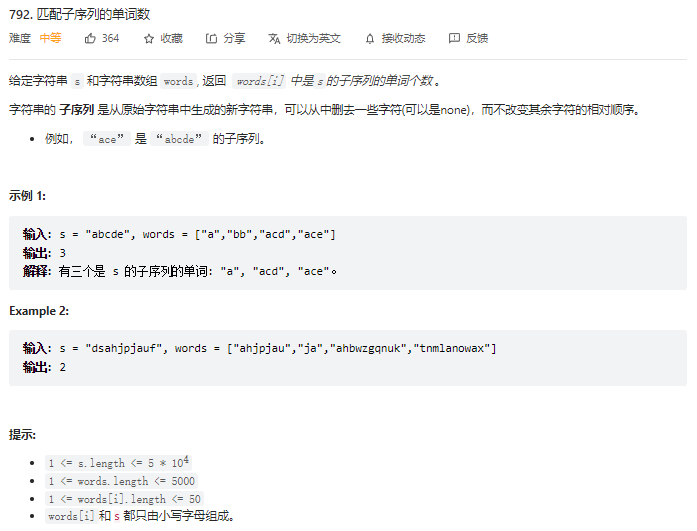
题目分析
这个题目很经典了,但是难度直线上升。常见的题目是Leetcode392判断子序列,那个题目是一个经典的双指针,也是双指针题型的入门题,这里不过多赘述。本题第一眼看过去就是遍历每一个元素,然而发现数据量会达到1e8,是无法通过本题的,因此需要用到一下三种做法。
一般来说求解某个题目的算法是相似的,比如DFS、BFS、并查集是一类,双指针、滑动窗口、单调栈是一类,动态规划、记忆化是一类,排序,贪心,模拟,二分是一类。本题也是说来奇怪,三个毫不相干的算法,居然都能够求解本题,那么这种题目就是大家必须要学会的,可以将我们的算法知识串联在一起。
二分查找
数字的二分查找比较容易想到,但是字符串如何二分呢?
我们先考虑一个字符串的匹配,就是在word中每个字符都要在s中按顺序找到,这里有一个常识,就是如果有多个字符匹配一定要选择最先匹配的。显然成立,不需要证明。
假如word[0]在s中的索引为i,那么word[1]就需要在s中匹配从i + 1开始的字符。
因此可以将s中的字符按照字母表分成26类,每一类是该字符出现的全部索引。这样找word[1]时,直接到对应的类中,使用二分查找全部索引中大于i的最小值即可。
算法的时间复杂度为O(mk \times log(n)),空间复杂度为O(n)。其中n为s的长度,m为字符串的数量,即words的长度,k为每一个单词的长度。
1 | class Solution { |
双指针
本题的双指针并不是双指针,而是多指针,一个字符串匹配可以认为是双指针,两个字符串同时匹配是三指针,m个字符串匹配可以认为是m + 1指针。
有的同学会有疑问,这种时间复杂度不还是$O(mn)$吗?如何优化时间复杂度呢?
这个指针数量是可以动态变化的,指针数量等于与s中当前字符相同的所有字符串数量。
举个例子,指向s的指针当前字符为’c’,那么当前字符为’c’的字符串有t个,那么就是t + 1指针(包括s指针)。
所以指针总数量为mk,s最多移动n次,算法的时间复杂度为O(mk + n),空间复杂度为O(m)。其中n为s的长度,m为字符串的数量,即words的长度,k为每一个单词的长度。
1 | class Solution { |
前缀树
多个字符串匹配问题,往往都可以考虑前缀树。
但是本题要逆向构树,本题一开始我使用的前向构树,以例题中abcde为例,a后可以放bcde子树,cde子树,de子树,e子树。b后可以放cde子树,de子树,e子树。等等,虽然可以使用记忆化避免反复建树,但是在a后放子树的过程是O(n)的,因此建一个符合条件的前缀树是$O(n^2)$的,会导致TLE。
逆向构树是将words中的单词构造前缀树,然后从根Trie节点开始遍历所有的children节点,如果有某个节点,就找该节点字符在s中第一次出现的索引idx。然后继续遍历children节点,当遍历到第k个children节点,表示存在值为’a’ + k的字符,因此要寻找从idx + 1开始,在s中第一次出现’a’ + k的字符,直到找完整个前缀树。
因为每次搜索树节点都需要查找s中出现的某个字符,因此算法的时间复杂度为O(mkn),空间复杂度为O(mk)。其中m为字符串的数量,即words的长度,k为每一个单词的长度。因为题目的数据量不是特别大,而且在指定范围查找字符也不完全是O(n)的时间,因此可以通过本题。
1 | class Solution { |
上面的算法是DFS版本,下面也给出一个BFS的版本。
1 | class Solution { |
刷题总结
本题的难度不小,有一些反直觉的思考过程在里面。不是将s与words中的每一个字符进行对比。二分法是对于每一个words单词的每一个字符,都去找s中该字符出现的最靠前的位置。双指针是同时比较多个单词相同字符与s的关系。本题思路清奇,我们需要多练习这类题目。