
背景介绍
Data Augmentation(数据增强):在深度学习工程实践中,必不可少的是数据集,但是如果自己采集数据集,非常的耗时,而且数量往往不够。这时需要一定的数据增强操作,来扩充自己的数据集使网络更加鲁棒。今天给小伙伴们盘点常用的数据增强操作。
Data Augmentation(数据增强):在深度学习工程实践中,必不可少的是数据集,但是如果自己采集数据集,非常的耗时,而且数量往往不够。这时需要一定的数据增强操作,来扩充自己的数据集使网络更加鲁棒。今天给小伙伴们盘点常用的数据增强操作。
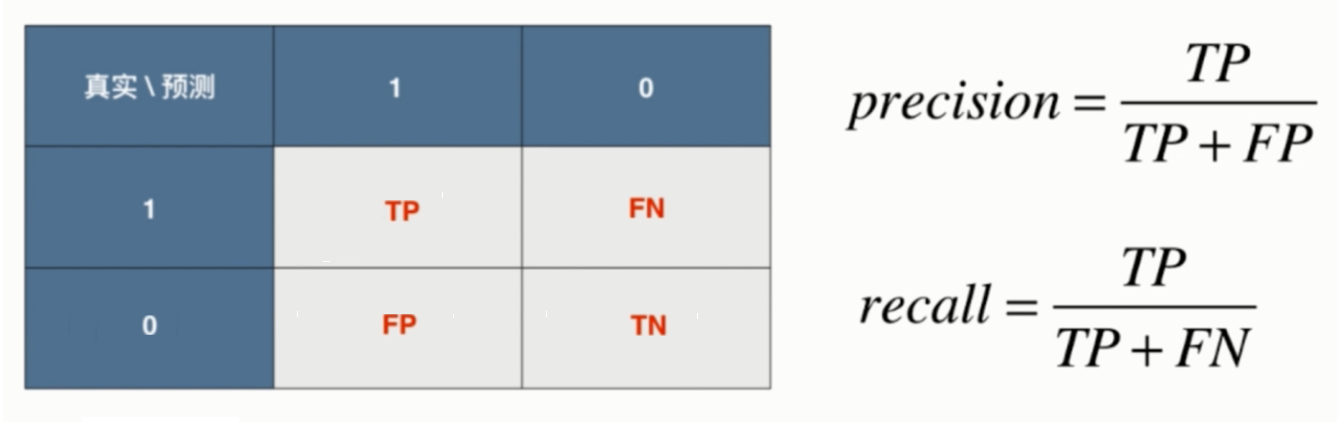
Metrics(评价指标):评价指标是检验神经网络模型好坏的评定依据,也是我们要达到的最终目标,指标越好则我们的任务完成的越好。有时我们需要根据评价指标修改我们的网络模型,参数等等,就类似于考试成绩一样,我们根据成绩检验自己薄弱的地方,然后去调整和修改,神经网络也是一样,只有建立好合适的评价指标,才能真正区分网络的优劣。今天给小伙伴们介绍深度学习中常用的评价指标。
