题目分析
这个题目有趣了,看起来非常简单的题目,小伙伴们能否实现它呢?
KMP算法
对于smalls中的每一个元素,都去使用KMP算法和big进行匹配,
KMP算法我在Leetcode28题有详细的描述,在这里就不写算法的实现了,直接调用substr。
算法的**时间复杂度为$O(mn)$,空间复杂度为$O(m)$**,其中m为big的长度,n为smalls的数量,空间复杂度的计算排除了最终答案占用的空间,只计算中间过程占用的空间。
1 | #include<iostream> |
双指针+哈希表
这个算法是我比较推荐的算法,其实KMP算法是最先想到的,由于担心TLE,因此就写的这个算法,没想到直接暴力KMP居然也可以直接通过,反而时间还挺快。
我们先建立一个哈希映射hashMap,其中键为smalls中的字符串,值为smalls中所在的索引。然后使用两层循环,双指针,i和j,如果big字符串从i到j所在的子串tmp在哈希映射中,那么就在res[hashMap[tmp]]中添加i这个索引即可。
算法的**时间复杂度为$O(m^2)$,空间复杂度为$O(m)$**,其中m为big的长度。
1 | #include<iostream> |
Trie树
这个方法是我在查看题解的时候看到的,我们将smalls中的字符串都加入到字典树中去,以例题进行画图说明。
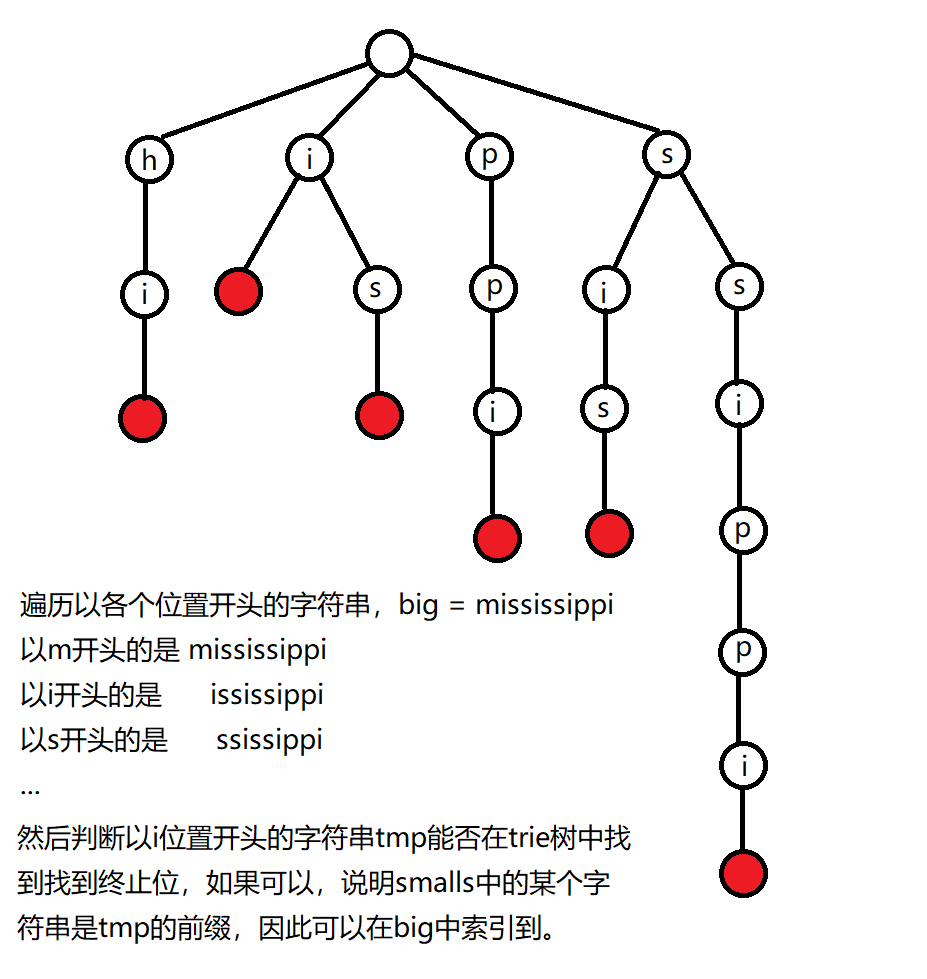
算法的插入smalls字符串的时间是mn,查找big后缀的时间是nk,因此算法的**时间复杂度为$O(max(mn, nk))$,空间复杂度为$O(nk)$**,其中m为big的长度,n为smalls的数量,k为small中字符串的平均长度。
1 | #include<iostream> |
刷题总结
Trie树在处理字符串时是一个非常方便的数据结构,尤其应用在求索引,查找等等问题上。可以实现一次建树,多次查询的效果,小伙伴们一定要会Trie树,我在博客Leetcode208题上对如何建立Trie树做了解释,有不明白的可以去参考学习。