
背景介绍
Regularization(正则化):简单的说就是减小测试误差的行为,我们在构建深度学习模型时,最终目的是为了让模型更好的面对测试数据,而不是训练数据。但是网络在学习的过程中很容易就出现了Overfitting(过拟合),这就导致模型的泛化能力下降,所以需要引入一些正则化的方法,降低模型的复杂度。
Regularization(正则化):简单的说就是减小测试误差的行为,我们在构建深度学习模型时,最终目的是为了让模型更好的面对测试数据,而不是训练数据。但是网络在学习的过程中很容易就出现了Overfitting(过拟合),这就导致模型的泛化能力下降,所以需要引入一些正则化的方法,降低模型的复杂度。
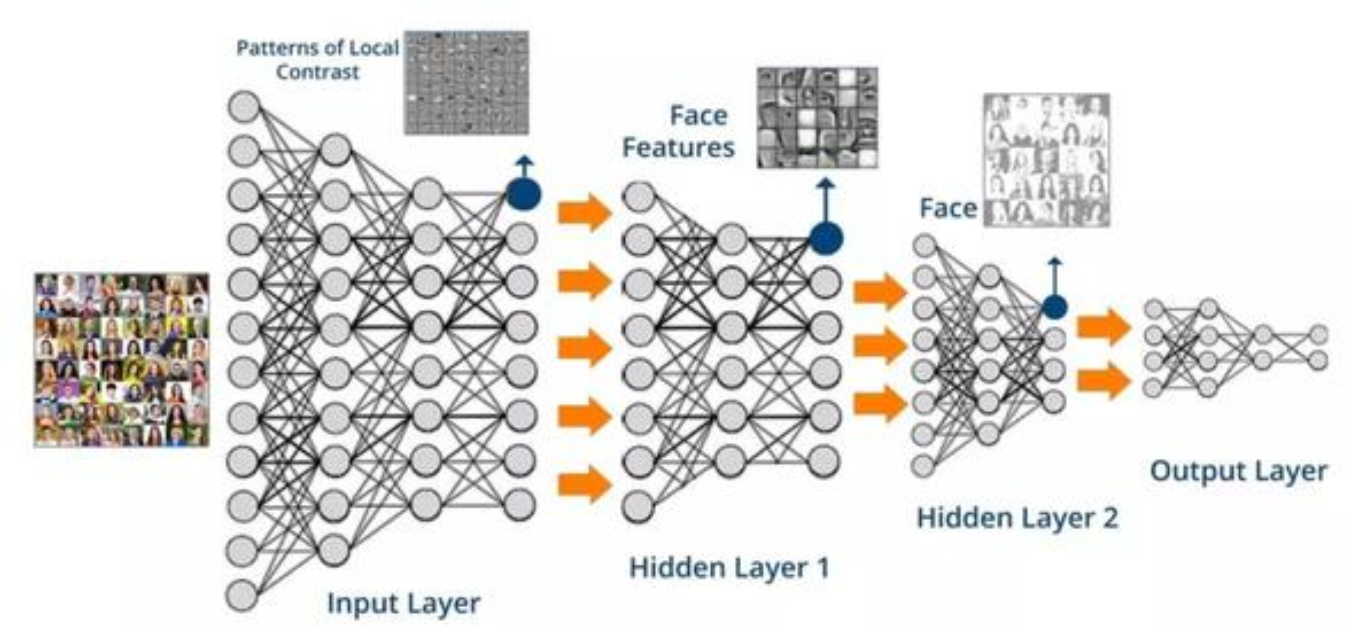
Train, Evaluate, Predict(训练,验证,预测):是深度学习中的基础内容,想要完成一个深度学习工程问题,训练,验证,预测是必不可少的环节,今天以LeNet-5模型为例,给入门的小伙伴们提供TensorFlow中三种常用的训练,验证,预测方法。