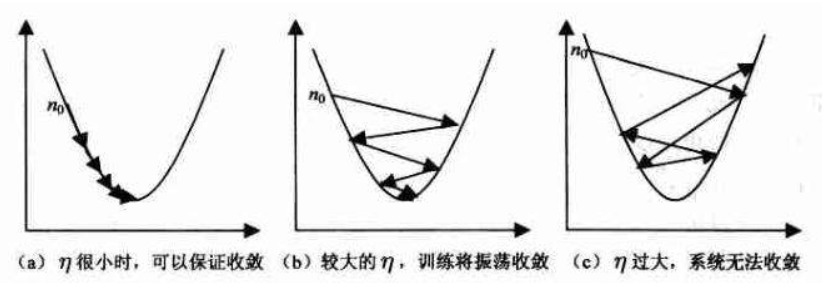
Learning Rate(学习率):深度学习中有一个重要的参数为学习率,小伙伴们应该都知道,这是设置优化器时的一个必要参数,学习率指导我们在梯度下降的过程中,如何去使用损失函数的梯度调整网络的权重。因此对网络的影响是非常重要的。今天给小伙伴们盘点一下常用的学习率黑科技。
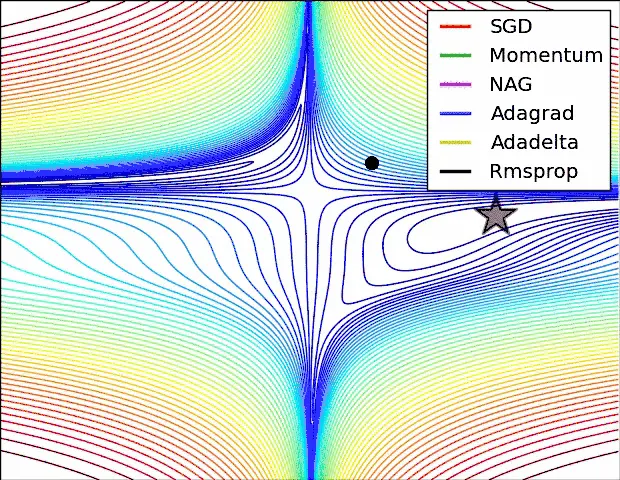
Optimizer(优化器):在深度神经网络中,如果说到达Loss最小是我们的终点站,那么出行方式就是优化器,它给我们提供一种方法接近Loss最小的地方。打一个简单的比方,如果我要从安徽前往北京,北京就是我们的目标,相当于神经网络中的Loss函数,而我们选择的交通方式则是优化器,我可以选择长途汽车出行,也可以选择火车出行,也可以选择飞机出行。选择哪一种交通方式最为合适呢?这也需要根据实际问题确定,优化器也是这样,没有最好的优化器,只有最适合的优化器,这里我不写太多的公式,主要是聊一聊各个优化器的用法,特点和参数表达的意义。
