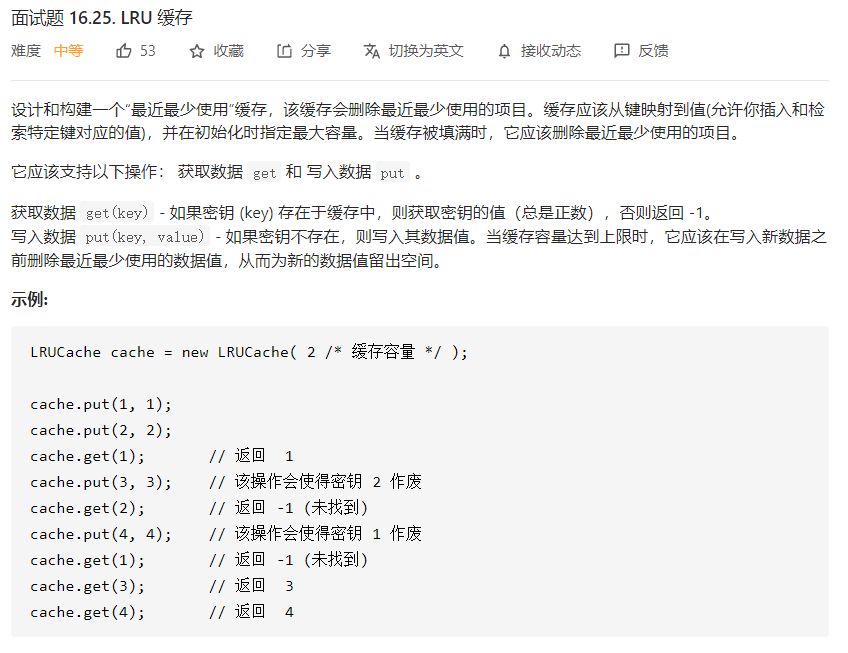
题目分析
LRU缓存是一种常见的内存页面置换算法,其思想是:如果内存已满,并且需要新的数据,那么就需要从内存中将已有的数据和新的数据进行置换,置换的原则是将哪一个最近没有使用,就将哪一个替换出去。小伙伴们了解原理之后,能否实现这个算法呢?
链表+哈希表
要根据键key查找值value,因此我们需要一个哈希映射,因为我们有容量,有时间顺序,因此我们需要一个顺序容器。顺序容器有很多,有vector,deque,list,我们选择哪一个最合适呢?
首先我们比较这三个的区别
**vector:动态数组,元素连续存放。随机访问,或者在尾部插入和删除都是O(1)的时间复杂度,而普通的插入和删除需要移动元素,时间复杂度是O(n)**。
list:双向链表,内存空间是不连续的。在任何地方插入和删除都是O(1)的时间复杂度,但是随机访问的时间复杂度是O(n)的,且必须一个一个进行对比,无法直接索引。
**deque:双端队列,介于vector和list之间,内存分块,每一个存储块之间是连续存放的。允许头部操作和尾部操作。随机访问,头部操作和尾部操作都是O(1)的时间复杂度,而普通的插入和删除时间复杂度是O(n)**。
这里需要大量的移动操作,如果最近使用了内存中的数据,则需要将该数据放入尾部,说明最近已经使用,因此需要频繁的用到删除和插入操作。插入操作都是在尾部插入,vector,deque和list都可以,但是删除操作会在数据中间使用,因此使用list效率更高。
但是问题是我们需要找到该元素,才能将其删除,找到该元素的操作是O(n)的,那应该如何优化呢?
我们可以在哈希表中不仅仅存放键对应的值,而是将键的迭代器指针也存放进哈希表中,这样在查询时,不仅一次能够查到值,而且也能将该迭代器指针查到,这样可以直接操作这个指针。
然后我们分别分析下面这两个步骤的具体实现过程。
put:put操作是向内存中放入元素,如果内存中已经有该元素,那么从哈希映射中查到该元素的指针,从list中移除该指针,并且在尾部重新添加键。修改哈希映射中的值和新的指针。如果内存中没有该元素,则需要分情况讨论,如果内存已满,需要将头部元素剔除,并且将对应的哈希表的键也剔除,因为头部元素是最久没有使用到的数据。然后再在尾部重新添加键,修改哈希映射中的值和新的指针。
get:get操作相对于put操作简单一些,如果哈希表中没有查到,则返回-1,如果哈希表中查到了,说明本次使用到了该数据,需要将这个数据从原来的位置删除,并且添加到尾部。这个过程类似于放入已存在的元素。从哈希映射中查到该元素的指针,从list中移除该指针,并且在尾部重新添加键,修改哈希映射中的指针,并且返回值是哈希映射中的值。
算法的**时间复杂度为$O(1)$,空间复杂度为$O(n)$**。
1 | #include<iostream> |
自定义双向链表
这个方法是小伙伴们务必掌握的,这非常锻炼小伙伴们对于数据结构的知识。
我们手动创建一个双向链表,和上面一样,实现在尾部插入和任意节点删除即可,思路和上面完全相同,直接看代码吧。
算法的**时间复杂度为$O(1)$,空间复杂度为$O(n)$**。
1 | #include<iostream> |
刷题总结
构建类的题型一般都是考察在已有的数据结构上加以变化,形成一种针对于特定问题的数据结构。这要求小伙伴们对数据结构的熟练程度非常高,虽然在笔试中很少遇到这样的题目,但是在面试中可能会让小伙伴们实现某种特定的结果,如字节跳过就曾考察过构造类的问题。可能一道题就会让你与某个岗位失之交臂,或者待遇相差很大,因此小伙伴们要重视起来。