原理解读
DBSCAN(Density-Based Spatial Clustering Of Applications With Noise):DBSCAN需要两个参数,扫描半径 (eps)和最小包含点数(minPts)。 任选一个未被标记的点开始,找出与其距离在eps之内(包括eps)的所有附近点。如果附近点的数量大于等于minPts,则当前点与其附近点形成一个簇,并且出发点被标记。 然后递归,以相同的方法处理该簇内所有未被标记的点,从而对簇进行扩展。如果附近点的数量小于minPts,则该点被标记,不作扩展。如果簇充分地被扩展,即簇内的所有点被标记为已访问,然后用同样的算法去处理未被访问的点,直到所有的点都被标记。
核心思想
1. 挑选一个未标记样本,置为一类,搜索附近样本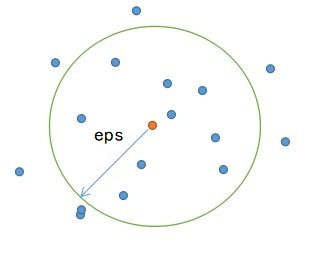
2. 如果附近样本数大于minPts,将这些样本归于该类,在此类中挑选未标记样本,继续搜索附近样本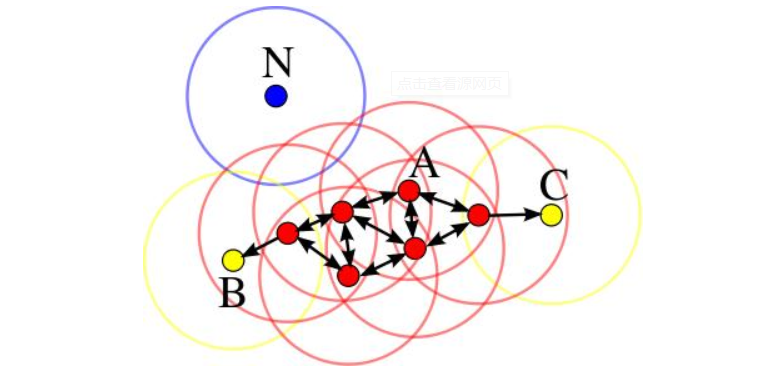
3. 重复步骤2,直到该类中所有样本都被标记
4. 重复步骤1,直到所有样本都被标记
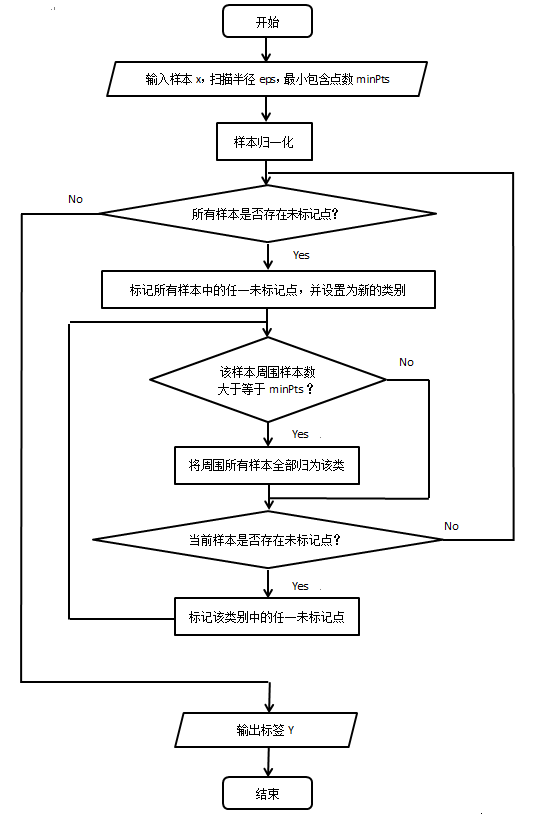
算法流程
代码实战
代码中所用数据集可以查看相关文档,数据集(Data Set)
DBSCAN_main.m
1 | clear;clc;close all; |
DBSCAN_classify.m
1 | function [y,color_bar]=DBSCAN_classify(x_scale,sample_num,eps,minpts) |
DBSCAN_display.m
1 | function DBSCAN_display(x,y,color_bar,sample_num) |
实验结果
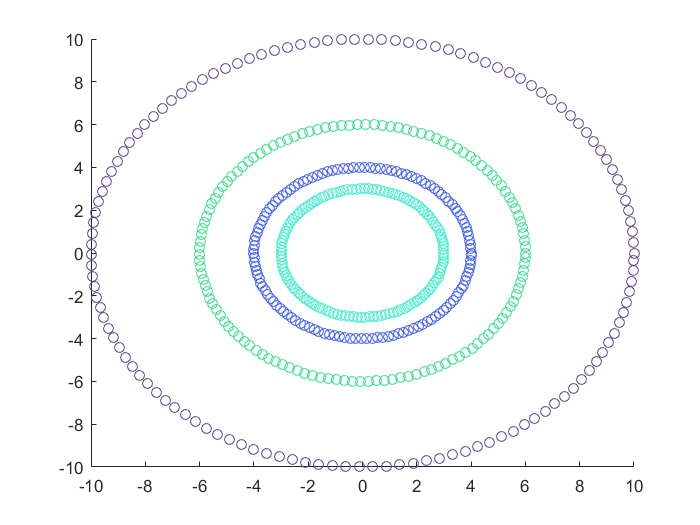
性能比较
- 优点:
- 算法简单,容易理解
- 不依赖初始数据点的选择
- 可以完成任意形状的聚类
- 缺点:
- 对噪声数据敏感
- 需要在测试前确定eps和minPts
- 不适合数据集中密度差异较大的情况
- 对于高维数据,距离的度量并不是很好