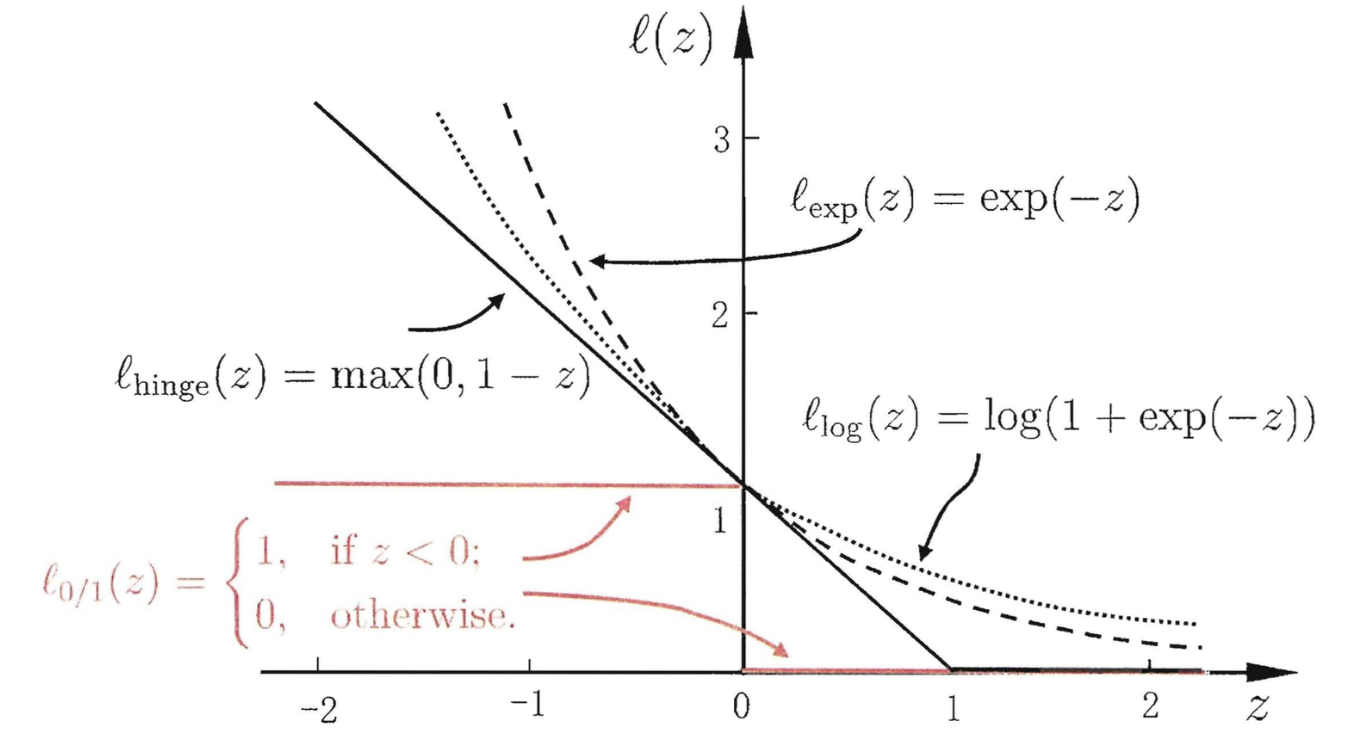
Loss(损失函数):在深度学习任务中,一个最重要的概念就是损失函数,这里不区分损失函数,代价函数和目标函数,这里指的就是神经网络中最终需要优化的函数。损失函数决定者参数更新的方向,神经网络的输出y_pred要和真实值y_true进行比较,使两者的距离越小越好,这个距离的度量就是损失函数。打一个简单的比方,损失函数对于神经网络来说就有如灯塔之于船只,可以指明前进的方向。神经网络的参数更新是根据损失函数来确定的,如果损失函数设置错误,则会产生巨大偏差,甚至南辕北辙的效果,在这篇博客中,我向大家介绍一些常用的损失函数。
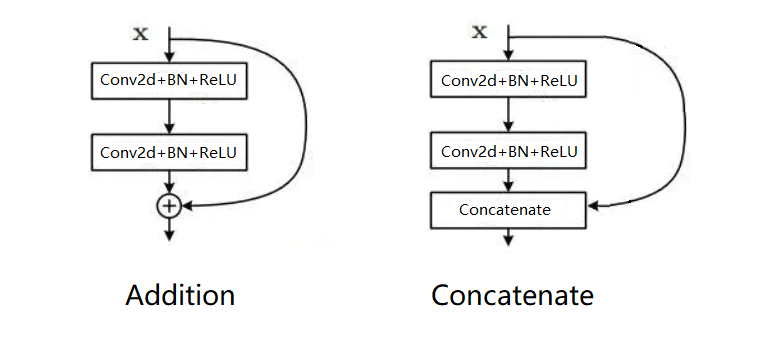
(Feature fusion)特征融合:VGG网络提出以后,给人们一种印象,深度学习越复杂,参数越多,会有越强的表达能力。