原理解读
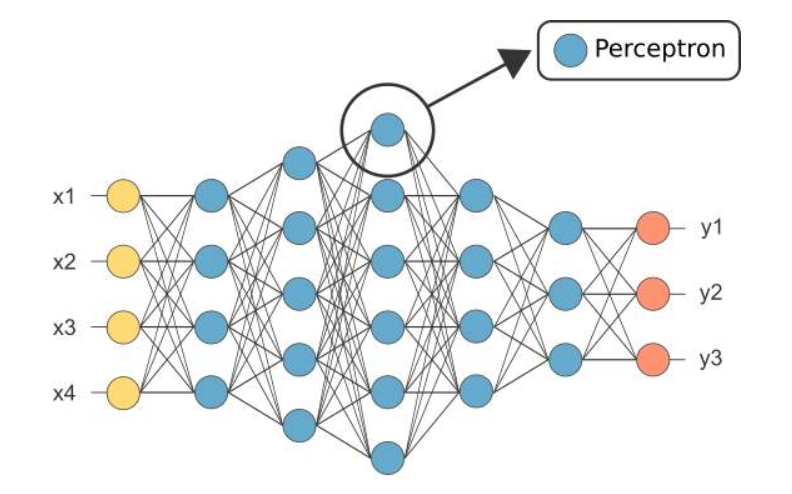
MLP(Multi-Layer Perceptron):多层感知机**本质上是一种全连接的深度神经网络(DNN)**,感知机只有一层功能神经元进行学习和训练,其能力非常有限,难以解决非线性可分的问题。为了解决这个问题,需要考虑使用多层神经元进行学习。
MLP(Multi-Layer Perceptron):多层感知机**本质上是一种全连接的深度神经网络(DNN)**,感知机只有一层功能神经元进行学习和训练,其能力非常有限,难以解决非线性可分的问题。为了解决这个问题,需要考虑使用多层神经元进行学习。
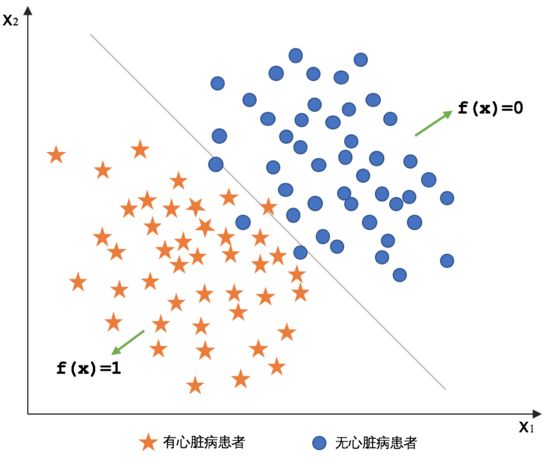
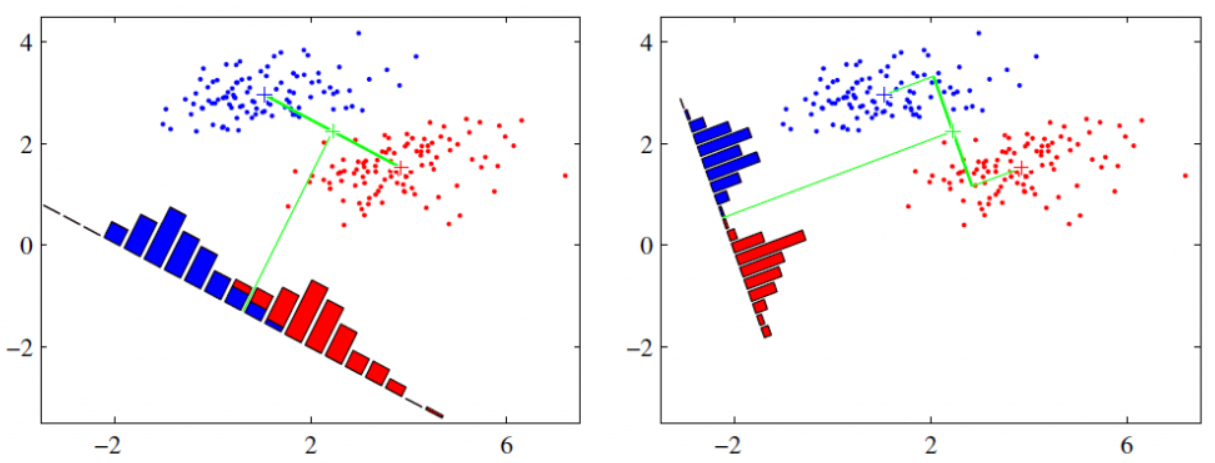
逻辑回归(Logistics Regression):是一种广义线性回归,都具有 w’x+b,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w’x+b作为因变量,即y =w’x+b,而logistic回归则通过函数g将w’x+b对应一个隐状态p,p =g(w’x+b),然后根据p 与1-p的大小决定因变量的值。如果g是logistic函数,就是logistic回归。

朴素贝叶斯:基于贝叶斯定理,采用了属性条件独立性假设,对已知类别,假设所有属性相互独立,也就是假设每个属性独立地对分类结果发生影响。发源于古典数学理论,而且所需估计的参数很少,算法也较为简单,但是正是因为其假设属性之间相互独立,因此在实际应用中往往是不成立的,所以给模型的正确性带来了一定的影响。

