原理解读
MDCA(Maximum Density Clustering Application):将基于密度的思想引入到划分聚类中,使用密度而不是初始质心作为考察簇归属情况的依据,能够自动确定簇数量并发现任意形状的簇。MDCA一般不保留噪声,因此也避免了由于阈值选择不当而造成大量对象丢弃情况。
核心思想
1.最大密度点:可用K近邻距离之和的倒数表示密度
$$\rho_{max}={ \rho_{x} | x \in C, \forall x_i \in C, \rho_(x) \ge \rho_(x_i) } \ , \ 其中C为数据集$$
2. 密度曲线:根据所有对象与x的欧式距离对数据集重新排序
$$S_{\rho_{max}}={x_1 , x_2 , \cdots , x_n | d(x,x_1) \leq d(x,x_2) \leq \cdots \leq d(x,x_n) }$$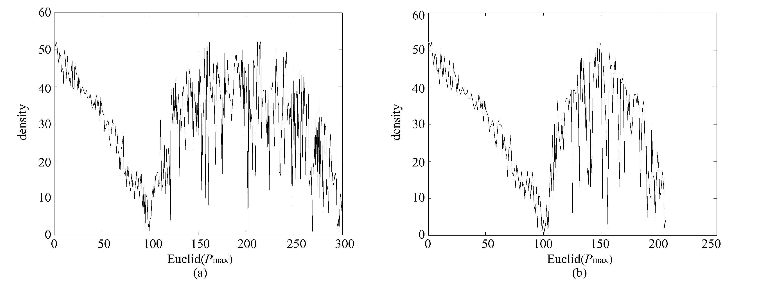
3. 将密度曲线中第一个谷值之前的数据归为一类,并将其剔除
4. 重复步骤1,2,3直到所有的点都在ρ0之下或者ρ0之上
5. 两个簇Ci和Cj,用最近样本距离作为簇间距离
$$d(c_i,c_j)=\underset{x_i \in C_i,x_j \in C_j}{\min}d(x_i,x_j)$$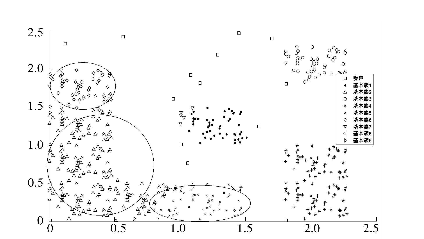
6. 根据簇间距离阈值d0,判断是否需要合并两类
算法流程
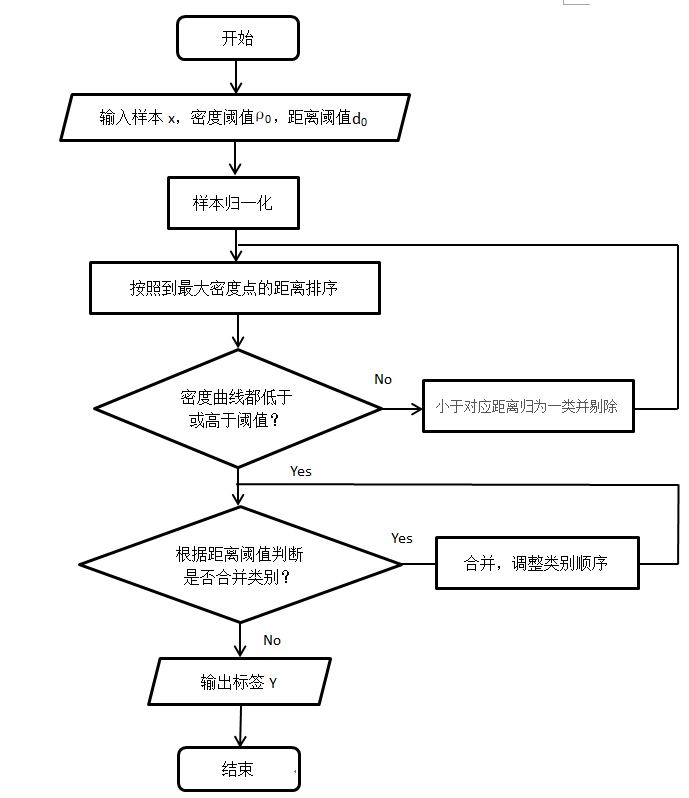
代码实战
代码中所用数据集可以查看相关文档,数据集(Data Set)
MDCA_main.m
1 | clear;clc;close all; |
MDCA_classify.m
1 | function [y,class_num]=MDCA_classify(x_scale,sample_num,k,density_min,distance_min) |
MDCA_findclass.m
1 | function [y,class_num]=MDCA_findclass(y,p,distance,density_min,class_num) |
MDCA_display.m
1 | function MDCA_display(x,y,sample_num,class_num) |
实验结果
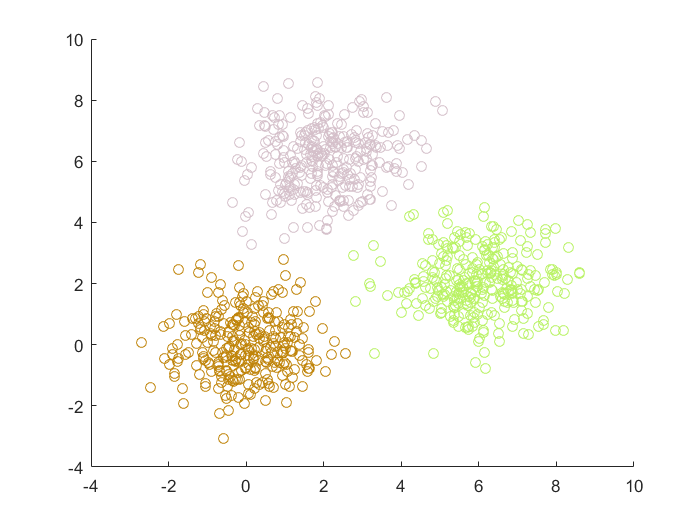
性能比较
- 优点:
- 对噪声数据不敏感
- 不依赖初始数据点的选择
- 可以完成任意形状的聚类
- 缺点:
- 算法复杂,分类速度较慢
- 需要在测试前确定密度阈值
- 对于高维数据,距离的度量并不是很好
- 不适合数据集密度差异较大或整体密度基本相同的情况