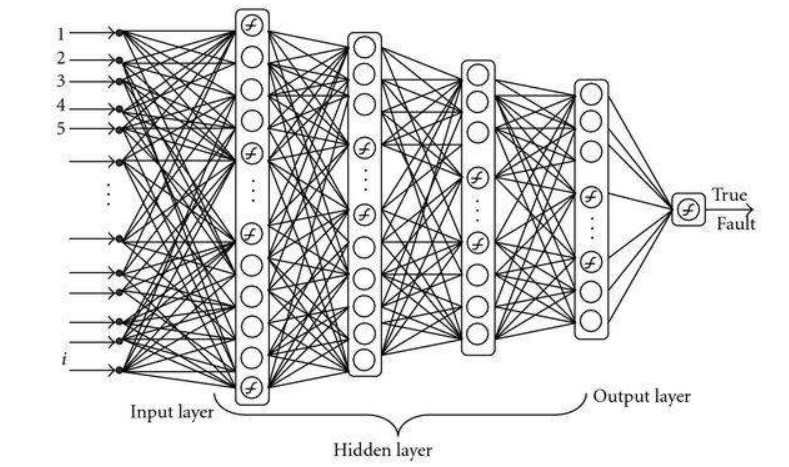
Define Layer(定义网络层):是深度学习中的基础内容,想使用深度学习方法解决实际问题,首先就需要建立一个网络层,今天以LeNet-5模型为例,给入门的小伙伴们提供TensorFlow2.0两种定义网络层的方法。
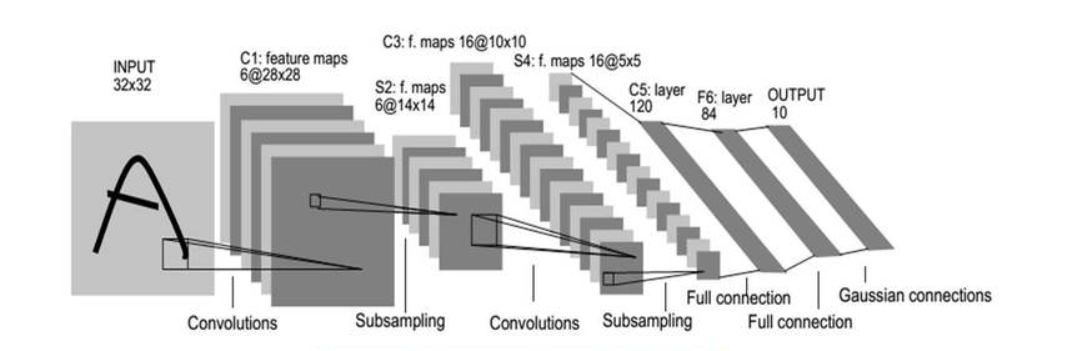
Define Model(定义模型):是深度学习中的基础内容,想使用深度学习方法解决实际问题,首先就需要建立一个模型,今天以LeNet-5模型为例,给入门的小伙伴们提供TensorFlow2.0三种自定义模型的方法。
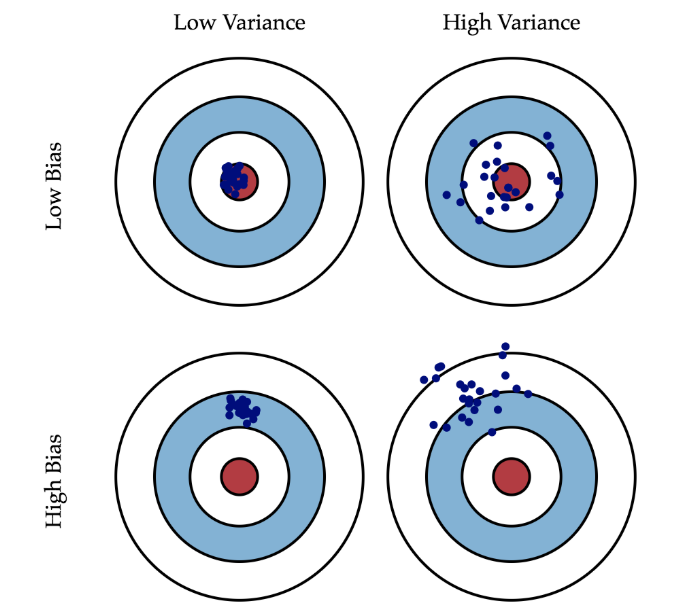
Error,Bias,Variance,Noise(误差,偏差,方差,噪声):是机器学习中的一组重要概念,小伙伴们可能也听说过这些,但是可能不清楚它们之间到底有什么练习,今天给大家捋一捋。