决策树(Decision Tree):是在已知各种情况发生概率的基础上,直观运用概率分析的一种图解法。决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
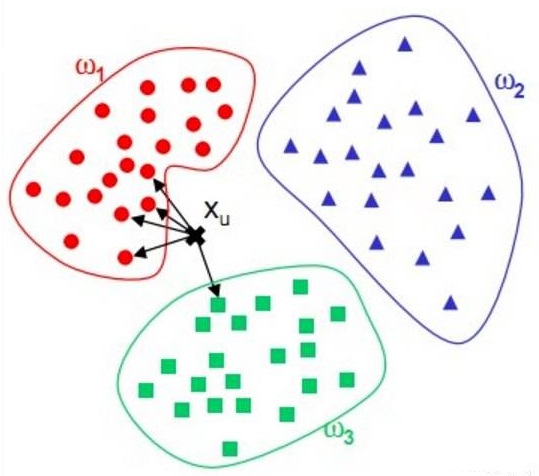
KNN(K Nearest Neighbor):又称K近邻,是一种基本分类方法,给定测试实例,基于某种距离度量找出训练集中与其最靠近的k个实例点,然后基于这k个最近邻的信息使用投票法,即选择这k个实例中出现最多的标记类别作为分类结果。
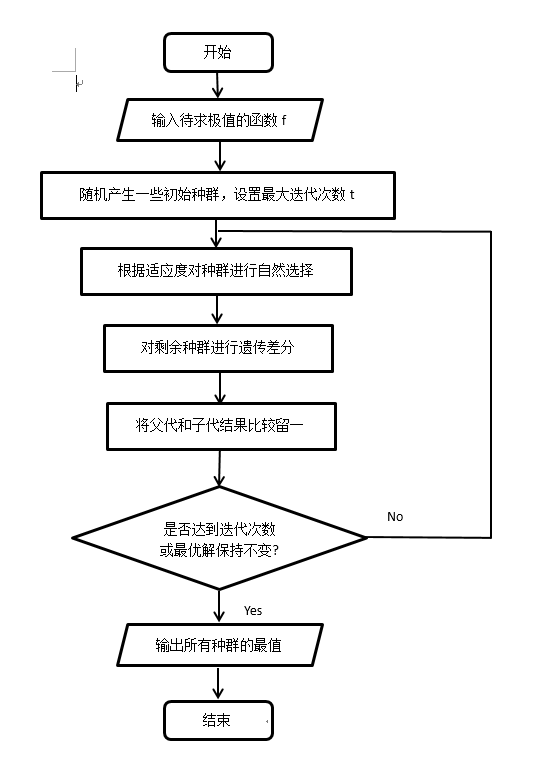
DE(Differential Evolution Algorithm):是一种高效的全局优化算法。它也是基于群体的启发式搜索算法,群中的每个个体对应一个解向量。差分进化算法的进化流程则与遗传算法非常类似,都包括变异、杂交和选择操作,但这些操作的具体定义与遗传算法有所不同。
1. 随机产生一些初始种群
2. 根据适应度对种群采用某种方式进行自然选择
3. 对选择剩余的种群进行差分遗传,产生新的种群
4. 对父代和子代留一处理,回到步骤2,直到满足某个终止条件
5. 此时剩余的是适应度较好的种群,比较可得该算法的最优解
代码中所用测试函数可以查看相关文档,测试函数(Test Function)
1 | clear;clc;close all; |
1 | function res=f(x) |
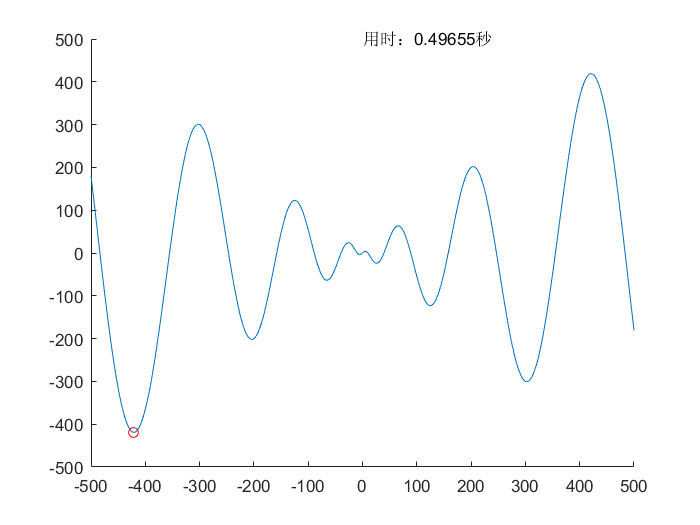
