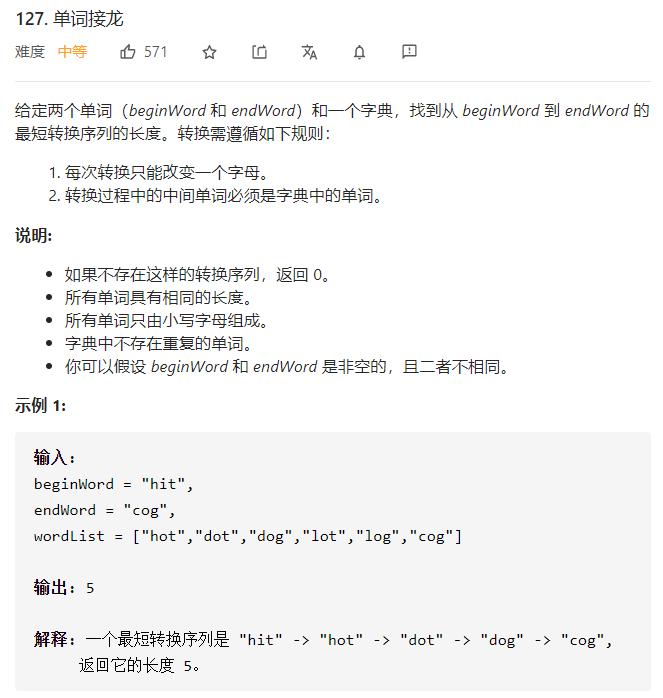
题目分析
这个题目一看就是使用广度优先算法,如何一看就知道,这个分析很重要。原因有两个,其一是搜索过程很简单,已知当前状态,从字典中搜索下一个匹配的状态。其二是要求最短的转换序列长度,这就说明了BFS是优于DFS的。
BFS
BFS大家也已经非常熟悉了,在这里我就介绍两个重要的点。
一个是当列表单词很多的时候,我们可以枚举单词的位置,枚举每个位置的字符,假如有字典中10000个单词,每个单词长度为10。如果我们逐一和所有单词比较是否相差一个字符,就需要10000次比较,如果只是枚举长度和可能出现的单词,只需要枚举10*26=260次。
二是如果某个单词a首先变换到了b,那么可以将b添加到passed集合中,说明最先到达了b,后面所有到达b的长度一定不小于本次,所有以后到达b的都不需要在进行查找。
算法的时间复杂度为$O(nm)$,空间复杂度为$O(nm)$,其中n为字典中单词的个数,m为每个单词的长度。
1 | class Solution(object): |
优化BFS
看了题解中powcai大佬的解答,才发现BFS还是可以进一步优化的。我们可以从首尾双向开始查找,当它们有交集的时候,说明找到了一条通路。就类似于两个人见面,上面的做法是一个人在原地等待,一个人去找。而现在介绍的算法是两个人都向中间走。
代码很好理解,我们来看一看大神的思路。
算法的时间复杂度为$O(nm)$,空间复杂度为$O(nm)$,其中n为字典中单词的个数,m为每个单词的长度。
1 | class Solution: |
刷题总结
小伙伴们认真刷题,现在刷题是软件岗位的必备技能,即使小伙伴们已经找到了工作,但也不能放弃刷题提升自己。