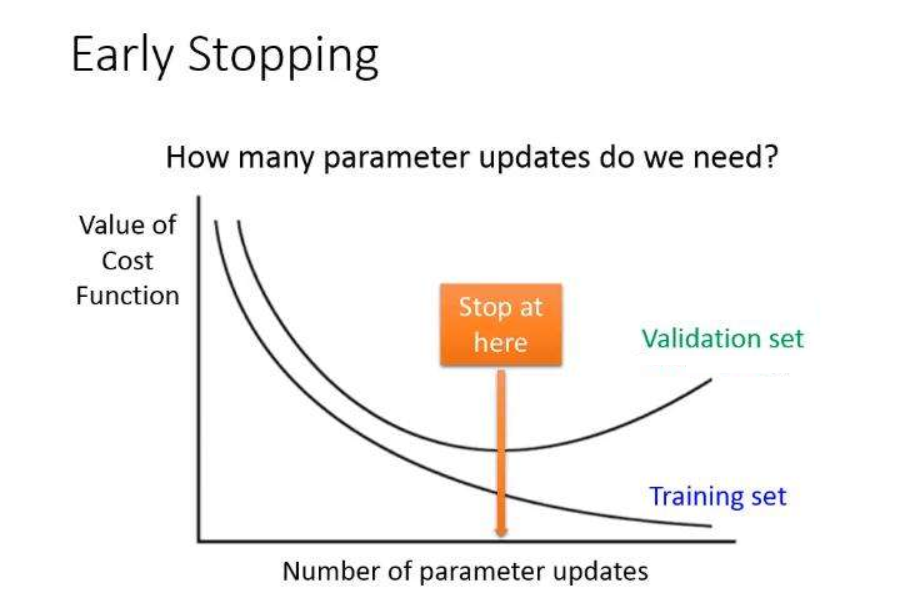
Callbacks(回调函数):指在网络学习期间,对网络的性能,参数等进行修改,保存,显示,早停等一系列操作。不是深度学习必须使用的,但是掌握回调函数可以更好的让网络为我们服务,下面来具体了解一下有哪些常用的回调函数。
Transfer learning(迁移学习):是一种常见的机器学习方法,概括的说就是将一个预训练的模型重新用在另一个任务上。其在深度学习问题上是非常受欢迎的,因为深度学习很大的一个问题就是数据集不够,神经网络的参数量少说几百万,多则上亿,因此对于数据量的要求也是十分巨大的,但是实际的问题往往很难找到足够数量的数据集,除了数据增强方法外,还可以利用迁移学习的思想。以分类问题为例,前面的卷积层和池化层的目的是特征提取,后面全连接层的目的是进行分类。因此如果我们有很好的特征提取参数,那么我们就不需要浪费太多数据集在特征提取部分,我们重点训练网络的后半部分即可。