$$f(x)=x \cdot \sin(\sqrt{\lvert x \rvert}) \ , \ x \in [-500,500]$$
$$理论值:f(x)_{min}=f(-420.96874592006)=-418.982887272434$$
$$所求值:f(x)_{min}=f(-420.975929624477)=-418.982887272434$$
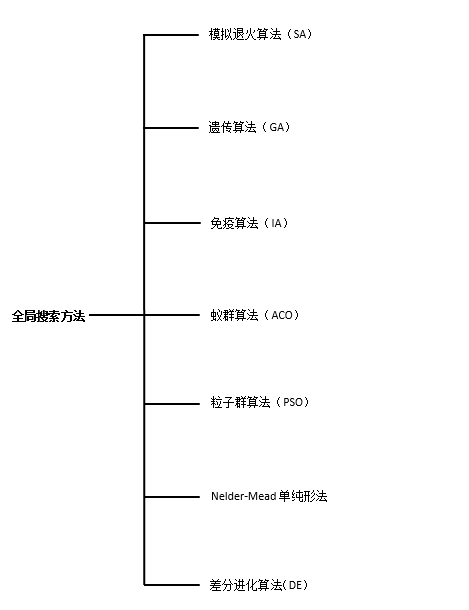
梯度方法,牛顿法,共轭梯度法,拟牛顿法等,能够从初始点出发,产生一个迭代序列。但是很多时候,往往只能收敛到局部极小点。因此为了保证算法能够收敛到全局最小点,需要借助于全局搜索算法来实现。
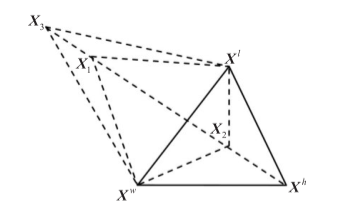
Nelder-Mead:单纯形法秉承保证每一次迭代比前一次更优的基本思想,先找出一个基本可行解,看是否是最优解,若不是,则按照一定法则转换到另一改进后更优的基本可行解,再鉴别,若仍不是,则再转换,按此重复进行。因基本可行解的个数有限,故经有限次转换必能得出问题的最优解。
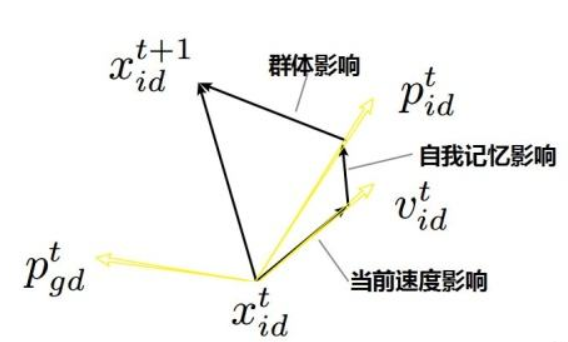
PSO(Particle Swarm Optimization):受到飞鸟集群活动的规律性启发,进而利用群体智能建立的一个简化模型。粒子群算法在对动物集群活动行为观察基础上,利用群体中的个体对信息的共享使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得最优解。