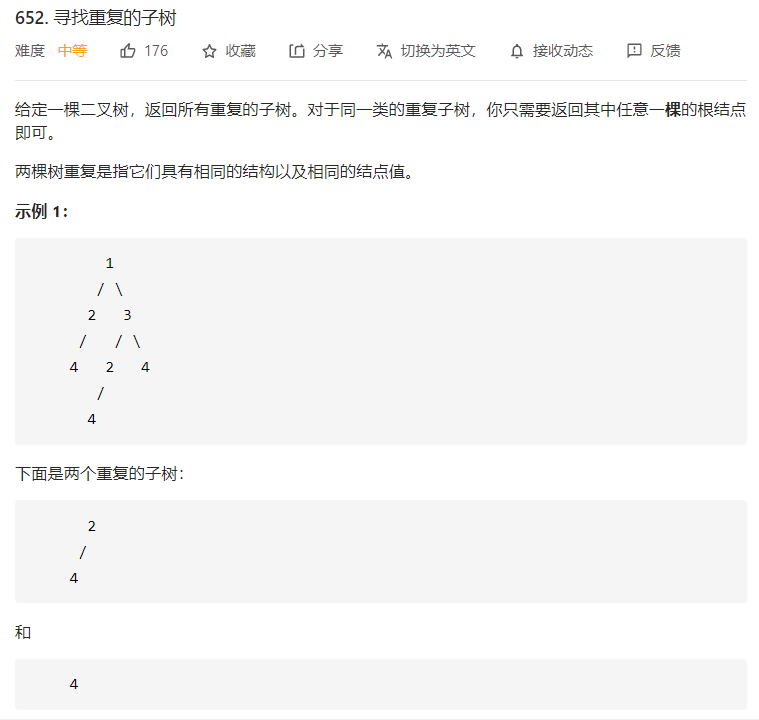
题目分析
Leetcode的每日一题是这个题目,翻了一下当时的博客,发现这是很早以前做过的题目了。第一次做是在两年前了。这个题目还是比较复杂的,这一次还是没有想到最优的解法。能想到的方法是记录所有子树的结构,然后将结构序列化存入字典中,并记录每个结构出现的次数,当次数大于1说明有重复的结构。我们就在python的基础上补充java的题解吧。
哈希表
通过递归获取子树结构,并将其结构保存为一个三元组,这样可以存放入字典中作为键。
算法需要遍历所有的节点,对于每一个节点要进行键的对比,因此**时间复杂度为$O(n^2)$,空间复杂度为$O(n^2)$**。
1 | from collections import defaultdict |
1 | class TreeNode { |
优化哈希表
上面的算法如果树结构过大,运行效率非常慢,因为三元组记录着树的层次关系,因此在深层次的树形结构中,比较两个三元组是否相等需要浪费太多的时间。我们可以对三元组进行编号,字典中第一次出现的三元组记为0号,第二次出现的三元组记为1号,一次向下编号。那么我们就不需要比较三元组是否相等,只需要比较编号是否相等即可。
python3中defaultdict类,有default_factory成员变量,其控制着返回值的默认类型,如果为int,则新加入的元素值为0,如果为dic.__len__,则新加入的元素值为dic中元素的个数,那么就相当于对元素进行编号。因为第一个元素加入前,dic中的元素个数为0,记为0号,第二个元素加入前,dic中的元素个数为1,记为1号。
本题中python3代码还是比较抽象的,看不明白python3代码的同学,可以看一下java语言的实现。某个节点为null,则返回0,不为null则从1开始向上编号。因此任意一个节点都可以表示为[left, val, right]三个值,如果三个值都相等,说明是重复的子树。
算法的**时间复杂度为$O(n)$,空间复杂度为$O(n)$**。
1 | from collections import defaultdict |
1 | class TreeNode { |
刷题总结
本题的本质是如何将树进行序列化,优化版本的算法思想希望小伙伴能够掌握。