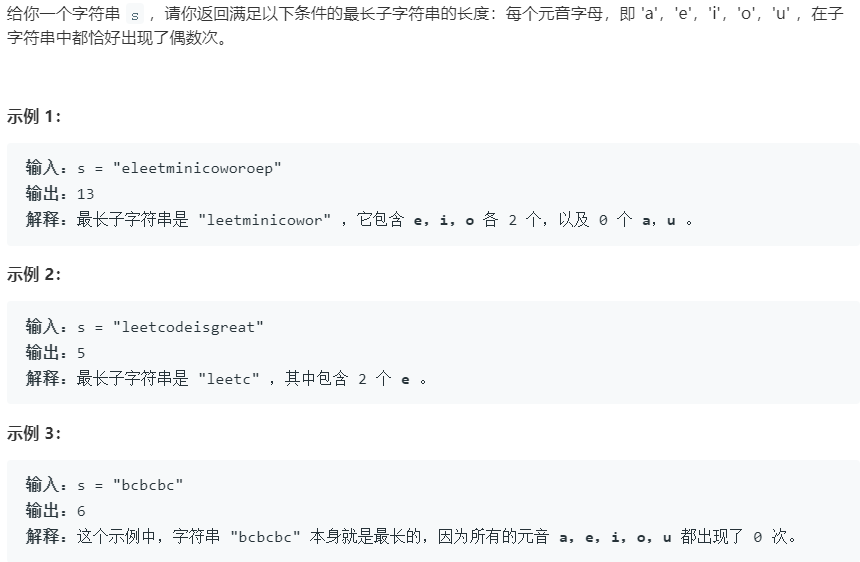
这个题目第一眼想到的方法是暴力求解,从第i个字符开始到第j个字符,使用两层循环,依次遍历,计算是否满足偶数个元音字母,算法复杂度也很好分析$O(n^2)$,但是求解的过程中浪费了大量的运算资源,如从第一个字符到最后一个字符,对每一个字符都判断了是否为元音字符,从第二个字符到最后一个字符,对每一个字符又判断了依次,因此大大增加了时间复杂度,如果直接使用暴力法,题目是很难通过的。
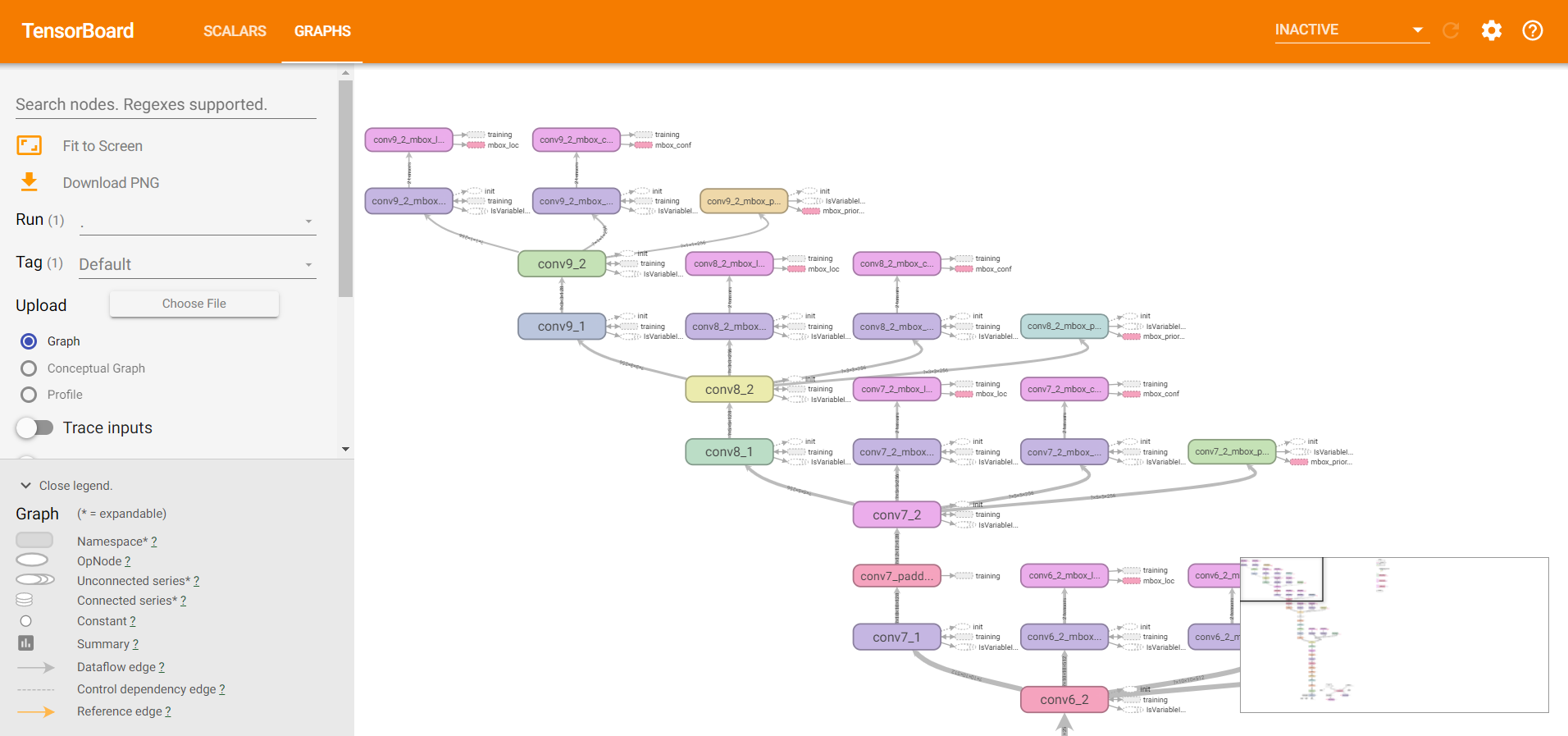
TensorBoard:是一个可视化工具,它可以用来展示网络流图,损失函数,评价函数等等随epoch的变化过程,其工作原理是,程序给磁盘的某个目录写数据,然后监听器就可以监听到这个目录的变化,打开Web浏览器就可以从监听器中获得数据,完成实时的数据更新。今天给小伙伴们介绍TensorBoard的两种使用方法,希望小伙伴们可以认真学习,动手尝试。