但是在深度神经网络的研究过程中,发现到达一定深度后,一味地增加网络的深度并不能带来效果的提升,反而会导致网络收敛变慢。这时需要引入一些其他的方法既能提高网络的表达能力,也不会使网络收敛速度大大降低。两种特征融合方法**(Addition和Concatenate)**随着时代的发展产生了。相信小伙伴们也已经有所了解,在这里我系统的整理一下它们之间的区别。
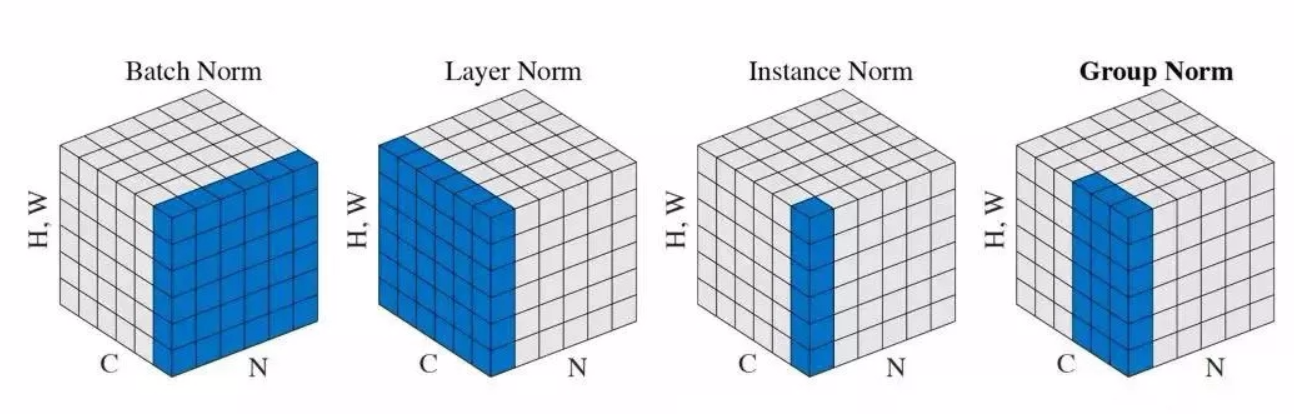
Normalization(标准化):深度神经网络模型训练困难,其中一个重要的现象就是ICS(Internal Covariate Shift,内部协变量偏移),其中解决的方法就是Normalization,现在标准化成为深度学习必备神器,今天带小伙伴们看一看,瞧一瞧。
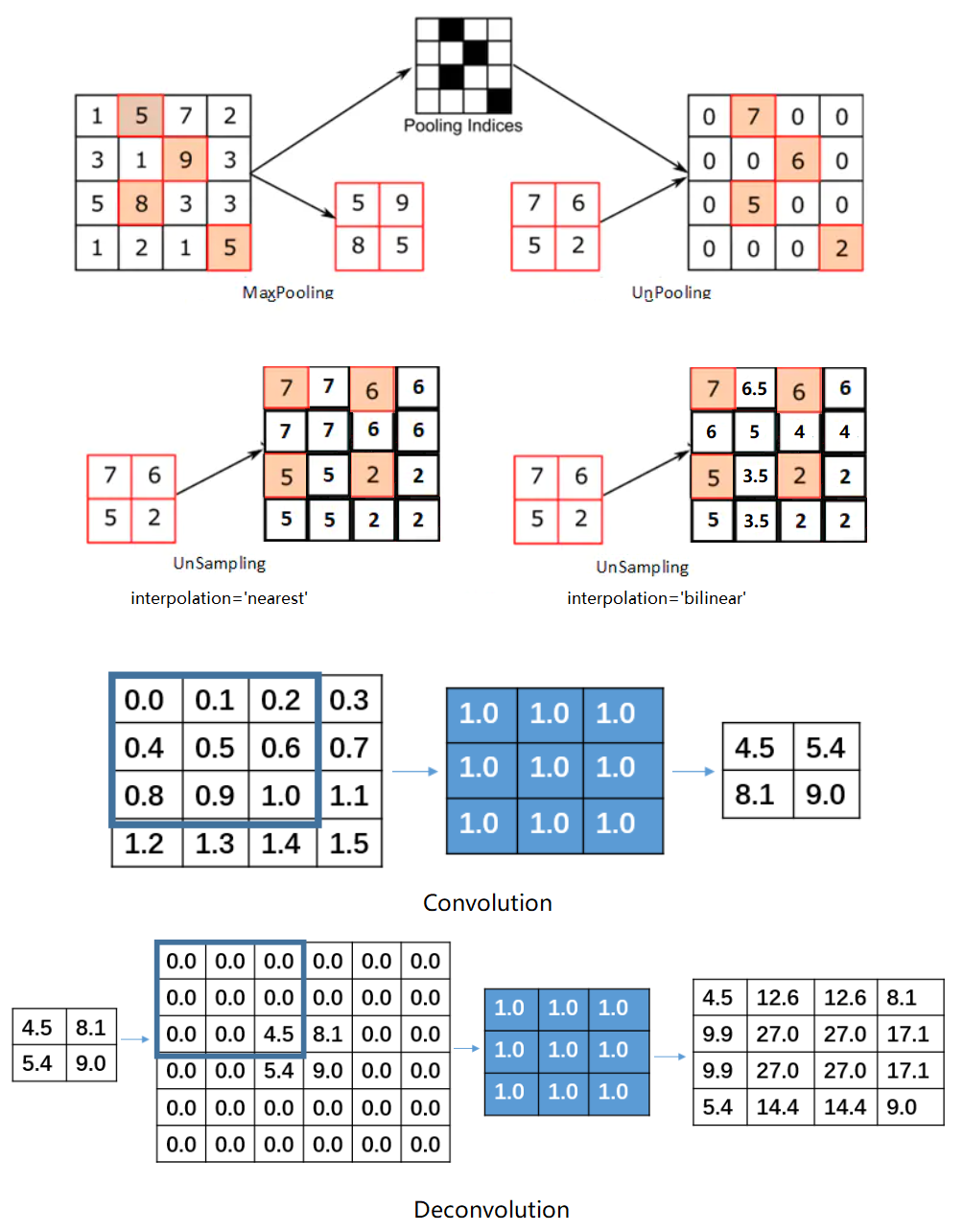
Upsampling(上采样):简单的说就是放大图像,获得更大的分辨率,上采样对于卷积神经网络任务来说并不是必须的,但是在某些场合中却必须要使用,尤其是在语义分割任务中,如何选择上采样的方式可能决定着语义分割效果。可能小伙伴们对上采样不是很熟悉,但是对于下采样一定都不陌生,典型的下采样步骤就是池化。因此上采样也可被看作是池化的逆过程。
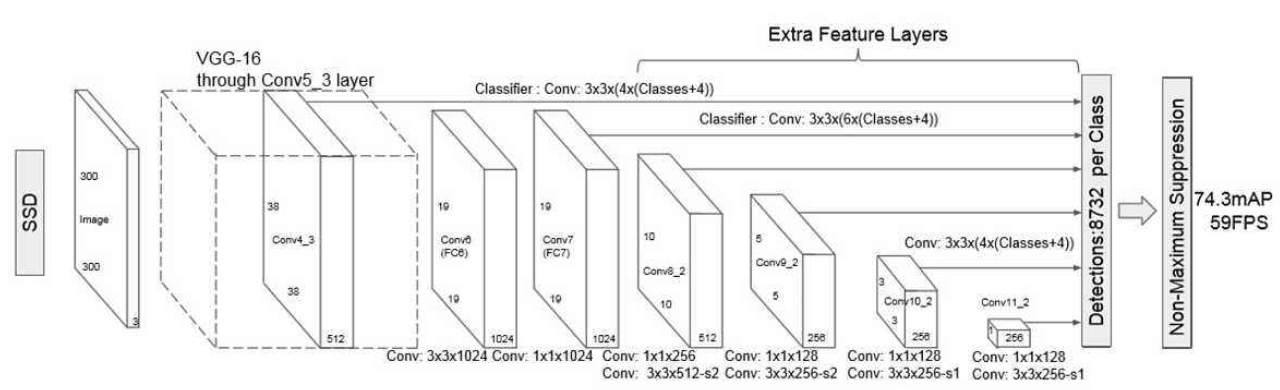
SSD(Single Shot MultiBox Detector):于2016年发表在ECCV上。Single Shot MultiBox Detector的字面意思为:单次多框检测器,顾名思义,属于目标检测算法中一步法的思想,而且利用到多个先验框的一种算法,是一步法的典型代表。
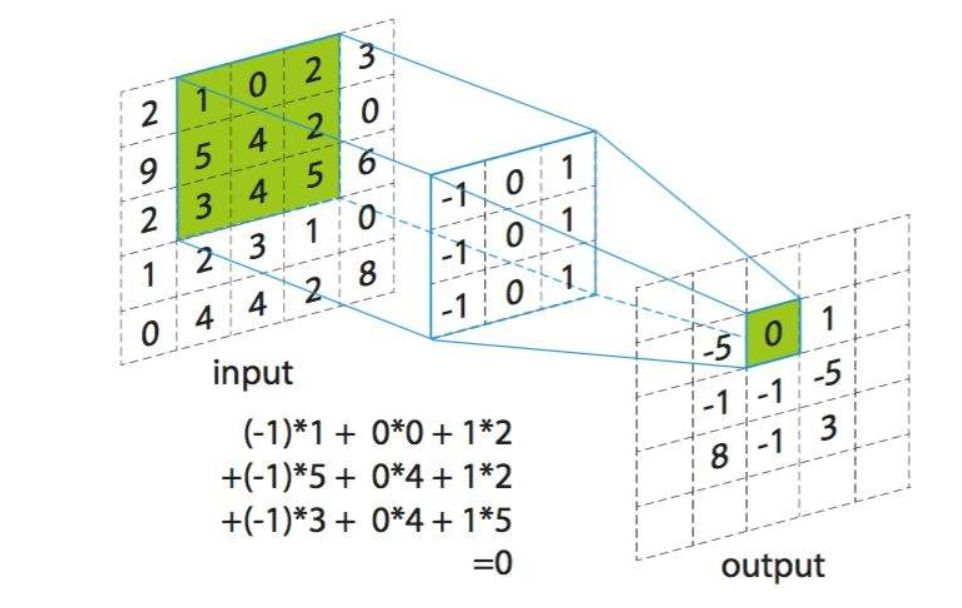
Convolution:在这个博客中,我们谈论的卷积并不是实际意义中的卷积,而是神经网络中的卷积。小伙伴们可能会有疑问,两个卷积有区别吗?学过信号处理或者图像处理的小伙伴们应该很熟悉,卷积是要首先将核翻转180°,然后再应用于信号或者图像上,而相关则不需要翻转。因此神经网络中的卷积实际上是一种相关操作。